



 本文介绍了一个基于Python2.7的百度云爬虫项目,通过MySQL数据库存储爬取的数据,并提供了详细的部署步骤。该项目能抓取百度云热门分享的资源信息。
本文介绍了一个基于Python2.7的百度云爬虫项目,通过MySQL数据库存储爬取的数据,并提供了详细的部署步骤。该项目能抓取百度云热门分享的资源信息。

今天浏览微信公众号,看到一篇关于Python爬虫的文章,很有意思,动手实现了一下作者的实验,下面是详细的实现步骤:
运行环境:
MySQL
Python2.7
MySQL-Python
创建数据库
创建名为’pan’的数据库,编码设为’utf-8’。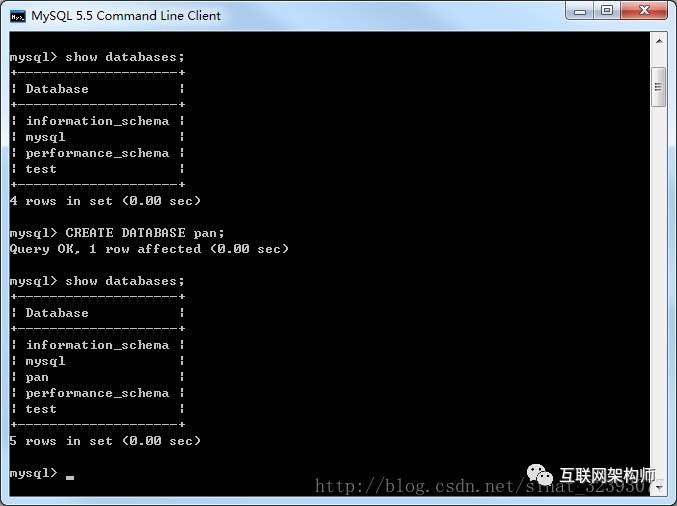
然后导入’pan.sql’,完成表的创建。
