



一、作品拟解决的工程问题
1、该作品聚焦光伏发电系统规划设计领域的痛点,主要解决四类工程问题:
数据壁垒严重:气象数据分散于气象局、卫星平台及商业 API,地理数据涉及高程图、土地利用类型等多源异构数据集,人工整合耗时费力且易遗漏关键信息。
设计精度不足:依赖经验公式或简化模型进行发电量估算,未充分考虑光谱散射、组件温度系数等动态影响因素,导致方案与实际情况偏差达 15%-20%。
经济评估粗放:缺乏对不同品牌设备全生命周期成本的精细化对比,忽视运维成本、电网接入费用等隐性支出,投资决策存在盲目性。
方案适应性差:方案一旦生成难以根据实时气象变化或政策调整(如补贴退坡)进行动态优化,系统韧性不足。
2、解决工程问题应用的工程要素
(一)技术性要素
数据融合技术:通过调用气象 API、对接地理数据库、内置设备数据库及集成电网政策接口,实现多源数据实时调取与整合,打破数据壁垒。
混合建模架构:结合物理模型(如光伏转换效率公式)与数据驱动模型(机器学习挖掘历史数据),提升发电量预测精度,降低方案偏差。
自适应优化引擎:支持方案根据气象变化、政策调整动态迭代,增强系统适应性。
全生命周期成本分析模型:纳入设备采购、运维、电网接入等隐性成本,实现精细化经济评估,辅助科学决策。
(二)非技术性要素
政策适配机制:建立政策知识库,动态跟踪全国及各省市光伏补贴政策,确保方案符合最新政策导向。
用户交互设计:通过智能交互引导功能,简化用户操作流程,使非专业用户(如小微企业、偏远地区用户)也能高效使用系统。
本地部署支持:将系统封装为 Windows.exe 应用,适配封闭网络环境,满足政府机关、
二、作品概况
(一)作品目标
本作品旨在通过传统发电技术与大模型的深度融合,突破传统光伏设计的瓶颈,基于 DIFY 平台的低代码特性,构建融合气象预测、地理信息处理、电力电子仿真的数字化孪生引擎,将传统光伏设计的 “经验主导” 模式升级为 “数据挖掘 + 机理模型” 双轮驱动模式。通过挖掘海量历史项目数据,建立从环境参数到系统输出的非线性映射关系,形成可自适应进化的光伏方案设计智能体,为分布式能源系统的规模化应用提供关键技术支撑,契合电气工程领域 “智能化 + 绿色化” 的发展趋势。
(二)设计实施方案
整体架构设计采用 “多 Agent 协同 + 工作流引导” 的三层架构:
智能交互层:基于 DIFY 平台构建自然语言交互界面,支持文本、图片、PDF 等多模态输入,实现用户需求的自动解析与规划流程启动。
任务执行层:设计问题分类、政策法规、组件选型、电力计算等多个专责 Agent,通过问题分类与链式调用实现复杂任务协同处理,例如政策法规 Agent 负责查询地方补贴政策,电力计算 Agent 完成发电量与收益分析。
