




1. 程序重定位
1.1 为什么要进行重定位
在编译代码形成可执行程序时,用到的地址都是从0开始的相对地址。可执行程序中的地址通常被称作相对地址。在执行程序的时候要把相对地址转换位物理内存地址,什么时候转换?怎么转换?是操作系统内存管理的重要问题。
1.2 载入时重定位
在程序载入时,根据载入的物理内存地址区域来修改程序的逻辑地址。设程序被载入的物理内存起始地址位X,程序中的逻辑地址位Y,则程序中的地址会被改为X + Y。但是这样做还是不够灵活。比如如果一个进程被阻塞放入磁盘,再被调度会内存的时候就要求载入的基址不能改变,这在很大程度上限制了内存的使用。
1.3 运行时重定位和MMU
在指令执行时才将指令的逻辑地址转化为物理地址,但是每执行一条指令就要进行一次转化太慢了,所以要设计一套硬件系统来完成这个转化,这一套硬件系统被Intel称为Protected-Model,被AMD称为MMU(Memory Management Unit)
物理内存地址 = MMU(逻辑地址)。MMU只能有一个,但是系统中有多个进程,每个进程最终都要被放到不同的物理内存区域,相应的产生多个基址,故每个进程的PCB中都包含自己的MMU内容。
2. 以进程的角度——分段机制
2.1 段的概念
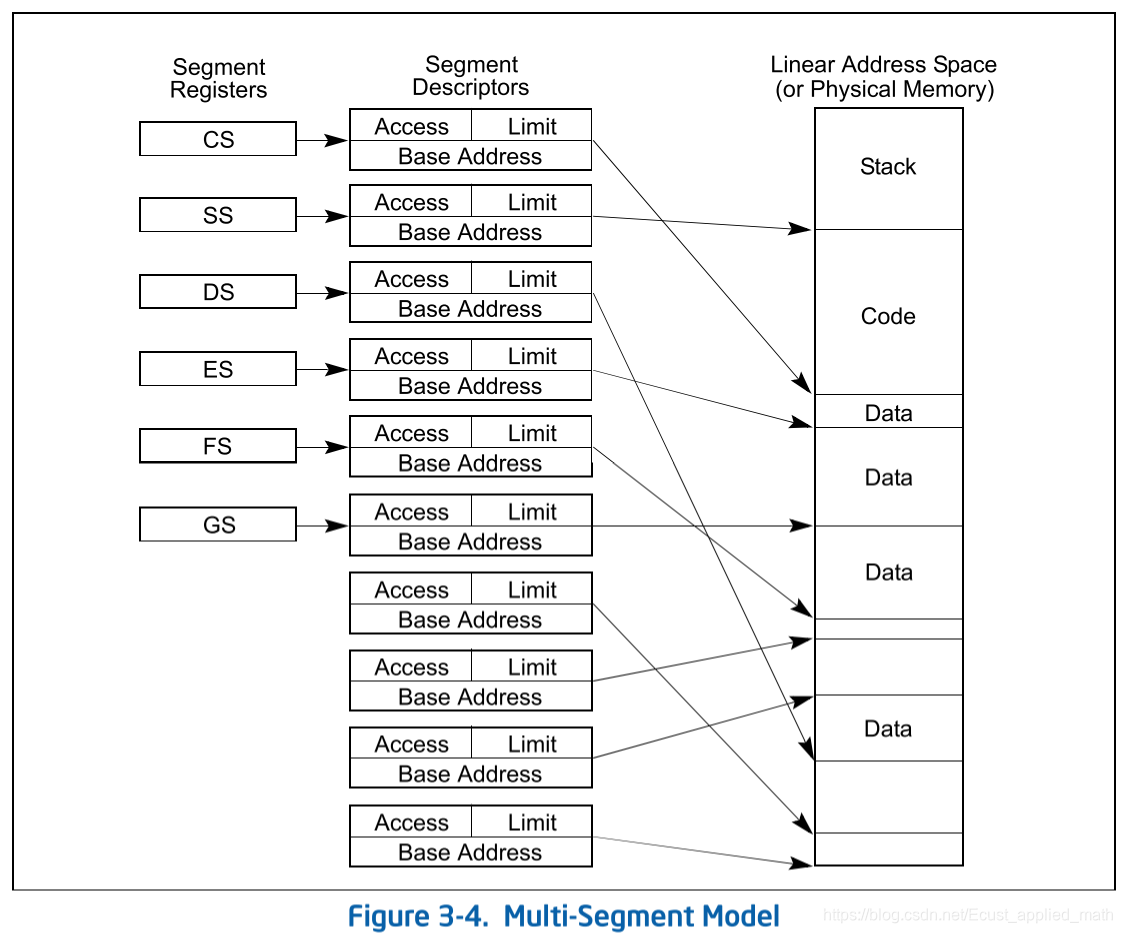
一个程序被分为多个段。最典型的一个分段是数据段、代码段、栈段、附加段,x86系列处理器提供了CS,SS,DS,ES,FS,GS六个段寄存器。
2.1 x86-32位保护模式分段机制下的地址转换
