




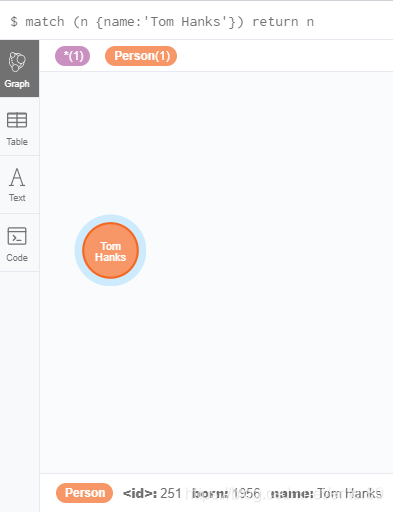
根据属性查询数据。查询name为Tom Hanks的节点。
match (n {name:'Tom Hanks'}) return n
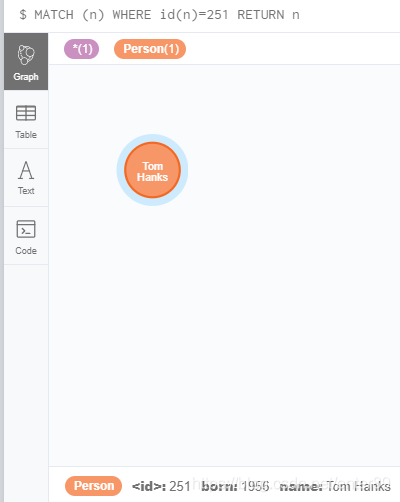
但是通过id匹配数据,不能像其它普通属性一样直接match
MATCH (n) WHERE id(n)=251 RETURN n
 本文探讨了在Neo4j图数据库中如何精确地使用属性进行数据查询,特别是针对name属性和id属性的查询方法。通过具体的Cypher查询语句示例,读者将学会如何有效地检索特定节点。
本文探讨了在Neo4j图数据库中如何精确地使用属性进行数据查询,特别是针对name属性和id属性的查询方法。通过具体的Cypher查询语句示例,读者将学会如何有效地检索特定节点。
根据属性查询数据。查询name为Tom Hanks的节点。
match (n {name:'Tom Hanks'}) return n
但是通过id匹配数据,不能像其它普通属性一样直接match
MATCH (n) WHERE id(n)=251 RETURN n
 2074
5197
4409
2074
5197
4409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