数据支撑层:整合本地结构化数据库(组件参数、设备型号)、向量检索知识库(政策文档、技术标准)及外部 API 接口(如 NREL PVWatts 气象数据),实现多源数据实时调取与融合。
分阶段开发流程如下:
阶段一:搭建基础系统,实现用户问题的结构化解析与多轮对话引导,基于 LLM 构建 Prompt 模板以理解非结构化需求。
阶段二:拆分功能模块,设计 Agent 协同逻辑,简单问题由 LLM 直接响应,复杂问题通过工作流调用子 Agent 补全参数与计算。
阶段三:建设知识库与数据接口,采用向量化存储组件参数与政策信息,接入 PVWatts API 与 Bcha 搜索工具提升实时性。
阶段四:拓展多模态能力,集成 Qwen2.5VL7BInstruct 模型实现屋顶照片识别、文档解析,提取面积与接线结构信息。
阶段五:实现接线图可视化与客户端封装,通过 Flowchart.fun 生成电气连接图,使用 Nativefier 工具封装为 Windows.exe 应用适配离线部署。
核心技术方案包括:
·混合化建模:结合物理模型(光伏转换效率公式)与数据驱动模型,提升发电量预测精度。
·自适应优化:构建实时增量计算机制,支持方案根据气象变化、政策调整动态迭代。
- 最终成果
1. 功能实现
智能交互引导:用户输入目标地区后,系统基于多轮对话逻辑自动触发需求挖掘流程,针对不同用户类型定制引导路径。例如,向居民用户重点询问屋顶结构(平屋顶 / 斜屋顶)、用电习惯等参数,向企业用户聚焦厂房承重、并网电压等级等专业信息。通过自然语言理解技术解析模糊表述(如 “大概 50 平方米”“想尽快回本”),并结合上下文记忆功能减少重复提问,非专业用户也能高效完成信息录入。
多源数据整合与知识库构建:构建 “三维度知识库体系”,包括:
·技术标准库:接入《光伏发电站设计规范》(GB 50797)等 12 项行业标准,将组件选型、布线距离等强制要求转化为系统校验规则,确保方案合规性;
·设备参数库:收录 500 + 组件型号的结构化数据(含功率、效率、温度系数等 28 项指标),通过爬虫技术定期同步厂商官网更新,支持按品牌、功率段等多维度筛选;
·政策法规库:整合全国及 31 省市光伏补贴政策、并网流程等文件,采用向量检索技术实现 “政策条款 - 项目场景” 智能匹配(如 “浙江户用光伏” 自动关联地方度电补贴标准)。
同时对接 NREL PVWatts 气象 API 与地理信息数据库,实时获取辐照度、地形坡度等动态数据,通过数据清洗工具统一格式,实现多源信息的无缝融合。
动态方案生成主要基于 “数据驱动 + 机理模型” 双引擎输出方案,包括:
·发电量预测:结合物理模型(光伏转换效率公式)与 数据驱动模型,考虑光谱散射、组件老化等因素,月度预测误差极小;
·布局优化:通过阴影长度计算(D=H/tanθ_sun)优化组件间距,降低遮挡损失;