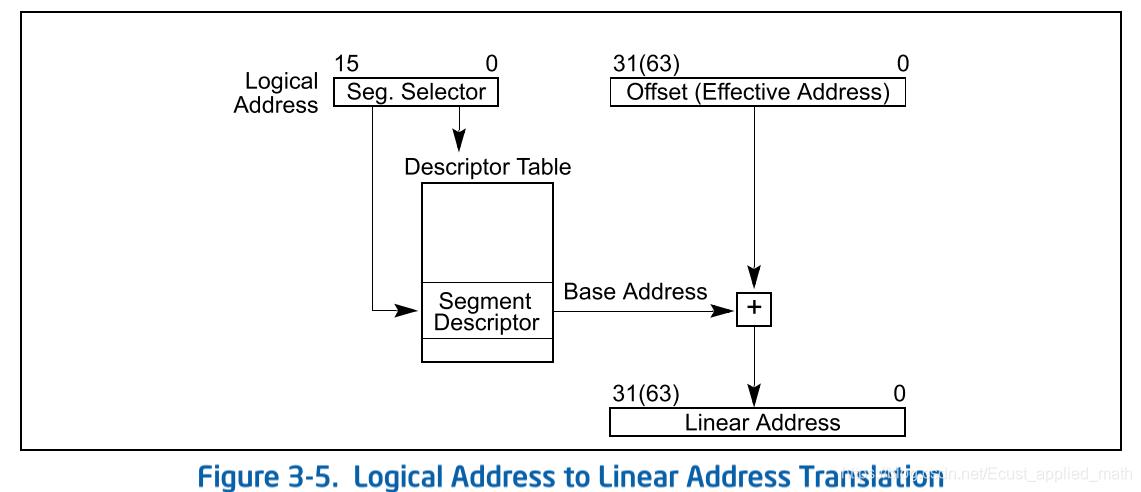
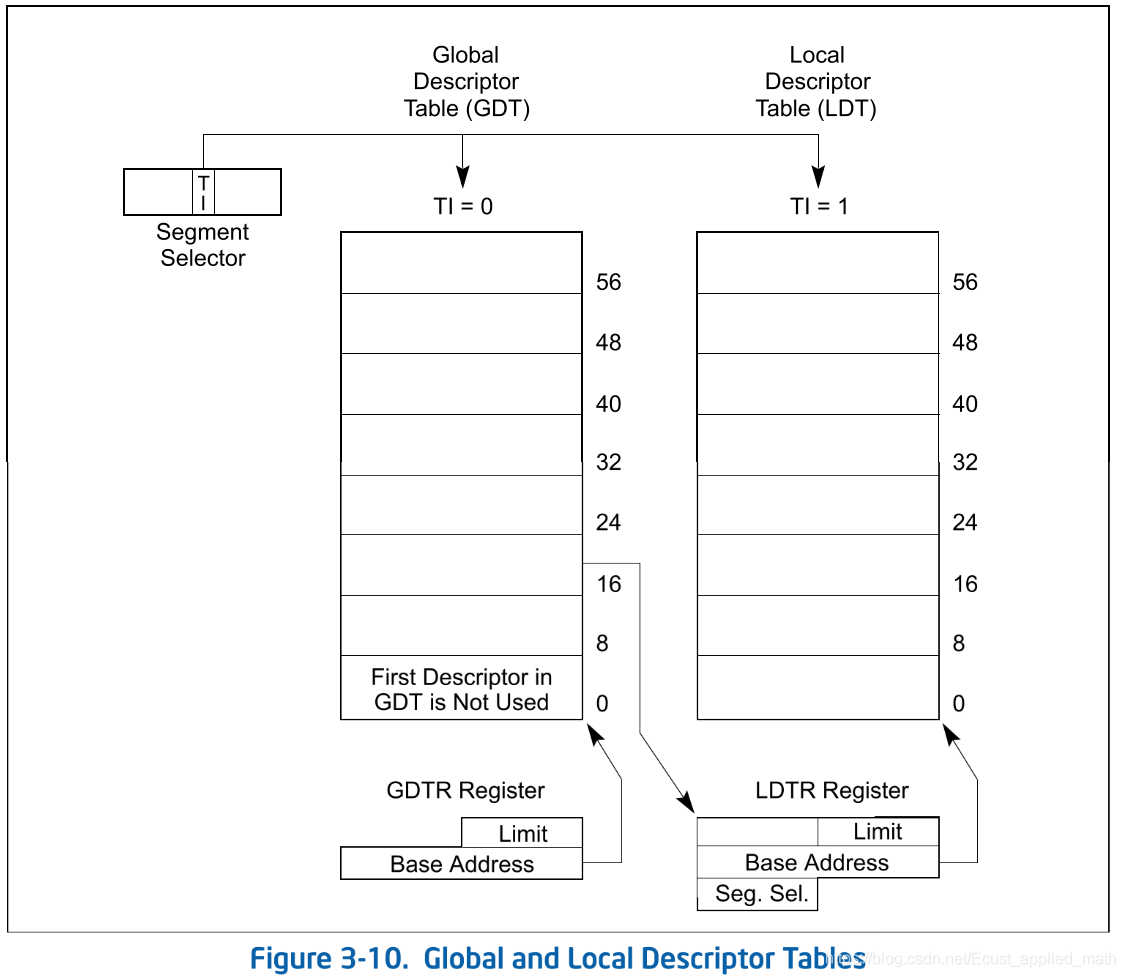
2.2 GDT和LDT的关系
GDTR指向GDT,GDTR中使用的是真实的物理内存地址。GDT是一个数组,数组的每一项是一个段描述符,占用8个字节。GDT[0]一般不被使用,被称为"null descriptor"。LDT是存储在操作系统内核段中的,GDT必须包含指向LDT段的段描述符。如果操作系统支持多LDT,那么GDT中必须包含每个一个独立段选择符和段选择子。
3. 以内存的角度——分页机制
3.1 分页的概念
分页机制是为了解决段再内存中的分配问题所提出的。分页机制首先将物理内存分割成大小相同的页框,然后再将请求放入物理内存的数据(比如代码段)也分割成同样大小的页,最好把所有页都映射到页框上。
3.2 分页机制下的地址转换
物理地址 = 页表(线性地址)
3.2.1 最原始的页表
32为处理器的寻址空间为4G,每个页的大小为4K,那么页表就需要4G / 4K 共计,假设内存的大小为128MB,共计1048576项。
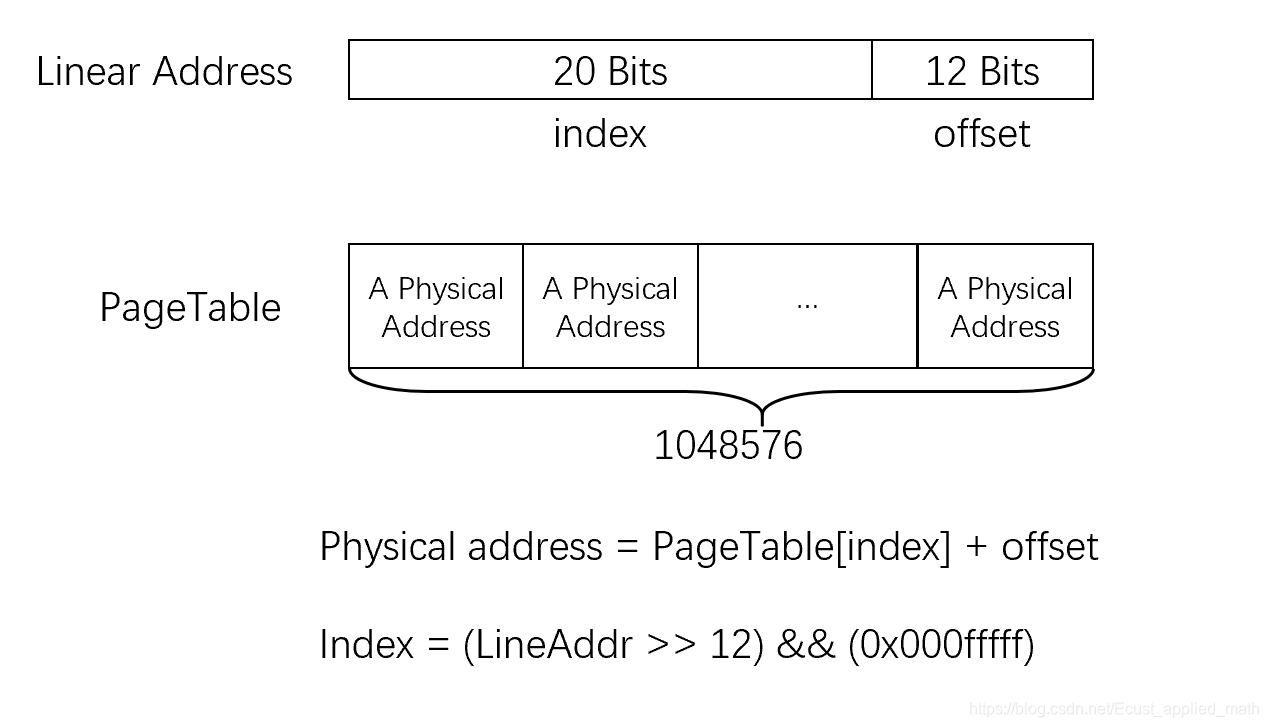
这样做带了一个很大的问题:页表太大了。1048576项,每项存储着一个32位的地址,即4字节,页表共计1048576 * 4 = 4194304 Bytes = 4MB。通常一个进程有一个页表,这样搞未免太浪费了。
注: Linux-0.11完全可以这样搞!因为所有的进程共享一个页表,可以尝试修改一下。
