






 本文深入探讨了一种基于多元高斯分布的异常检测算法。首先介绍了参数拟合过程,通过计算所有样例的平均值作为μ,估计协方差矩阵Σ。然后在训练集上构建模型,并对新测试样本计算其在高斯分布中的概率密度。如果概率低于阈值,则标记为异常。相较于原模型,多元高斯模型更能捕捉特征间的相关性。当Σ不可逆时,可能因特征冗余导致。最后,讨论了两种模型的适用场景,多元高斯模型适用于处理特征相关性的场景。
本文深入探讨了一种基于多元高斯分布的异常检测算法。首先介绍了参数拟合过程,通过计算所有样例的平均值作为μ,估计协方差矩阵Σ。然后在训练集上构建模型,并对新测试样本计算其在高斯分布中的概率密度。如果概率低于阈值,则标记为异常。相较于原模型,多元高斯模型更能捕捉特征间的相关性。当Σ不可逆时,可能因特征冗余导致。最后,讨论了两种模型的适用场景,多元高斯模型适用于处理特征相关性的场景。
Let's develop a different anomaly detection algorithm based on multivariate Gaussian distribution.
Parameters fitting
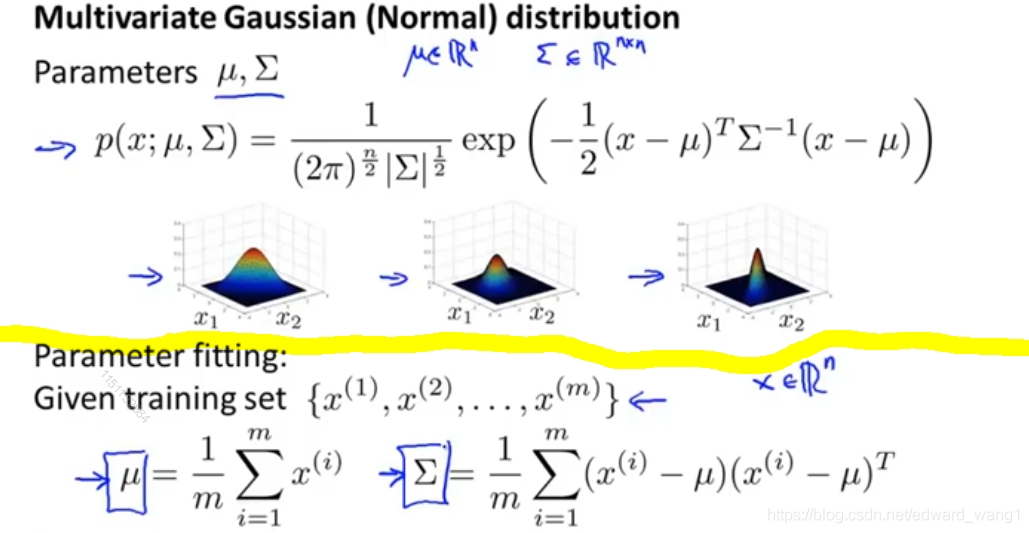
The upper part of figure-1 is a recap for definition of multivariate Gaussian distribution. Also it shows a range of different distributions as verying and
. The lower part shows how to fit the parameters. If I have a set of examples
Then you set as the average of all examples. And set
So given the data set, we can estimate and
. And get definition of
Multivariate Gaussian algorithm

Figure-2 shows the steps of anomaly detection with multivariate Gaussian algorithm.
- First, we take our training set and fit the model
by setting
and
as described in section "Parameters fitting".
- Next, when you're given a new test example
, the green cross, we need compute
- Then, if
, we flag it as an anomaly; otherwise, we don't flag it as an anomaly.
It turns out, if we were to fit a multivariate Gaussain distribution to this data set (red crosses), you end up with a distribution that places lots of probability in the central regions, slightly less probability in the outer regions. And very low probability at the green cross point. And the green cross example will be correctly flaged as an anomaly.
Relationship to original model
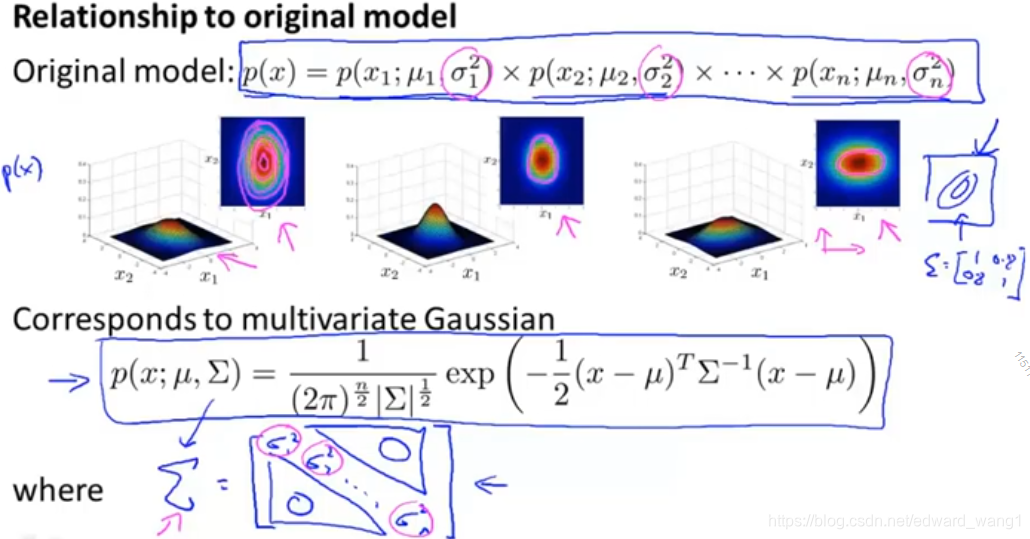
The original model corresponds to multivariate Gaussian where the contours of the Gaussian are always axes aligned.
Mathematically, it turns out that the original model
is actually the same as a multivariate Gaussian distribution but with a constraint that everything on the off diagonal of is 0:
if you plug of original model into
, then the two models are actually identical.
So the original model is actually a special case of this multivariate Gaussian model.
Which one to use?

When would you use each of these two models? In general, the original model is probably used somewhat more often; whereas the multivariate Gaussian distribution is used somewhat less but it has the advantage of being able to capture correlations between features. Above figure-4 shows the scenarios.
If the sigma is singular
If you're fitting with multivariate Gaussian and find that is non-invertible, then there are usually two cases for this:
- Failed to satisfy
condition
- You have redundant features which means that features that are linearly dependent. For example, you had two copies of the same feature; or maybe you have some feature like
.
<end>

















 1680
1680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









