



梧桐云原生分析型数据库与HIVE对接技术解决方案
1、数据迁移方案
Oracle数据迁移到梧桐云原生分析型数据库采用MapReduce分片抽取加载梧桐云原生分析型数据库方案。具体功能架构如下图所示:

1.1 数据切片
为了提高抽取oracle效率,将oracle表进行均匀切片,多个抽取进程分别负责响应的切片数据,oracle均匀切片实现方式具体如下:
第一、查找抽取数据的区间
select *
from dba_extents
where owner = ‘XXXX’
and segment_name = ‘TB_TEST1’
and partition_name=‘DATA_20240101’;
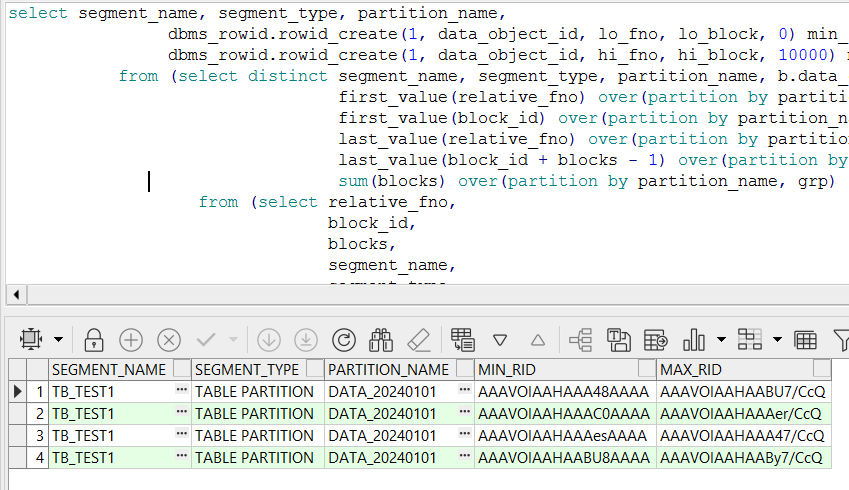
第二、按进程数进行数据切片
根据dbms_rowid.rowid_create计算出每个进程负责抽取的ROWID范围
1.2 数据写入到HDFS
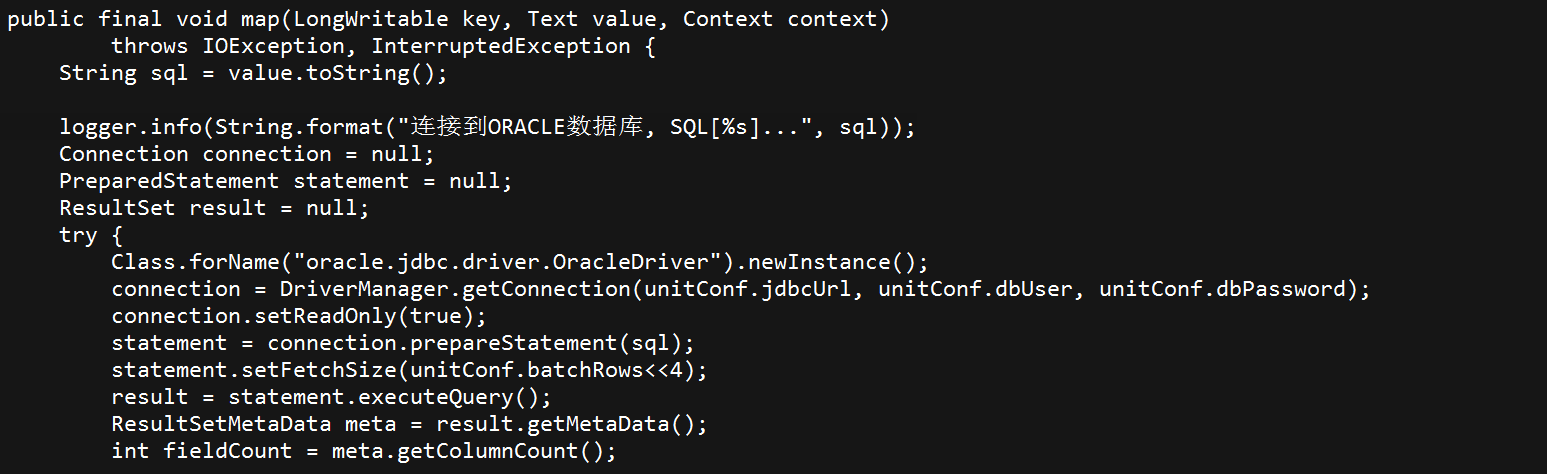
第一、提交MR job,分配每个map负责抽取的范围