3.2.2 优化后不连续的页表
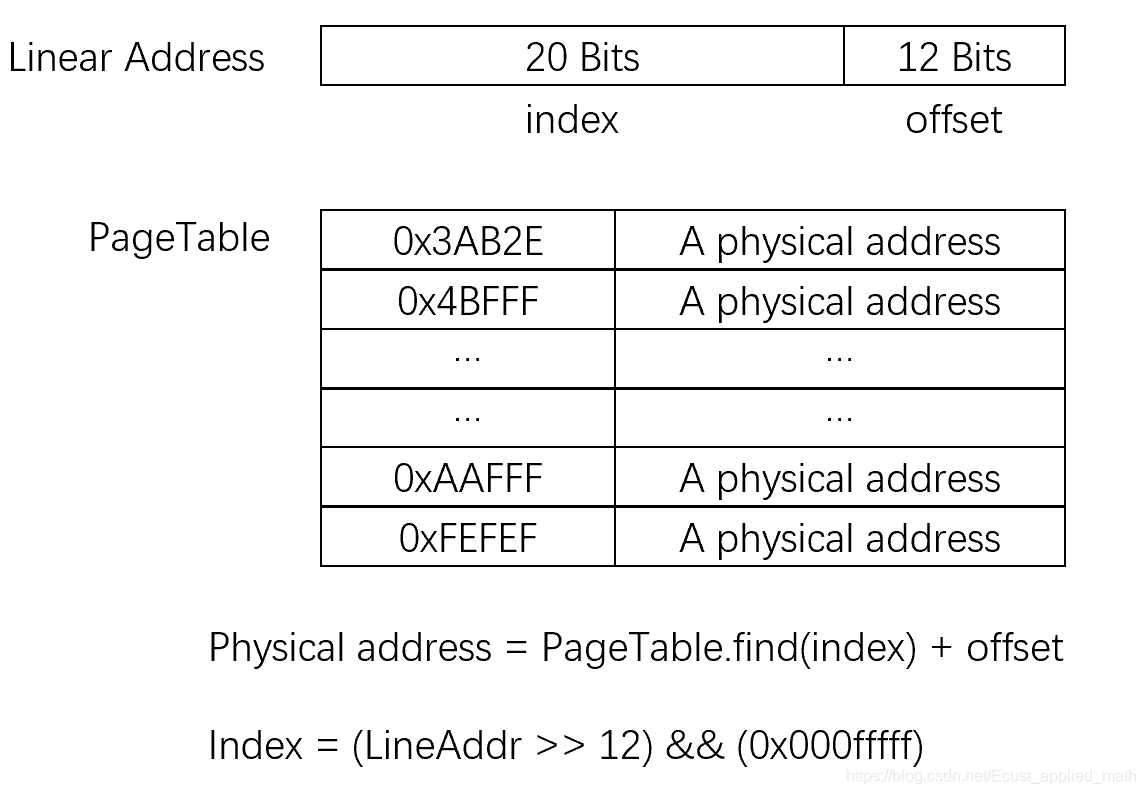
这样页表就可以变得很小了,但是时间复杂度又上去了,因为PageTable[n]的复杂度为O(1),PageTbale.find(n)及时在保证页表有序的情况下用二分查找复杂度也为o(lg(n))。
3.2.3 多级页表
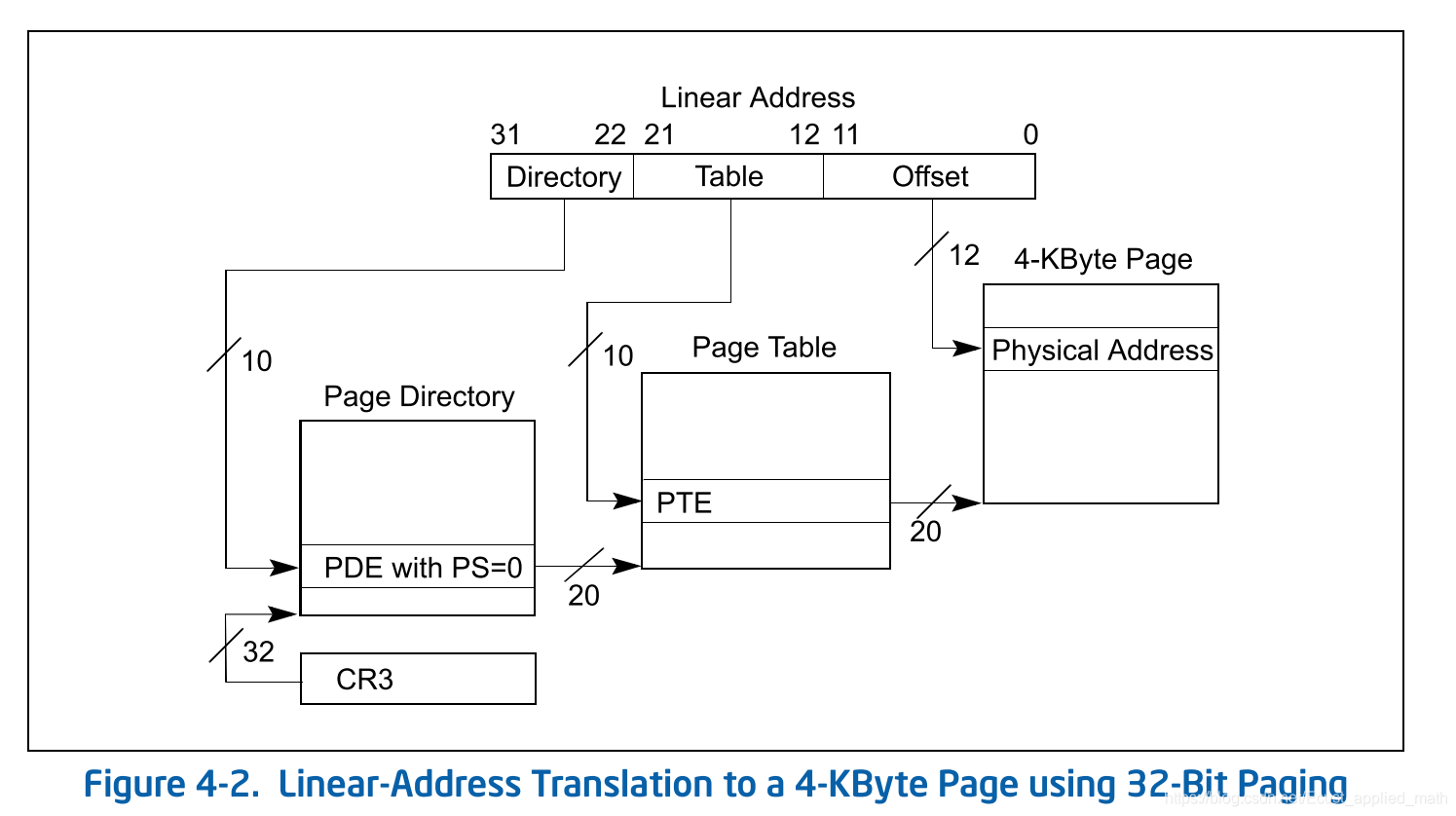
这样做使得分页模型变成了
Physical_Address = PageDir[DirIndex]->PageTable.find(PIndex) + offset
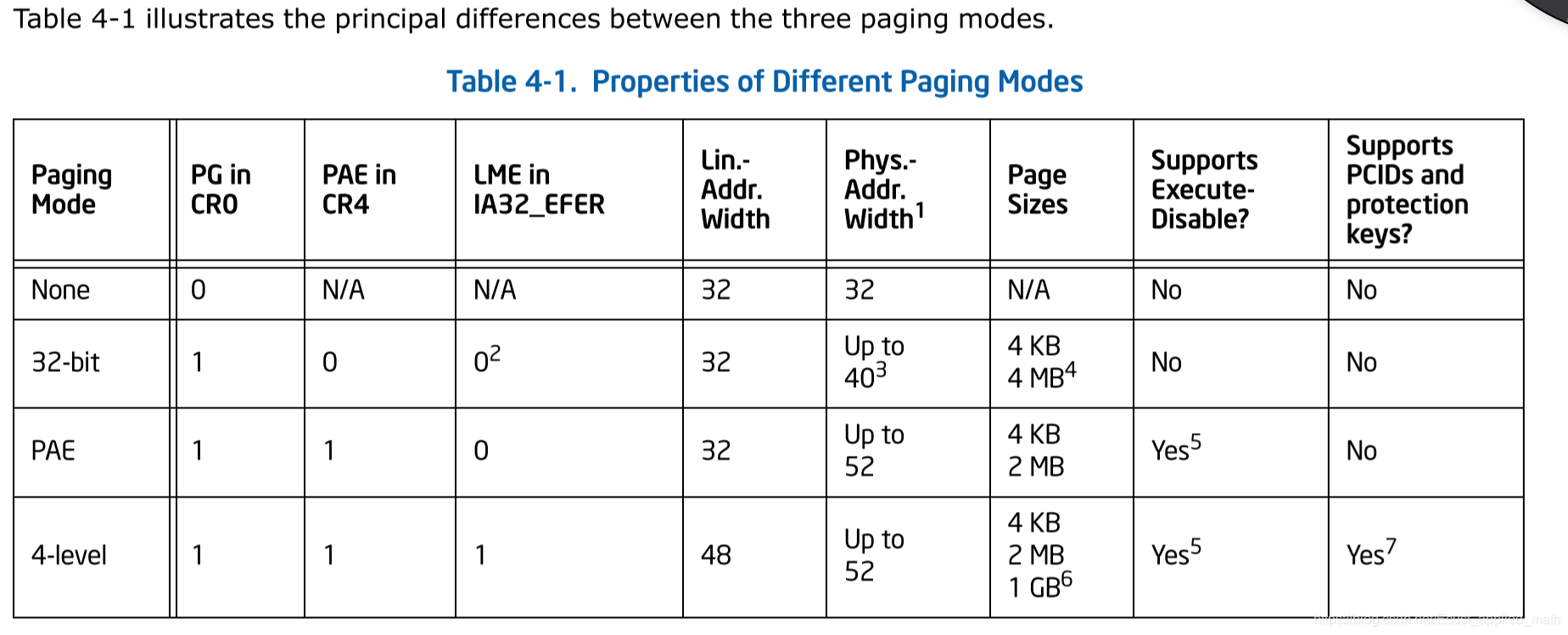
x86还支持几种分页模型
3.2.4 高速缓冲
通过多级页表,解决了空间问题,分级也解决了大部分的速度问题,但是速度问题还是比较致命。可以考虑这种解决办法:由于程序具有局部性原理,当程序使用线性地址A并查到A在页表中的映射时,把这个映射记录在一个支持并行查找的表中。x86采用高速缓存(Cache)来解决这个问题,Cache是硬件,支持在O(1)的时间内查找不连续的线性表。我们可以用Cache来存储常用的逻辑页映射关系,这个表被称作快表(TLB.Translation lookaside buffer)。此时地址转换变为
if LinearAddr in TLB.keys():
physical_addr = TCB[pyysical_addr]
else:
Dir = PageDict.find(DirIndex)
