





 本文是Redis教程,介绍了Windows版Redis的安装与客户端连接,提到其支持多数据库但更像命名空间。还阐述了发布订阅功能、事务机制(虽可批量执行但非原子化)、安全验证方法。此外,讲解了Redis分区,包括分区的优势(扩展内存、计算和网络能力)与不足(部分操作受限、数据处理复杂)。
本文是Redis教程,介绍了Windows版Redis的安装与客户端连接,提到其支持多数据库但更像命名空间。还阐述了发布订阅功能、事务机制(虽可批量执行但非原子化)、安全验证方法。此外,讲解了Redis分区,包括分区的优势(扩展内存、计算和网络能力)与不足(部分操作受限、数据处理复杂)。
Redis 教程| 菜鸟教程
Window版本 下安装Redis 下载地址:https://github.com/MSOpenTech/redis/releases。
打开一个 cmd 窗口 使用 cd 命令切换目录到 解压的redis 下运行:
redis-server.exe redis.windows.conf
这时候另启一个 cmd 窗口,原来的不要关闭,不然就无法访问服务端了。
切换到 redis 目录下运行:
redis-cli.exe -h 127.0.0.1 -p 6379
有时候会有中文乱码,要在 redis-cli 后面加上 --raw redis-cli --raw就可以避免中文乱码了。
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | — |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除,查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 2、带权重的消息队列 |
Redis支持多个数据库,并且每个数据库的数据是隔离的不能共享,并且基于单机才有,如果是集群就没有数据库的概念。
Redis是一个字典结构的存储服务器,而实际上一个Redis实例提供了多个用来存储数据的字典,客户端可以指定将数据存储在哪个字典中。这与我们熟知的在一个关系数据库实例中可以创建多个数据库类似,所以可以将其中的每个字典都理解成一个独立的数据库。
每个数据库对外都是一个从0开始的递增数字命名,Redis默认支持16个数据库(可以通过配置文件支持更多,无上限),可以通过配置文件中的databases来修改这一数字。客户端与Redis建立连接后会自动选择0号数据库,不过可以随时使用SELECT命令更换数据库,如要选择1号数据库:
redis> SELECT 1
OK
redis [1] > GET foo
(nil)
然而这些以数字命名的数据库又与我们理解的数据库有所区别。首先Redis不支持自定义数据库的名字,每个数据库都以编号命名,开发者必须自己记录哪些数据库存储了哪些数据。另外Redis也不支持为每个数据库设置不同的访问密码,所以一个客户端要么可以访问全部数据库,要么连一个数据库也没有权限访问。最重要的一点是多个数据库之间并不是完全隔离的,比如FLUSHALL命令可以清空一个Redis实例中所有数据库中的数据。
综上所述,这些数据库更像是一种命名空间,而不适宜存储不同应用程序的数据。比如可以使用0号数据库存储某个应用生产环境中的数据,使用1号数据库存储测试环境中的数据,但不适宜使用0号数据库存储A应用的数据而使用1号数据库B应用的数据,不同的应用应该使用不同的Redis实例存储数据。由于Redis非常轻量级,一个空Redis实例占用的内在只有1M左右,所以不用担心多个Redis实例会额外占用很多内存。
发布订阅
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
redis 127.0.0.1:6379> SUBSCRIBE redisChat (可订阅多个channel渠道)
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
redis 127.0.0.1:6379> PUBLISH redisChat "Redis is a great caching technique"
(integer) 1
redis 127.0.0.1:6379> PUBLISH redisChat "Learn redis by runoob.com"
(integer) 1
# 订阅者的客户端会显示如下消息
1) "message"
2) "redisChat"
3) "Redis is a great caching technique"
1) "message"
2) "redisChat"
3) "Learn redis by runoob.com"
SUBSCRIBE channel [channel ...] 订阅给定的一个或多个频道的信息。