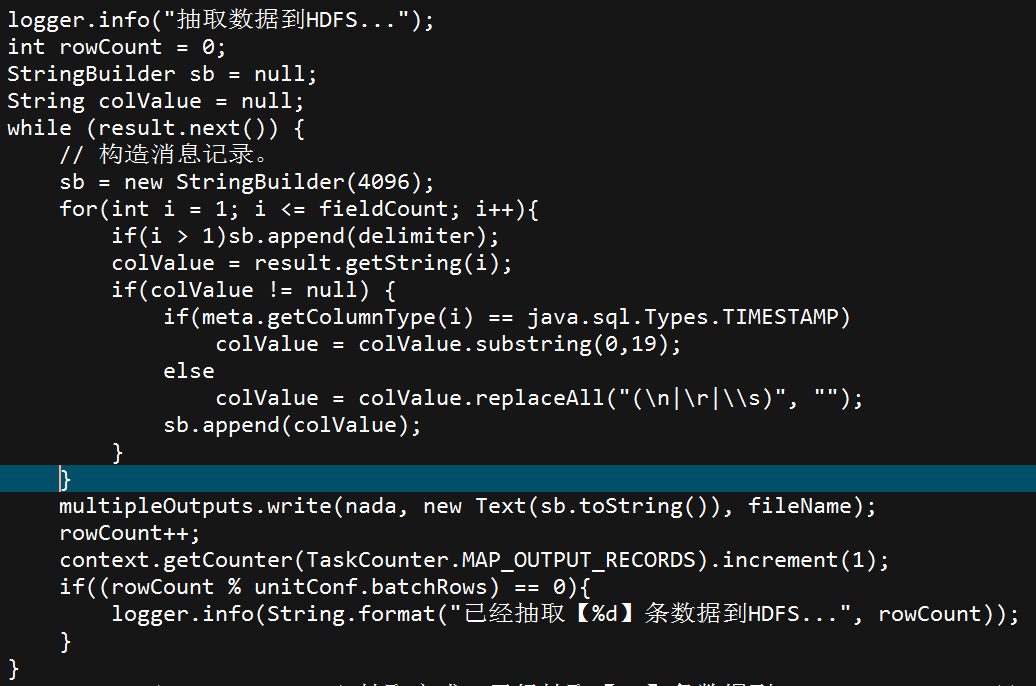
第二、Mapper task写入HDFS
1.3 创建梧桐云原生分析型数据库外部表
1、登录梧桐数据库
psql -h -p -U <用户名称> -d
2、创建外部表
psql> create readable external table tb_test1
( STATIS_DATE date,
…
fee1 number(12)
)
LOCATION ( ‘hdfs:///path/filename.txt’ )
FORMAT ‘TEXT’ ( DELIMITER ‘∈’ );
1.4 数据加载到正式表
insert into tb_test1 select * from ext_tb_test1;
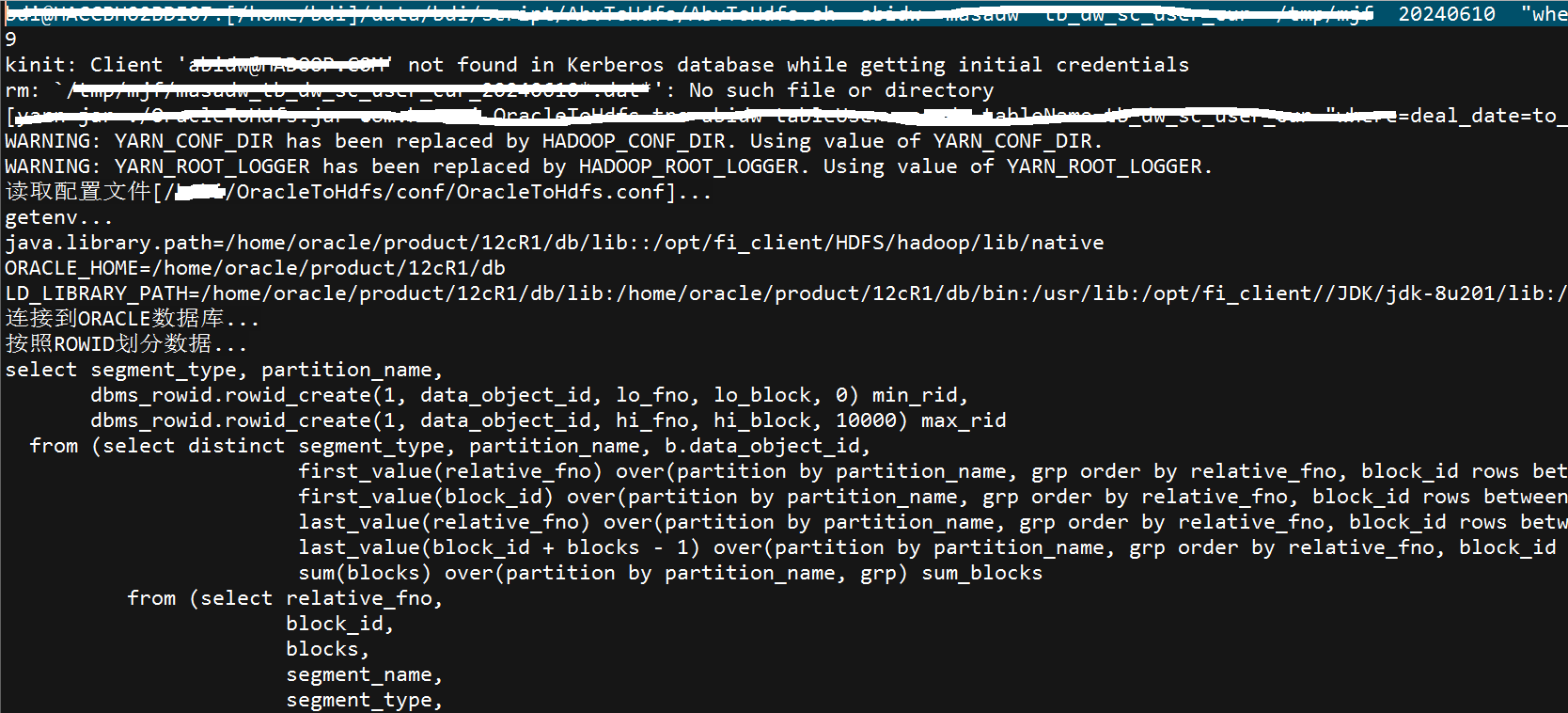
2、业务验证日志
Oracle数据迁移梧桐数据库验证日志如下图所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