physical_addr = Dir->PageTable.find(PageIndex) + offset
3.2.5 收获
从页表中可以获取到的思路有:
1、当一大堆连续的数据有空值的时候,可以采用不连续的方式来存储。
2、使用不连续的存储方式就丧失了O(1)的访问复杂度
3、如果可以接受O(lgn)的复杂度,就用平衡二叉树来存储这些数据
4、如果还是不能接受O(lgn)的复杂度,可以采用分级的方式
5、如果访问具有局部性的原理,可以用高速缓冲。
举个例子:
客户那里有一个包含10000000000000个二元组(A,B)的线性表Table存,A总是有意义的并且是有序的,B可能有,也可能没有。我们的业务主要是根据一个a ∈ A,来查找Table中对应的B。我们把客户的数据Copy过来的时候自动过滤掉第二项没有意义的B中的元素。这样虽然丧失了随机访问的特性,但是还是可以用二分法来查找。如果还是慢,对A进行连续映射,比如映射成1,2,3,4个数字,对于查询请求Table.get(“a”),先对a进行映射,比如映射到3,就到3起始的位置开始用二分查找。如果客户有局部性访问的性质,总是在一个时间段内访问,我们可以在内存中实现一个快表(可以用栈的思路,请求a,就把a挪到栈顶,这样可以保证栈中总是最近访问的),当查询请求Table.get(“a”)过来的时候,现在快表中查询。
4. 以虚拟内存为桥梁的、分段和分页结合的段页式内存管理
4.1 虚拟内存的提出
可以采用一个中间结构来结合段式内存管理。这个中间结构被成为虚拟内存。