PSUBSCRIBE pattern [pattern ...] 订阅一个或多个符合给定模式的频道。
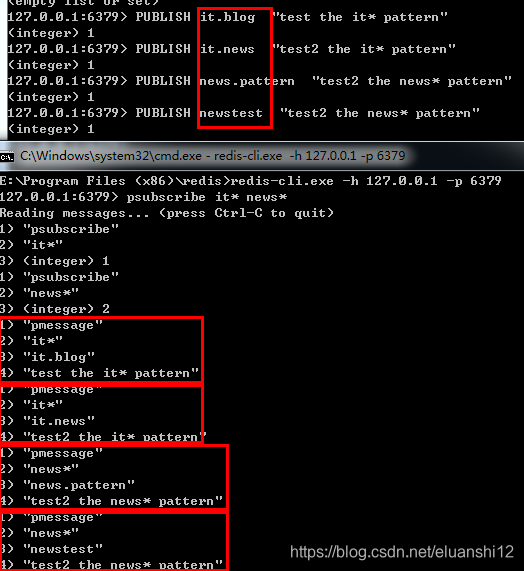
每个模式以 * 作为匹配符,
比如 it* 匹配所有以 it 开头的频道( it.news 、 it.blog 、 it.tweets …)。
news.* 匹配所有以 news. 开头的频道( news.it 、 news.global.today… )。
Redis 事务
Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
批量操作在发送 EXEC 命令前被放入队列缓存。
收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:开始事务、命令入队、执行事务。
- MULTI 标记一个事务块的开始。
- EXEC 执行所有事务块内的命令。
- DISCARD 取消事务,放弃执行事务块内的所有命令。
- UNWATCH 取消 WATCH 命令对所有 key 的监视。
- WATCH key [key …] 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
redis 127.0.0.1:7000> multi
OK
redis 127.0.0.1:7000> set a aaa
QUEUED
redis 127.0.0.1:7000> set b bbb
QUEUED
redis 127.0.0.1:7000> set c ccc
QUEUED
redis 127.0.0.1:7000> exec
1) OK
2) OK
3) OK
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。
Redis 安全
查看是否设置了密码验证:
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) "" 默认情况下 requirepass 参数是空的,这就意味着你无需通过密码验证就可以连接到 redis 服务
设置密码后,客户端连接 redis 服务就需要密码验证,否则无法执行命令。
127.0.0.1:6379> CONFIG set requirepass "runoob"
OK
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) "runoob"
AUTH 命令基本语法格式如下:127.0.0.1:6379> AUTH password
如何连接到主机为 127.0.0.1,端口为 6379 ,密码为 mypass 的 redis 服务上。
$redis-cli -h 127.0.0.1 -p 6379 -a "mypass"
Redis 客户端连接
Redis 通过监听一个 TCP 端口或者 Unix socket 的方式来接收来自客户端的连接,当一个连接建立后,Redis 内部会进行以下一些操作:
- 客户端 socket 会被设置为非阻塞模式,因为
Redis 在网络事件处理上采用的是非阻塞多路复用模型。 - 为这个 socket 设置 TCP_NODELAY 属性,禁用 Nagle 算法
- 创建一个可读的文件事件用于监听这个客户端 socket 的数据发送
Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
(减少大量小包的发送) 其目的是解决大量的小包造成网络负担上升的问题,方法是囤积数据到满足条件为止,然后发送大数据包。
Redis 分区
分区是分割数据到多个Redis实例的处理过程,因此每个实例只保存key的一个子集。
分区的优势
- 通过利用多台计算机内存的和值,允许我们构造更大的数据库。
- 通过多核和多台计算机,允许我们扩展计算能力;通过多台计算机和网络适配器,允许我们扩展网络带宽。
分区的不足
redis的一些特性在分区方面表现的不是很好:
- 涉及多个key的操作通常是不被支持的。举例来说,当两个set映射到不同的redis实例上时,你就不能对这两个set执行交集操作。
- 涉及多个key的redis事务不能使用。
- 当使用分区时,数据处理较为复杂,比如你需要处理多个rdb/aof文件,并且从多个实例和主机备份持久化文件。
- 增加或删除容量也比较复杂。
redis集群大多数支持在运行时增加、删除节点的透明数据平衡的能力,但是类似于客户端分区、代理等其他系统则不支持这项特性。然而,一种叫做presharding的技术对此是有帮助的。

















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









