




 本文介绍了使用深度学习解决单个人脸图像表观年龄估计的问题,提出了名为DEX的深度期望方法。通过VGG-16架构的卷积神经网络,结合IMDB-WIKI数据集(包含524,230张名人图像)进行预训练和微调。DEX将年龄回归问题转化为深度分类,利用softmax期望值细化提高预测准确性。在ChaLearn LAP2015挑战中,DEX表现出色,成为表观年龄估计的领先方法。
本文介绍了使用深度学习解决单个人脸图像表观年龄估计的问题,提出了名为DEX的深度期望方法。通过VGG-16架构的卷积神经网络,结合IMDB-WIKI数据集(包含524,230张名人图像)进行预训练和微调。DEX将年龄回归问题转化为深度分类,利用softmax期望值细化提高预测准确性。在ChaLearn LAP2015挑战中,DEX表现出色,成为表观年龄估计的领先方法。
原文:DEX: Deep EXpectation of apparent age from a single image
摘要
本文通过深度学习解决了静态人脸图像中表观年龄的估计问题。该卷积神经网络 (CNN) 使用 VGG-16 架构,并在 ImageNet 上进行了预训练以进行图像分类。此外,由于表观年龄注释图像数量有限,该文章探索了使用具有可用年龄的互联网爬虫人脸图像进行微调的好处,并公开了从 IMDB 和维基百科中抓取了的 50 万张名人图片。这是迄今为止最大的年龄预测公共数据集。作者将年龄回归问题作为深度分类问题,然后是 softmax 期望值细化,并展示了对 CNN 直接回归训练的改进效果。该文章提出的表观年龄的深度预测 (DEX) 方法,首先检测测试图像中的人脸,然后提取使用裁剪人像在 20 个 CNN 网络训练模型的预测结果。DEX 的 CNN 使用爬虫得到的图像进行微调,然后又在已提供的带有表观年龄注释的图像上进行微调。该方法不使用确定的面部特征点。
1. 介绍
许多研究和几个大型数据集皆是关于单个人脸图像的 (生物、真实) 年龄估计。相比之下,对表观年龄的估计,即其他人所感知的年龄,仍处于起步阶段。ChaLearn LAP 2015 的组织者提供了迄今为止已知的最大的具有表观年龄注释的图像数据集之一 (此处称为 LAP 数据集) 以进行计算机视觉社区的挑战赛。
这项工作的目标是使用深度学习来研究单张人脸图像的表观年龄估计。本文方法的选择受到近年来使用深度学习进行的图像分类或对象检测等领域进展的影响。

本文的卷积神经网络 (CNN) 使用 VGG-16 架构,并在 ImageNet 上进行预训练以进行图像分类。通过该方式以学习图像并进行对象分类。如实验所示,这种表示不能很好地估计年龄。在具有表观年龄注释的训练图像上微调 CNN 是利用 CNN 表示能力并从中受益的必要步骤。由于具有表观年龄注释的人脸图像的稀缺性,作者从 IMDB 和维基百科网站抓取的 524,230 张人脸图像以构成 IMDB-WIKI 数据集。IMDB-WIKI 公开数据集的部分图像如图 1 所示。它是最大的用于生物年龄预测的公共数据集。年龄估计是一个回归问题,因为年龄是来自一个连续范围的值。与回归方法不同,作者选择训练 CNN 进行分类,其中将年龄值四舍五入为范围从 0 到 100 的 101 个年龄标签。通过将年龄回归视为深度分类问题,然后进行 softmax 期望值细化,文章得到了比直接训练回归模型更好的效果。
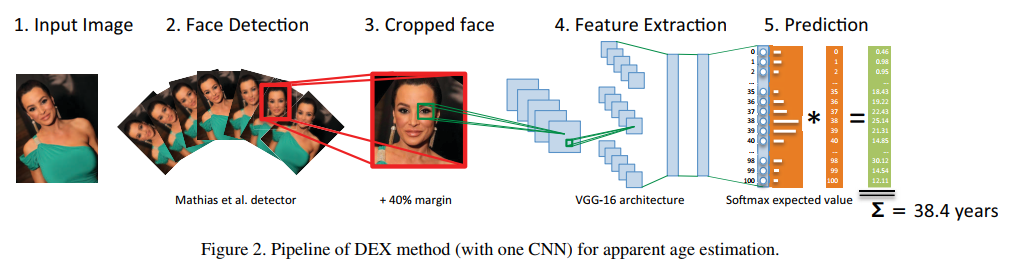
本文提出的表观年龄的深度预测 (DEX) 方法如图 2 所示,首先检测图像中的人脸,然后使用裁剪后的人像在 20 个 CNN 训练以提取特征进行预测。DEX 在 ImageNet 上进行了预训练,在 IMDB-WIKI 和 LAP 数据集上进行了微调。