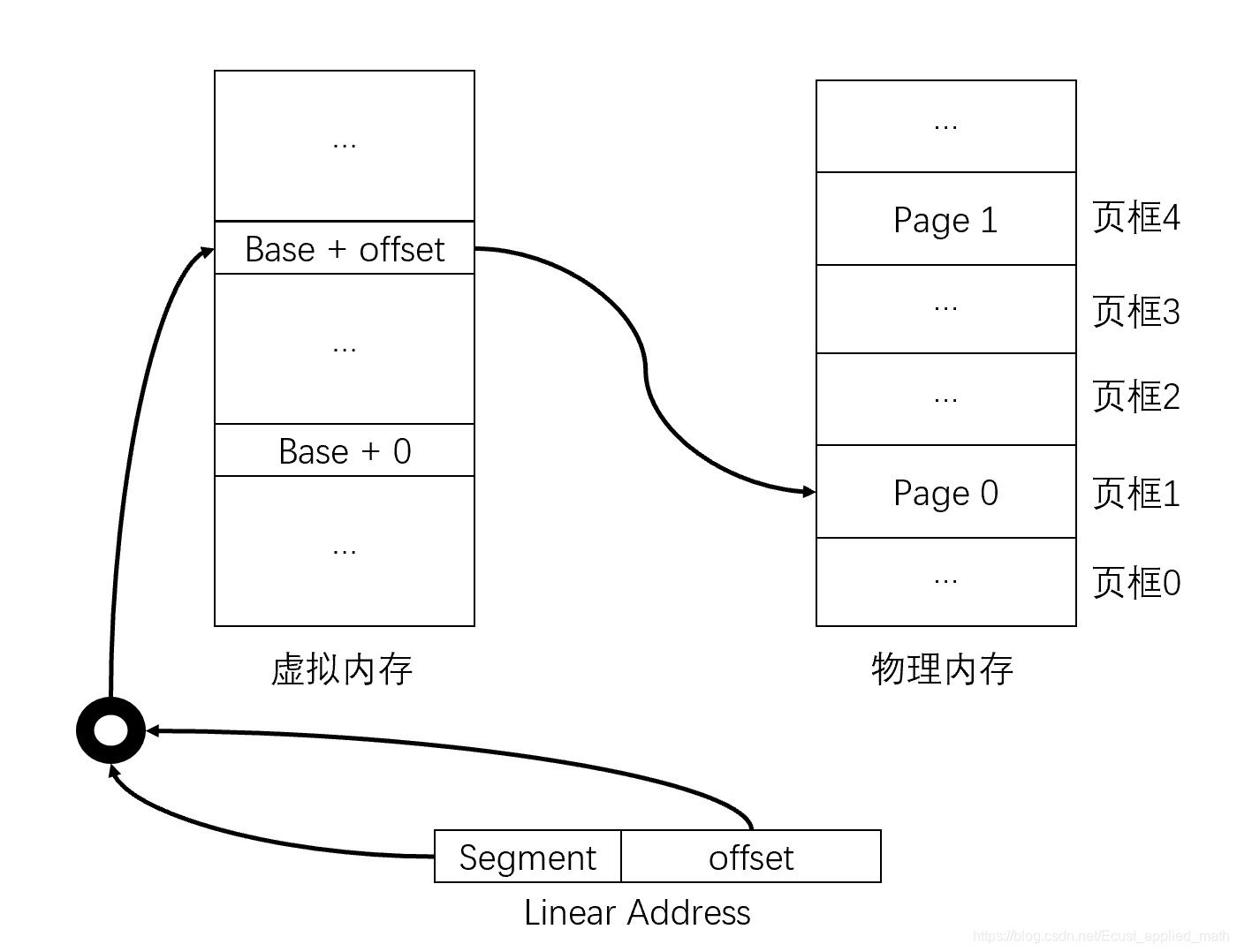
这样虚拟还有一个好处,可以给每个页表都虚拟出一个4G的内存空间出来,如果每个进程都有一个页表,那么每个进程都好像有4G的内存空间一样。
最终的寻址方式如图:
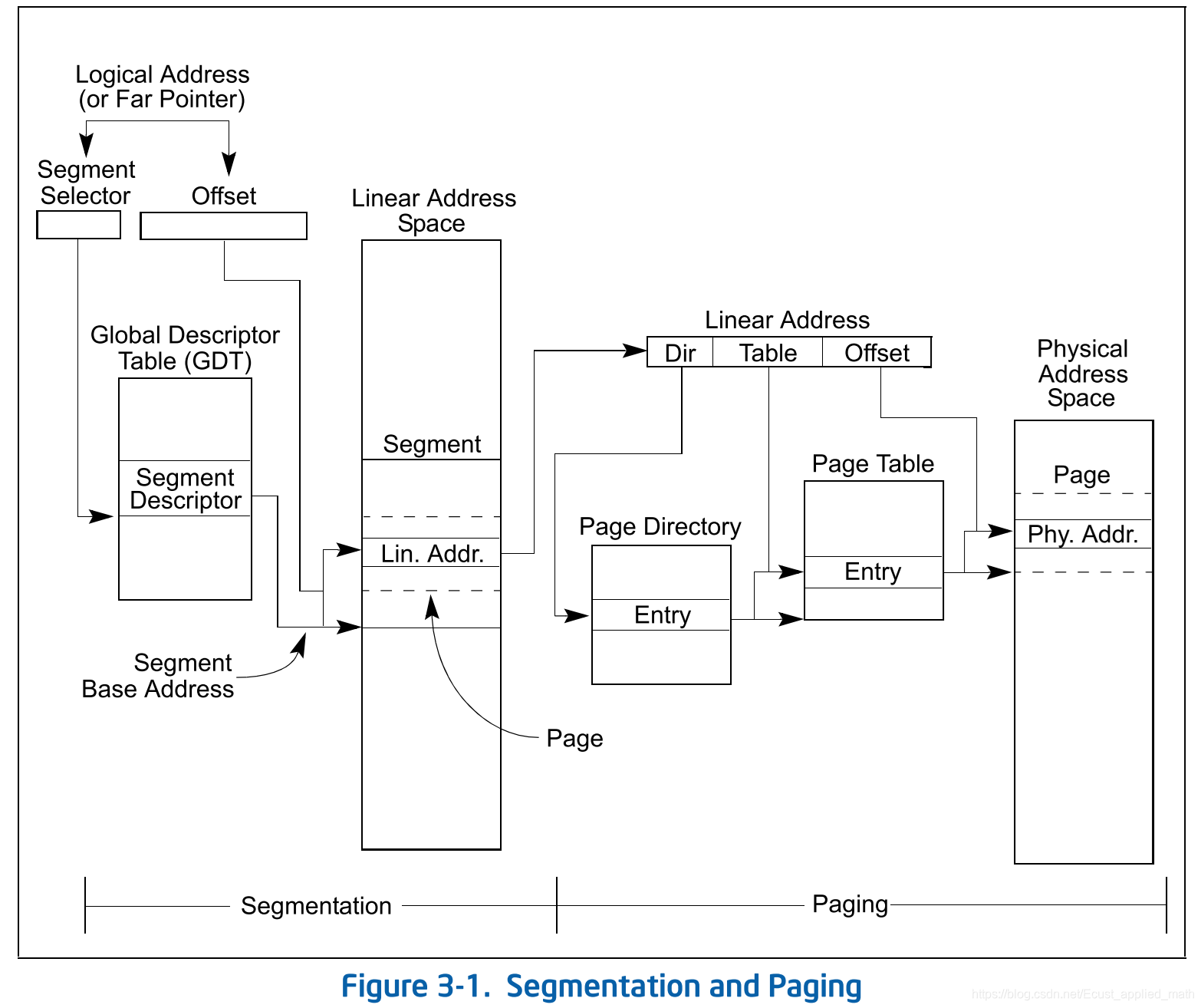
启示:
对于同一个Object,处在上层的甲想以A方式使用Object,而Object自身想以B方式使用Object,如何把A和B的使用结合起来呢?答案是虚拟,可以给虚拟一个Virtual-Object,甲通过方式A来使用Virtual-Object,Virtual-Object把甲的操作映射为以方式B来对Object进行操作。
举例:
1、用户想通过人性化、结构化的方式访问磁盘,于是提出了文件系统。文件系统就是对磁盘的一个虚拟。
程序员通过open、read、write、close系统调用来使用文件系统。
文件系统通过in,out的CPU指令来控制磁盘。
2、用户想通过简单的方式来使用网卡,于是提出了套接字网络栈,用户可以通过Http、Socket、icmp协议来使用网络栈,网络栈通过int,out指令来控制网卡。
4.2 Linux-0.11系统调用fork中的内存管理
进程创建fork()中关于内存的使用就是将程序装入内存中,所以fork的内存工作应该完成四件事: 在虚拟内存中分段、建立段表、将虚拟内存的页映射到空闲物理页框、建立页表。
fork的核心是copy_process
//分段
int copy_process(int nr,....)