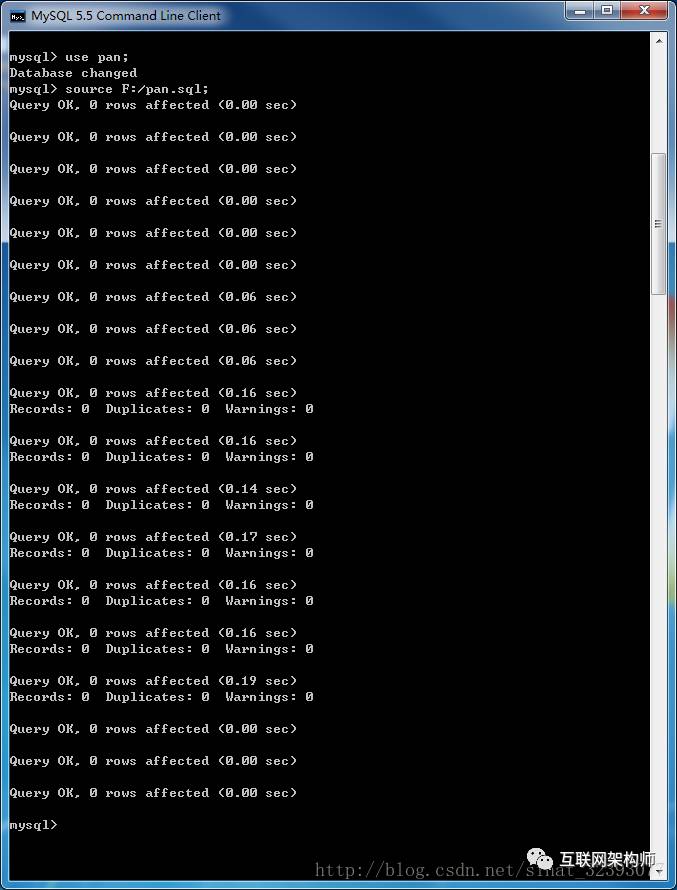
数据库里已经创建了需要用到的表。
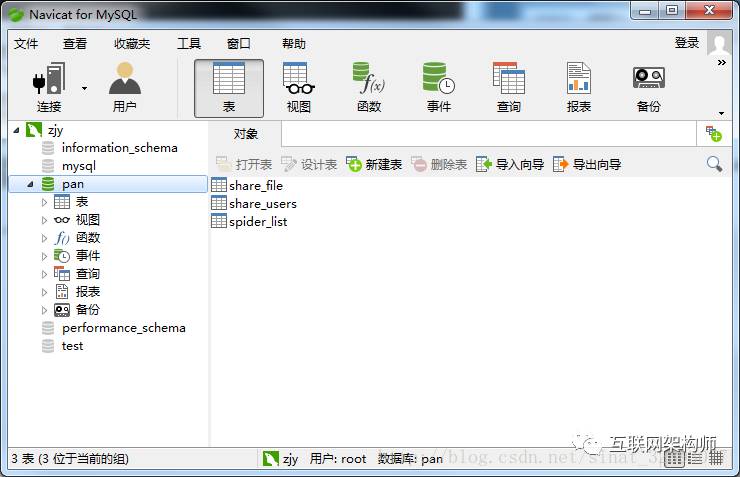
设置连接数据库的账号密码
打开‘bin/spider.py’,修改MySQL数据库账号密码相关信息。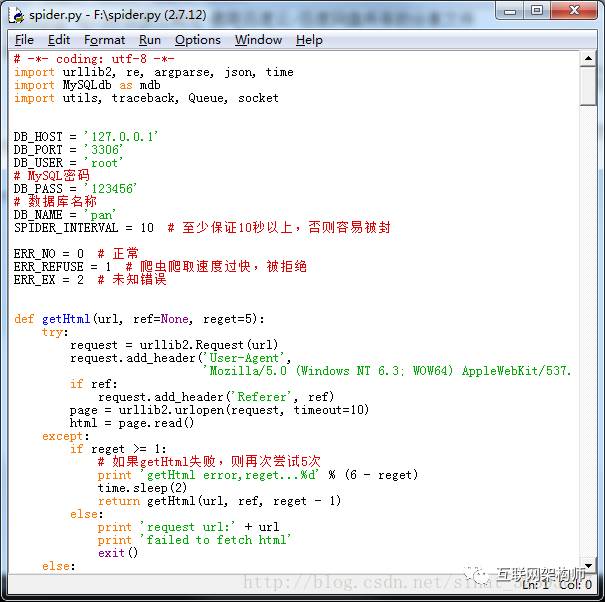
运行爬虫
如果你是第一次部署,需要运行下面的命令完成做种,也就是抓取百度云热门分享用户的相关信息:
python spider.py –seed-user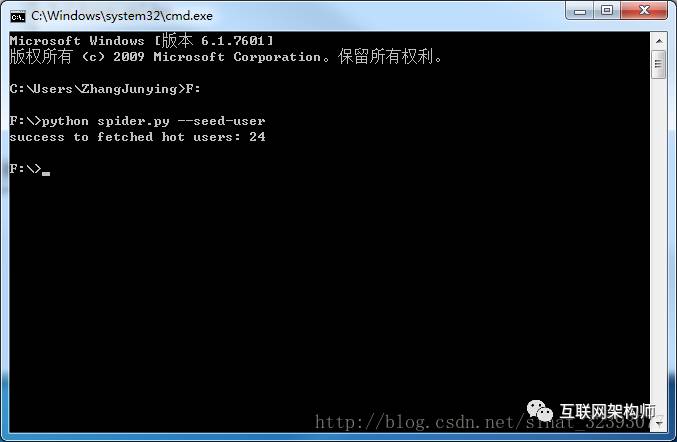
从上面的用户信息开始开始入手爬取数据,此时爬虫开始工作:
python spider.py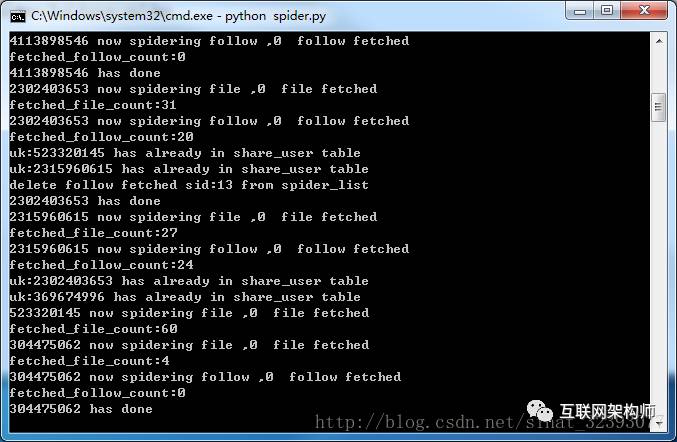