该文章贡献如下:
1. IMDB-WIKI 数据集,最大的用于生物年龄预测的数据集;
2. 利用了深度分类和期望值细化的新回归公式;
3. DEX 系统,2015 年 LAP 表观年龄估计挑战赛的获胜者。
2. 提出的方法 (DEX)
文章提出的深度期望 (DEX) 方法遵循图 2 中的流程。接下来细述相关的每个步骤和多个 CNN 的最终整合。
2.1. 人脸检测
对于训练和测试图像,该文章运行现成的人脸检测器以获取人脸位置。
为了对齐人脸,作者不仅在原始图像上运行人脸检测器,还在 -60° 和 60° 之间以 5° 为步长的所有旋转版本上运行人脸检测器。 由于一些训练图像颠倒或旋转了 90°,作者还在 -90°、90° 和 180° 处运行检测器。由于计算资源有限只使用了这组离散的旋转图像。 最终选取检测分数最高的人脸,并相应地将其旋转到正面位置。
对于极少数图像 (<0.2%),人脸检测器无法找到人脸。在这些情况下只取整个图像。在最终的 LAP 测试集中,这仅适用于 1 个图像。
作者对人脸大小范围进行扩展,即在左右两侧各取其宽度的 40%,上下取其高度的 40%。添加此扩充有助于提高预测准确性。如果人脸已经覆盖了图像的大部分,只需填充边界处的最后一个像素。这可确保面部始终位于图像的同一位置。
生成的图像最终被压缩到 256 × 256 像素以用作深度卷积网络的输入。
2.2. 面部表观年龄估计
通过应用前一阶段检测到的人脸训练深度卷积神经网络来进行表观年龄预测。作者使用 VGG-16 架构,该架构在 ImageNet 挑战中拥有出色的结果。
2.2.1 使用CNN进行深度学习
该文章的所有 CNN 皆为 VGG-16 架构,并在 ImageNet 数据集上预训练以进行图像分类。然后在 IMDB-WIKI 数据集上对 CNN 进行微调。在进行回归训练时,输出层更改为具有回归年龄的单个神经元。在进行分类训练时,输出层为 101 个输出神经元,对应于从 0 到 100 的自然数,用于年龄类别标签的离散化。
2.2.2 期望值
年龄估计可以被视为分段回归,或者,作为具有多个离散值标签的离散分类。 类的数量越多,回归信号的离散化误差就越小。 在文章的例子中,这是一个一维回归问题,年龄是从连续信号 ([0,100]) 中采样的。
可以通过大量增加类的数量来改进回归年龄的分类公式,从而更好地逼近信号并通过组合神经元输出来恢复信号。 增加类的数量需要每个类有足够的训练样本,并且增加了训练年龄分布过拟合和由于缺乏样本或不平衡而导致样本训练不当的机会。经过多次初步实验,作者决定使用 101 个年龄段。为了提高预测的准确性,如图 2 所示,最终计算了 softmax 期望值 E:
其中 O = {0, 1, ..., 100} 是101维输出层,表示 softmax 输出概率 ,
是每个类 i 对应的离散年龄。
2.2.3 CNNs的集合
经过使用 IMDB-WIKI 数据集进行微调后,作者在 ChaLearn LAP 数据集的 20 个不同的部分数据上进行了进一步的微调。 对于每部分数据,使用 90% 的图像进行训练,10% 的图像用于验证。分别为每个年龄随机选择划分,即训练中的年龄分布始终相同。然后在 ChaLearn 数据集的增强版本上训练 20 个网络,作者为每个图像添加 10 个增强的版本。每个增强随机将图像旋转 -10° 到 10°,将其转换为 -10% 到 10% 的大小,即将其缩放为原始大小的 0.9 到 1.1。 作者在将数据拆分为训练集和验证集后进行扩充,以确保两个集之间没有重叠。然后训练每个网络,并在验证集上选择具有最佳性能的权重。