{
//nr是新建立进程的序号
...
copy_mem(nr,p);//p指向新创建的进程
...
}
int copy_mem(int nr,task_struct * parent){
...
分段
...
分页
...
}
4.2.1 在虚拟内存中分段、建立段表
int copy_process(int nr,...){
...
copy_mem(nr,p);
...
}
int copy_mem(int nr,task_struct * pNew){
...
//分段
unsigned long new_data_base = nr * 0x4000000;//数据段64MB
unsigned long new_code_base = nr * 0x4000000;//代码段64mb
set_base(pNew->ldt[1],new_data_base);
set_base(pNew->ldt[2],new_code_base);
...
}
new_data_base是新的进程在虚拟内存中的基址,在Linux-0.11中,所有的进程共同享用一个虚拟内存,所有的进程使用的虚拟内存不会重叠,所以只用一个页表。进程0的虚拟地址空间为0-63MB,进程1的虚拟地址空间为64-127MB…以此类推。
这里还可以看出,Linux-0.11只使用了两个LDT。
set_base是一个宏,在这里把新进程的ldt[1]和ldt[2]指向基址。
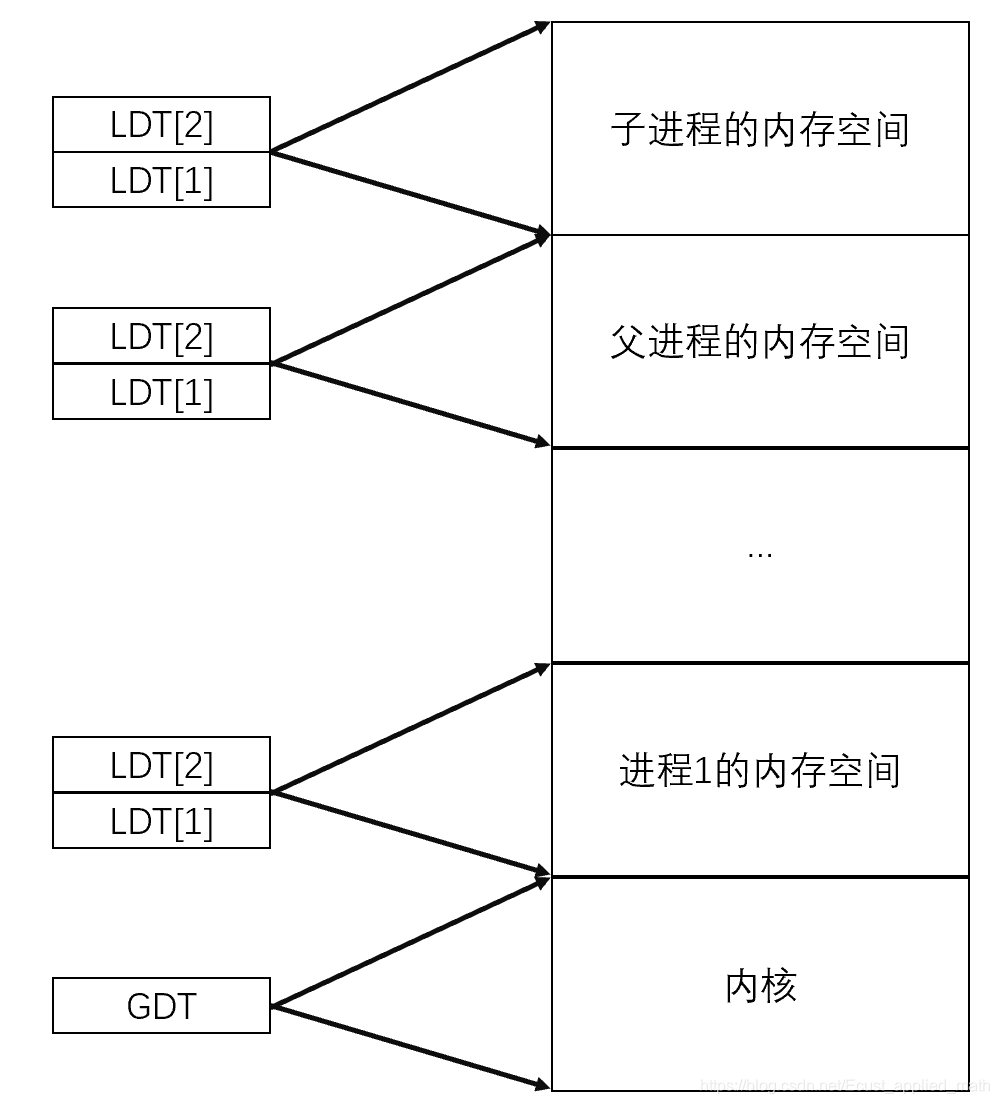
4.2.2 将虚拟内存的页映射到空闲物理页框、建立页表
int copy_mem(int nr,task_struct * pNew){
...
unsigned long old_data_base;
unsigned long old_code_base;
old_data_base = get_base(current->ldt[1])
old_code_base = get_base(current->ldt[2])
copy_page_tables(old_data_base,new_data_base,data_limit);
//copy_page_tables(old_data_base,new_data_base,code_limit);
...