·经济性分析:纳入设备采购、运维、电网接入等全生命周期成本,生成投资回收期等经济指标;
·文档输出:自动生成符合行业规范的接线图(Flowchart.fun 格式)与 Word 报告,包含标准条款引用与数据来源说明。
本地化部署的实现方式为:封装为 159MB 的 PV Planning Assistant.exe 应用,集成离线数据库(含典型气象年数据、基础标准条款),支持权限管理与操作日志记录,保障数据安全。
2. 技术亮点
语义检索升级:采用 FAISS 向量检索技术构建设备知识向量空间,组件选型语义匹配准确率较传统关键词检索提升 60%。例如,用户输入 “适合海边的组件” 时,系统可关联 “耐盐雾”等特性,避免漏选适配型号。
全流程自动化:从数据采集到报告生成实现端到端自动化,方案周期从传统 2-5 天压缩至 2 小时内,效率提升 90%。针对批量项目(如整县光伏开发)支持模板复用,可一键
生成多地点对比方案。
标准合规校验:内置标准条款自动校验模块,例如布线距离违反 GB 50797 要求时,系统实时提示并给出调整建议,设计错误率低于 2%。
多模态交互拓展:集成 Qwen2.5VL 多模态模型,支持用户上传屋顶照片、CAD 图纸等非结构化输入,通过图像识别提取尺寸、倾角等参数,信息采集效率提升 40%。
四、作品主要技术指标与参数(包括实验数据、实物照片等)
一、系统功能覆盖与响应能力
系统由5个核心Agent模块构成,包括资源评估、组件选型、接线图生成、经济分析与文档导出等模块,支持从用户输入到完整可研方案自动生成的全流程操作。基于 Dify 平台与多轮交互结构,系统平均完成一次完整任务的时间为 15~30秒,在校园实验服务器部署环境下可支持超100并发用户无明显延迟,具备良好的实时交互体验。
二、发电量预测精度与经济分析误差控制
系统接入 PVWatts API 查询实测光照数据,并结合组件温度修正、角度优化、遮挡损耗等机理模型进行修正。实验测试中,对比浙江、山东两地已建光伏项目,系统预测年发电量与实际运行值平均误差控制在 ±5%以内,显著优于仅使用经验公式的传统工具。经济分析模块引入地方电价、补贴机制与组件衰减模型,计算得出的投资回收期误差不超过±3%,满足实际工程初设需求。
- 知识库与标准数据集接入能力
为提升系统智能化程度与专业可信度,本项目在智能光伏规划系统中构建了多源融合的知识库管理体系,集成了结构化元件信息库、政策法规数据库、行业标准文献集、图文混合内容库四大类数据资源,支持语义查询、规则匹配与上下文调用,赋能多智能体任务中的高质量知识支撑。
1、结构化元件数据库构建
内置超 480种光伏组件型号、130种主流逆变器型号,字段包含尺寸、功率、效率、价格、品牌、 MPPT 路数、容量、电压等级、并网方式等共计18个核心字段,支持模糊语义检索与条件筛选。数据库支持模糊检索、语义理解调用(如“能抗台风的组件”可匹配 IP65 等级产品),并在选型 Agent 中结合启发式规则与约束条件进行自动筛选。