最终的预测结果为 20 个网络集合的平均值,这些网络分别在不同划分的数据上进行了训练。
3. 实验
本节首先介绍实验中使用的数据集和评估方法。然后提供 DEX 方法的细节,描述实验设置并讨论结果。
3.1. 数据集和评估协议
3.1.1 IMDB-WIKI 年龄预测数据集
为了获得良好的性能,通常大型 CNN 架构需要大型训练数据集。由于公开的人脸图像数据集通常是中小型的,很少超过数万张图像,而且通常没有年龄信息。为此,作者获取了IMDB网站上列出的最受欢迎的 100,000 名演员的列表,并 (自动) 从他们的个人资料出生日期、图像和注释中爬取。删除了没有时间戳(拍摄照片的日期)的图像,以及具有多个高分人脸检测的图像 (参见第 2.1 节) 。通过假设具有单人脸图像显示的可能为该演员,并且具有正确的时间戳和出生日期,为每个这样的图像分配生物 (真实) 年龄。当然,不能保证指定年龄信息的准确性。除了错误的时间戳,许多图像都是电影的剧照,包含可能延长的电影制作时间。作者最终从 IMDB 获得了 461,871 张名人的人脸图像。

从维基百科中,作者抓取了所有个人资料图像,并根据适用于 IMDB 图像的相同标准对它们进行过滤后得到了 62,359 张图像。 表 1 中总结了该文章公开的IMDB-WIKI数据集 (共有 524,230 张带有爬取年龄信息的人脸图像) 。由于一些图像 (尤其是来自 IMDB) 包含几个人,文章只使用第二人脸检测值低于阈值的照片。为了让网络对所有年龄段的人都具有同等的区分,作者均衡了年龄分布,即随机忽略了一些最常见年龄的图像。最终为训练 CNN 留下了 260,282 张图像。
3.1.2 表观年龄估计的 LAP 数据集
ChaLearn LAP 数据集由 4699 张人脸图像组成,这些图像使用两个基于 Web 的应用程序共同标记了年龄。每个标签是至少 10 个独立用户的平均意见。因此,还为每个年龄标签提供了一个标准差 σ。LAP 数据集中 2476 张图像用于训练,1136 张图像用于验证,1087 张图像用于测试。LAP 数据集的三组图像中的年龄分布相同。该数据集很好地覆盖了 20 到 40 岁的年龄区间,而对于 [0,15] 和 [65,100] 区间,每个年龄样本的数量都很少。
3.1.3 评估方法
本文使用 MAE 和 ChaLearn LAP 挑战定义的 ϵ-error 来评估结果。
标准平均绝对误差 (MAE) 计算为估计年龄和真实年龄之间绝对误差的平均值。该误差并未捕获真实年龄标记的不确定性。而 ϵ-error 涵盖了这样的方面。
ϵ-error,LAP 数据集图像用多个用户投出的年龄选票的平均值和标准差 σ 进行注释。LAP 挑战评估采用正态分布拟合每个图像的平均 μ 和标准偏差 σ:
3.2. 实施细则
项目是用 Matlab 编写的,该 CNN 使用 Caffe 框架在 Nvidia Tesla K40C GPU 上进行训练。面部检测在 Sun Grid Engine 上并行运行,这对于 IMDB 和 Wikipedia 图像至关重要。
在 IMDB 和维基百科图像上训练网络大约需要 5 天。在 ChaLearn 数据集上微调单个网络大约需要 3 小时。在每次调整时测试人脸检测大约需要 1 秒。每个图像和网络的特征提取需要 200 毫秒。
3.3. 验证结果
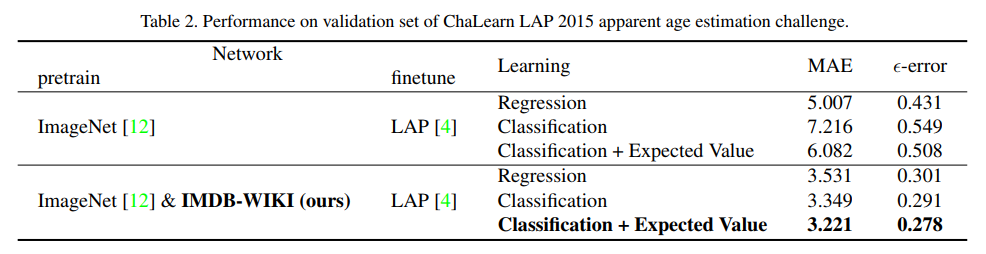