}
int copy_page_tables(unsigned long from,unsigned long to,long size){
from_dir_index = (unsigned long *)(from >> 22);
to_dir_index = (unsigned long *)(to >> 22);
//一个地址所在页在页目录表中的位置为最左边10位,所以向右移动动22位
from_dir = from_dir_index * 4;
to_dir = to_dir_index * 4;
//一个页目录表中的表项占4个字节下标,乘以4就是其在页目录表中的位置
size = 16;
//size初值64MB,0x4000000,一个页目录表现涵盖4MB的内存,所以需要复制16次
for(;size-->0;from_dir++,to_dir++){
from_page_table = (from_dir) & 0xfffff000;
//每个页目录对应1024个页表
to_page_table = get_free_page();
//新的页表需要一页4K内存来存储
*to_dir = ((unsigned long)to_page_table) | 7;
//把新的页表放入目标页目录表中
for(;nr-->0;form_page_table++,to_page_table++){
this_page = *from_page_table;//复制
this_page &= 2;//设置只读
*to_page_table = this_page;//新的页添加进页表
*from_page_table = this_page;//父进程也只读
this_page -= LOW_MEM;
this_page >>= 12;
mem_map[this_page]++;//页引用 + 1,当引用为0是,页无效
}
}
}
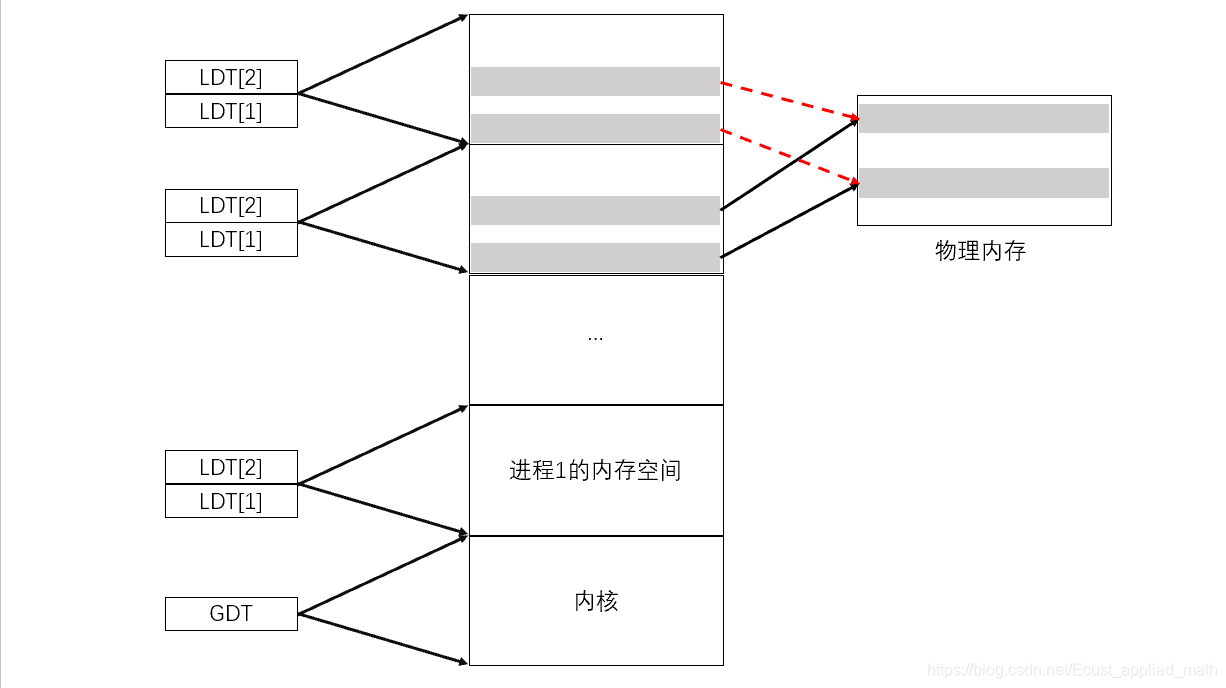
4.2.3 fork的写时复制
父进程调用fork创建子进程的时候,会把页表中对的项的权限修改位只读,这样可以防止程序出错。
| – | 页号(Logical) | 页框号(Physical) | 权限 | 有效 |
|---|---|---|---|---|
| 父 | 3 | 5 | R | 1 |
| 子 | 13 | 5 | R | 1 |
1、当父子进程中的一个要修改页号13中的内容时,会引发内存读写异常中断,中断处理的结果是新分配一个页给此进程并且使这个页的引用计数减1,这就是著名的写时复制的概念,节省了物理内存。
2、如果父子进程都修改了一个页,那么这个页的引用计数会被减为0,被操作系统回收。
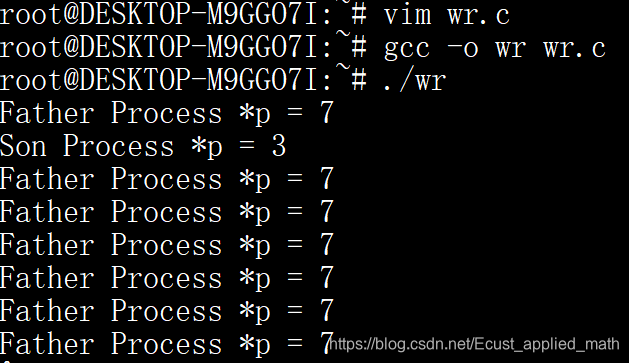
用以下程序来说明问题。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(){
int *p = (int *)malloc(sizeof(int));
*p = 7;
if(!fork()){
*p = 3;
printf("Son Process *p = %d\n",*p);
}
else{
while(1){
printf("Father Process *p = %d\n",*p);
sleep(2);
}
}
return 0;
}
5. 换入/换出
是指可以把一些线性地址空间中的一些页映射到磁盘上,什么时候把页放入磁盘,什么时候把页从磁盘中取出,这个调度算法值得研究。
著名的算法有:
6. 现代操作系统的内存管理模型
6.1 分段——x86体系为了兼容不得不做出的牺牲
6.1.1 8086
Intel 8086是一个16位的CPU。以前的CPU没有段寄存器,访问的地址都为真实物理地址,但当时的CPU的地址总线只有16位,所以最大寻址空间位2^16 Bytes,即64KB。64KB的寻址空间实在是太小了。8086 CPU新增了段寄存器并且规定:所有对于内存的访问必须使用段寄存器+偏移的方式。比如:
- movl %eax,(5000) 使用的是由DS段寄存器所组成的地址
- call 40使用的是由CS段寄存器和40所组成的地址
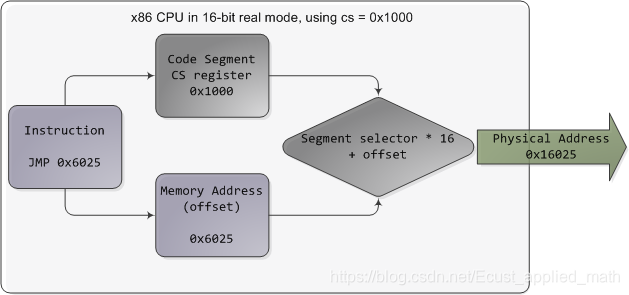
8086的地址总线位20位,寻址方式为(段寄存器 << 4 + 偏移),这样最大寻址空间就变成了2^20 Bytes,即1048576 Bytes,1MB,所以8086的最大寻址空间变成了1MB。
6.1.2 80386
Intel 80386是x86系列的第一个32位处理器。80386仅用一个寄存器来寻址的最大寻址空间为2^32 KB,即4GB,这个空间已经足够大多数程序使用了,时至今日依然如此。理论上来说80386系列并不需要采用分段机制了,但是为了兼容、兼容、兼容,80386系列处理器依然采用段寄存器+偏移的方式来寻址。
- 在实模式下,寻址方式要和8086 CPU兼容,依然采用(段寄存器 << 4 + 偏移)的方式来寻址,但是80386的地址总线只有32位,故肯定无法使用32位的处理器这样寻址,所以在实模式下,80386的工作模式是16位的。
- 在保护模式下,段寄存器被用来在段描述符表中定位一个段描述符,段描述符中的存储着段的基址、限长、访问权限等信息。寻址模式也变成了这样。
- 在保护模式下打开分页模式,80386的寻址方式变成了下图。
80386的地址也分成了以下几类:
| name | 名 | 说明 |
|---|---|---|
| logical_address | 逻辑地址 | 程序中的地址 |
| linear_address | 线性地址 | 虚拟内存中的地址 |
| phsyical_address | 物理地址 | 物理内存的地址 |
6.2 现代Linux如何绕过分段
由于CPU的位数已经满足了线性空间的寻址要求。所以现代的操作系统,几乎不使用分段模式了,但是x86系列处理器默认开启分段模式(为了兼容,x86不得不背上了包袱)。
There is no mode bit to disable segmentation. The use of paging, however, is optional.