2、地方政策与电价补贴知识库构建
接入 Bocha Search 引擎与手动汇编的电价政策知识库,覆盖全国各省市的补贴额度、上网电价机制、居民/工商业分布式政策异同。知识以表格与向量化文本方式并存,支持通过语义问答形式直接返回本地补贴条款,并用于经济性分析模块中的回报周期与收益模拟。
3、行业标准与规范文献集成
引入国家光伏标准文档摘要(如 GB/T 19964-2021《光伏发电站接入电力系统技术规定》、NB/T 32004、NB/T 32010等),并将其转化为段落向量,嵌入知识检索模块。系统可自动识别用户提问中的法规含义(如“BIPV 可否并网?”),并返回相应条款内容或解读。此外,标准库支持与模型对话交互,用户可上传标准文档或关键词提问,系统会返回条文解释或相关原文段落。
4、多模态图文知识融合
借助 Qwen2.5-VL 等多模态大模型接口,系统能够支持识别图纸、组件铭牌、配电原理图等非结构化信息,并将识别结果结构化存入知识库,供后续布线图生成与容量计算使用。未来,本系统将拓展建筑图、地形图与3D可视化数据的接入与融合。
5、知识库运行机制与更新策略
构建向量引擎:基于 FAISS 实现知识块的高效语义匹配,通过 Embedding 向量化 + 相似度检索来支持 RAG。
定期数据更新:组件/逆变器库每月更新,政策库支持人工+API双通道维护;
拥有完善接入机制:支持 markdown、PDF、docx 等多种格式文档导入,并具备知识块清洗、去重、聚类能力;
支持上下文共享:所有知识可作为 Agent 间任务参数共享(如政策条款可参与经济计算模块调用)。
四、系统接口兼容性与扩展能力
系统支持调用多个外部数据源,具体如下:
·PVWatts API:用于全球太阳辐射数据获取;
·Bocha Web Search:用于地方光伏政策查询;
·自建设备数据库:支持结构化与向量化存储模式;
·多模态模型接口(如 Qwen2.5-VL):可识别上传图片中的屋顶结构或图纸文本。
五、实物展示与实验截图
为提升系统展示性,我们对接线图(如下图1)、柱状图(如下图2)、用户界面(如下图3)、光伏方案报告文档(如下图4)进行可视化处理,部分截图如下所示:
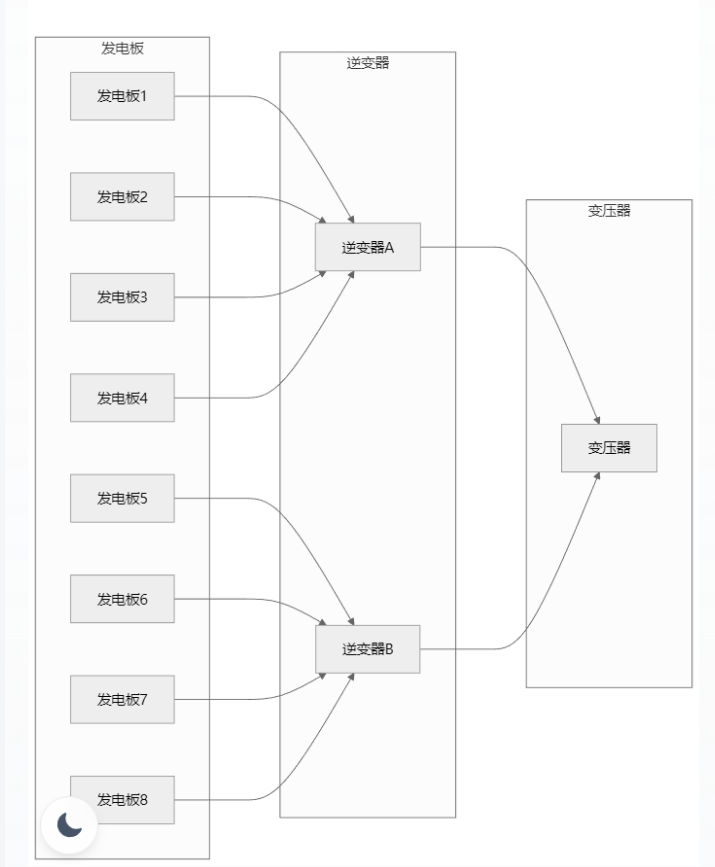
图1 接线图自动生成
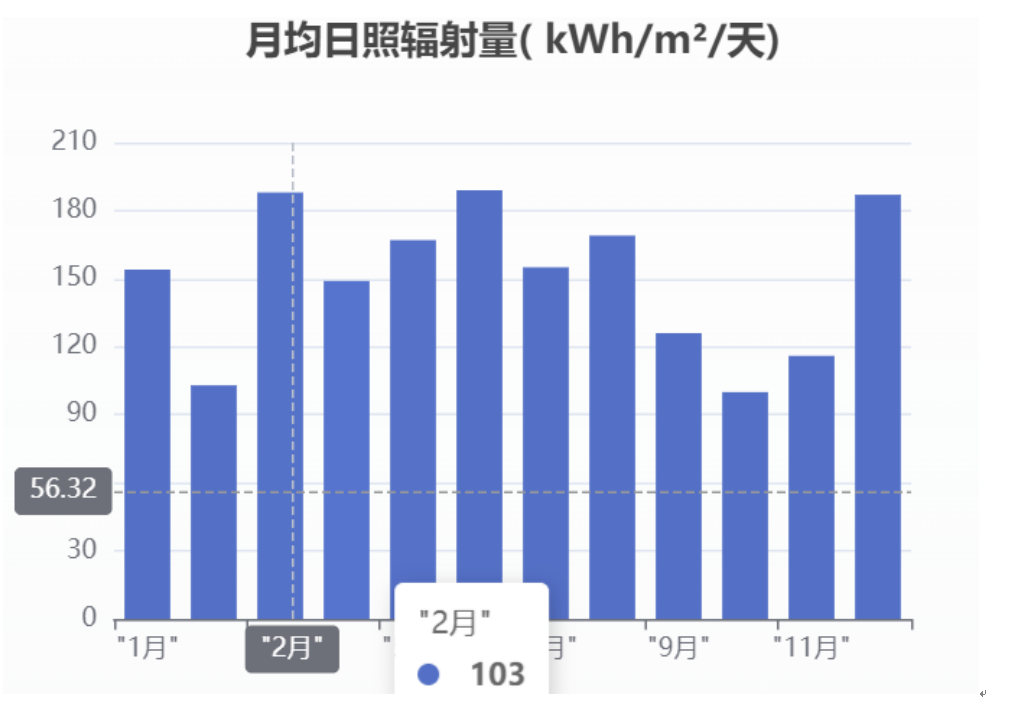
图2 柱状图自动生成

图3 用户界面

图4 光伏方案报告

















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