在实验中,可以注意到计算 softmax 期望值的分类训练的网络相交以下方法效果更好: a) 回归,b) 使用回归 (即 SVR) 进行 CNN 特征学习,或 c) 仅采用概率最高的神经元的年龄。表 2 中报告了不同设置和单个 CNN 的 MAE 和 ϵ-error。可以注意到对 IMDB-WIKI 人脸图像的额外训练带来了巨大的改进 (MAE 减少了 2 到 4) 。这符合预期,因为网络学习了一个强大的年龄估计表示,这与 LAP 数据集上的表观年龄估计目标相关。在 LAP 数据集的验证集上直接训练网络进行回归导致 0.301 错误 (3.531 MAE) 。通过更改为具有 101 个输出神经元 {0, 1, ..., 100} 对应于舍入年龄的分类公式,作者改进为 0.291 的 ϵ-error (3.349 MAE) 。通过 softmax 期望值细化,在 LAP 验证集上获得了0.278 误差和 3.221 MAE的最佳结果。

定性结果 (如图3所示) 表明,本文提出的解决方案能够像人类一样预测自然场景下的人脸的表观年龄。这部分是通过学习大型 IMDB-WIKI 数据集中自然场景人脸图像实现的。

图 4 中展示了许多人脸图像,其中使用单个CNN的DEX方法失败了。主要原因有:1) 检测阶段失败——要么没有检测到人脸,要么选择了错误的人脸(背景人脸);2) 极端条件和/或损坏,例如深色图像、眼镜、旧照片。
3.4. Looking at people (LAP) 挑战
LAP 表观年龄估计挑战包括两个阶段:开发 (验证) 和测试。
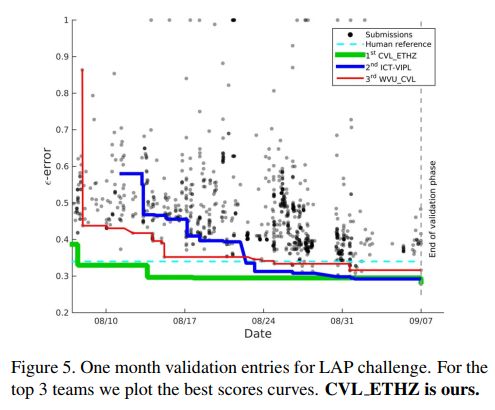
3.4.1 开发阶段
在开发阶段,发布了 LAP 数据集的训练和验证图像。 训练图像具有明显的年龄标签,而验证标签直到第二阶段开始才保持未知。团队将验证图像上的结果提交给服务器以获得他们的性能分数。验证图像记分牌的演变如图 5 所示。为了绘制上述记分牌,作者从比赛网站上抓取了分数。可以很容易地注意到,结果的质量随着时间的推移平均提高。
3.4.2 测试阶段
在测试阶段,发布了验证标签,并授予了对测试图像的访问权限,但没有测试标签。团队被邀请将他们的测试图像结果提交给比赛服务器。直到组织者宣布测试阶段后的最终排名,分数才为人所知。 我们的结果是使用 DEX 与 20 个 CNN 的完整集成、分类预测和期望值细化获得的。
3.4.3 最终排名
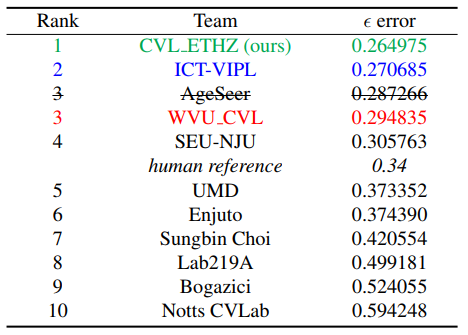
ChaLearn LAP表观年龄估计挑战的最终排名与在线验证阶段的记分牌演变相匹配 (见表 3) 。最好的4种方法低于 0.34 ϵ-error,这是组织者在开发阶段报告的人类参考表现。
值得注意的是,作者是前 6 名中唯一没有使用面部标志的团队。即该方法的性能可能通过使用特征点标注来进一步提高。
4. 结论
本文作者处理了静态人脸图像中表观年龄的估计。提出的深度期望 (DEX) 方法使用在 ImageNet 上预训练的 VGG-16 卷积神经网络 (CNN) 架构。同时,抓取了互联网上可用年龄的人脸图像,以创建迄今为止已知的最大的此类公共数据集并用于 CNN 预训练。此外,该 CNN 使用表观的年龄标记的人脸图像进行了微调。 该文章将年龄回归问题作为深度分类问题提出,然后使用 softmax 期望值细化,并展示了对 CNN 直接回归训练的改进。DEX 在裁剪人脸图像上集成了 20 个网络的预测。DEX 没有明确使用面部特征标记。 该方法在表观年龄估计方面赢得了 ChaLearn LAP 2015 挑战,取得了优于作为参考的人类预测水平。


















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