《Intel x86编程手册卷3》
i386为了解决这个问题,提供了一种称作Flat Model的内存模型,把每个段都设为基址为0,限长为0~4G。
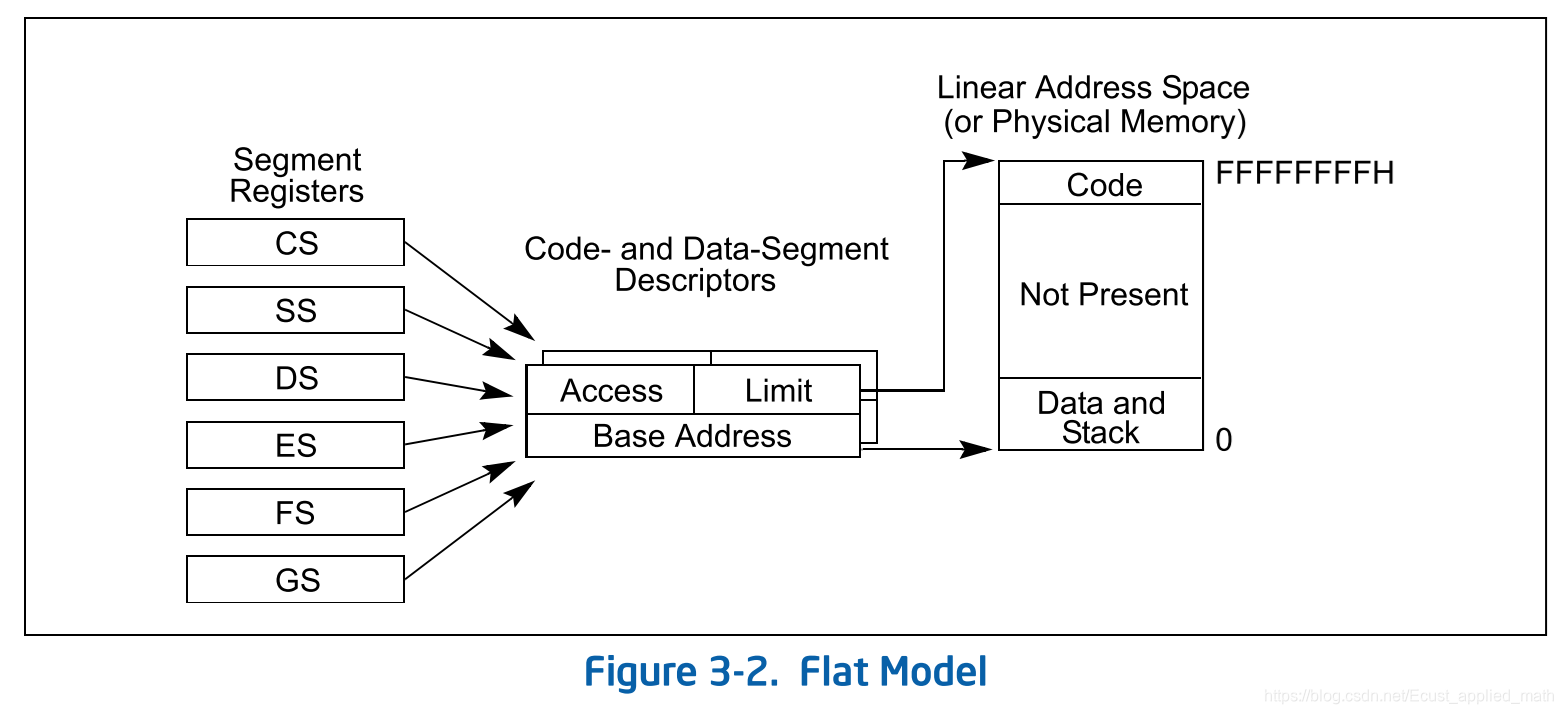
从2.2版开端,Linux让一切的进程都运用相同的逻辑地址空间,因而就没有必要运用局部描述符表LDT。但内核中也用到LDT,那只是在VM86模式中运转Wine,因为就是说在Linux上模仿运转Winodws软件或DOS软件的程序时才运用。在x86上给出的地址都是一个虚拟地址,即任意一个地址都是经过“选择符:偏移量”的方法给出的,这是段机制下内存访问模式的根本特征。所以在x86上规划操作系统时无法逃避运用段机制。一个虚拟地址终究会经过“段基地址+偏移量”的方法转化为一个线性地址。 可是,因为绝大多数硬件渠道都不支撑段机制,只支撑分页机制,所以为了让 Linux 具有更好的可移植性,咱们需求去掉段机制而只运用分页机制。但不幸的是,IA32规则段机制是不行制止的,因而不行能绕过它直接给出线性地址空间的地址。 万般无奈之下,Linux的规划人员爽性让段的基地址为0,而段的界限为4GB,这时给出一个偏移量,则等式为“0+偏移量=线性地址”,也就是说 “偏移量=线性地址”。因为段机制规则“偏移量<4GB”,所以偏移量的规模为0H~FFFFFFFFH,这恰好是线性地址空间规模,也就是说虚拟地址直接映射到了线性地址,今后所说到的虚拟地址和线性地址指的也就是同一地址。看来,Linux在没有逃避段机制的情况下奇妙地把段机制给绕过去了。别的,因为x86段机制还规则,有必要为代码段和数据段创立不同的段,所以Linux有必要为代码段和数据段分别创立一个基地址为0,段界限为4GB 的段描述符。不只如此,因为Linux内核运转在特权级0,而用户程序运转在特权等级3,根据x86段保护机制规则,特权级3的程序是无法访问特权级为 0的段的,所以Linux有必要为内核用户程序别离创立其代码段和数据段。这就意味着Linux有必要创立4个段描述符——特权级0的代码段和数据段,特权级3的代码段和数据段。
总结以上,现代的Linux只用到了四个段,在用户态程序执行时,操作系统内一直存在着这几个段并且每个段都有独立的4G虚拟内存。
| 段名 | 段地址 | CPL(特权级) |
|---|---|---|
| 内核代码段 | GDT[1] | 0 |
| 内核数据段 | GDT[2] | 0 |
| 用户代码段 | LDT[1] | 3 |
| 内核数据段 | LDT[2] | 3 |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