使用数据库保存的数据打开资源
打开数据库share_file表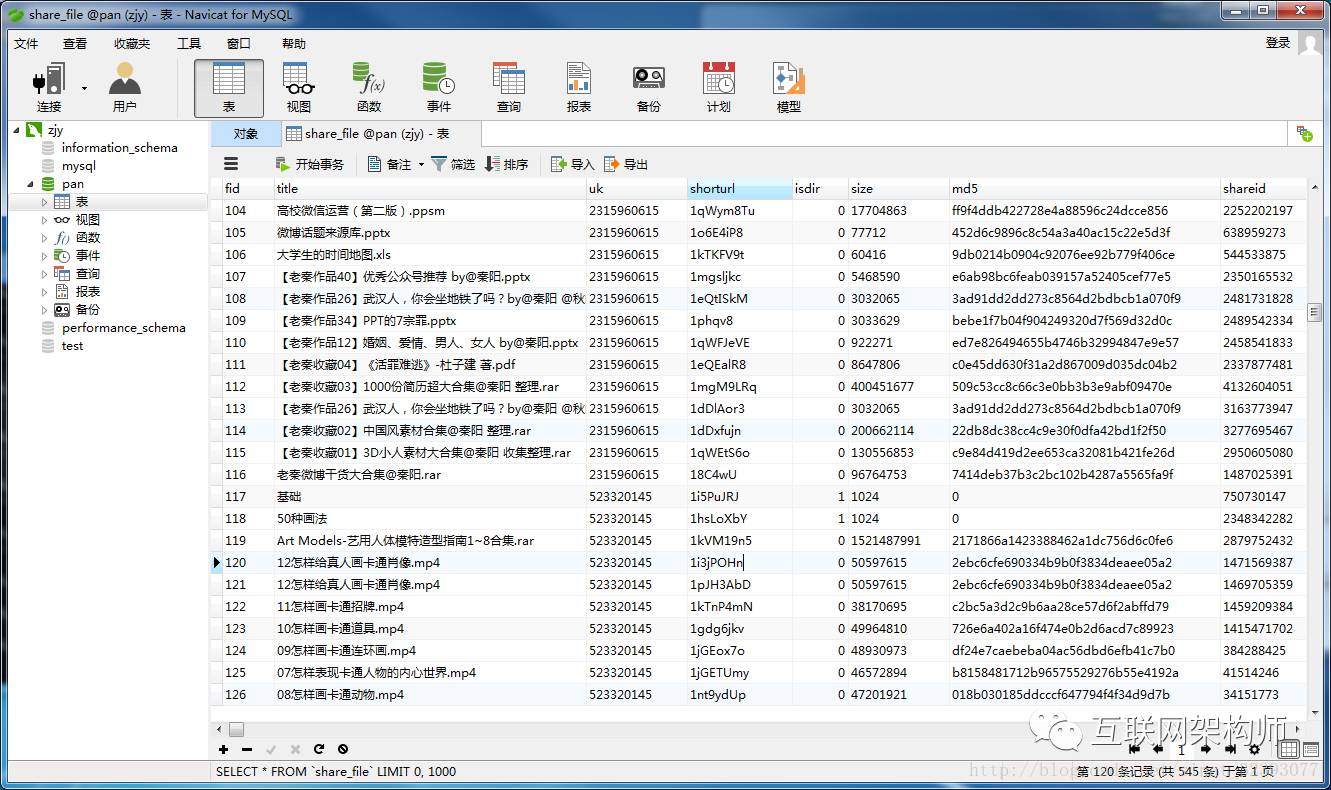
其中title是资源的名称,shorturl是资源的短网址
比如:“布施知子.-.Boxes.and.Fuses.pdf”shorturl为‘1i3Kginr’
拼上百度网盘的地址‘https://pan.baidu.com/s/’
即https://pan.baidu.com/s/1i3Kginr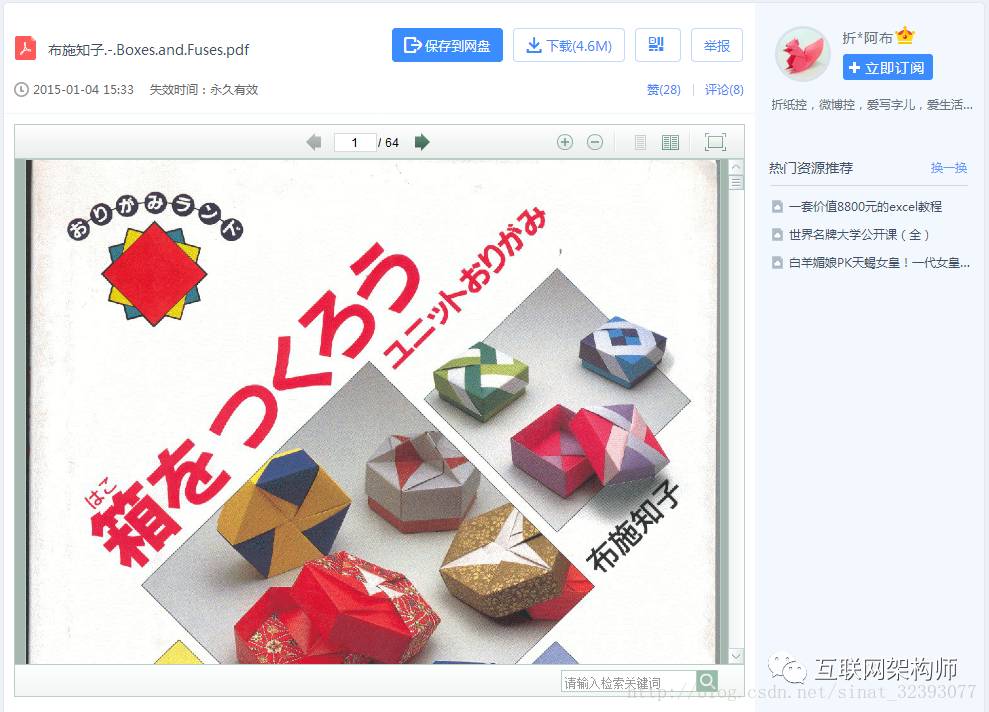
完美实现!后面可以针对数据库做相关条件的查询、处理等实现自己想要的功能。
向大神致敬!
文章地址:http://mp.weixin.qq.com/s/nJP0arixx9v3Xtu_VDpqyg
代码地址:https://github.com/x-spiders/baiduyun-spider
看完本文有收获?请转发分享给更多人
欢迎关注“互联网架构师”,我们分享最有价值的互联网技术干货文章,助力您成为有思想的全栈架构师,我们只聊互联网、只聊架构,不聊其他!打造最有价值的架构师圈子和社区。
本公众号覆盖中国主要首席架构师、高级架构师、CTO、技术总监、技术负责人等人 群。分享最有价值的架构思想和内容。打造中国互联网圈最有价值的架构师圈子。
长按下方的二维码可以快速关注我们

如想加群讨论学习,请点击右下角的“加群学习”菜单入群

















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









