 Hive与梧桐云原生数据库数据加载对比测试
Hive与梧桐云原生数据库数据加载对比测试




一、测试目标和背景
某某公司系统部分O域入接口调度任务通过通过 LOAD DATA 的方式加载到 hive 数据仓库的。由于总公司对数据库平台国产化改造的要求,需要将这部分接口任务修改为适配国产梧桐云原生分析型数据库,为确保梧桐云原生分析型数据库能够正常承载这部分接口业务,需要对梧桐数据库和 Hive 进行数据加载能力的对比测试。
二、被测试软件概述
梧桐云原生分析型数据库作为云原生存算分离架构数据库,具备云原生、高性能、强兼容、高并发、纯国产等特性。
三、对标软件介绍
hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。hive 数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能。
四、测试环境
梧桐数据库:
WuTongDB:2.0
硬件配置:计算节点C3型服务器,存储节点B2型服务器
Hive数据仓库:
版本:3.1.0
存储节点612个,服务节点4个
五、测试方法
采用同一份数据源分别同时加载 hive 数据仓库和梧桐云原生分析型数据库。
hive 数据仓库通过 LOAD DATA 方式将数据文件移动到与 hive 表对应的位置的纯复制操作入库。
梧桐云原生分析型数据库通过外部表加载数据到正式表的方式入库。
六、测试用例
1、源文件内容和条数
HDFS文本文件包含有日期、数字,汉字,英文字符等,共有3亿条记录。
2、hive加载
Hive 数据仓库通过 LOAD DATA 移动 HDFS 文件到与 hive 表对应的位置进行入库。
3、梧桐云原生分析型数据库
梧桐云原生分析型数据库通过外部表映射 HDFS 文件,然后直接加载到正式表进行入库。
七、测试结果
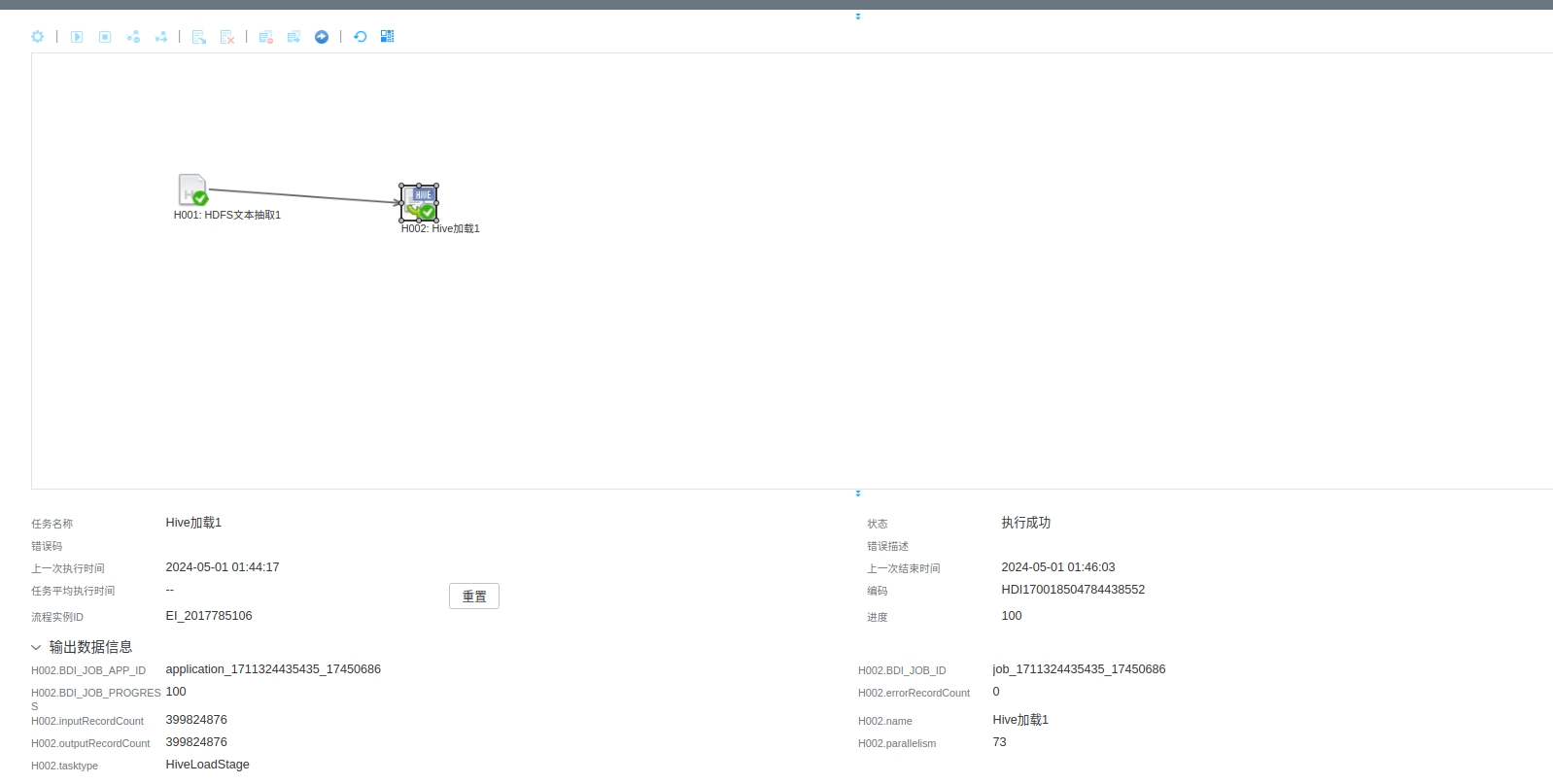
WuTongDB数据库加载结果显示:
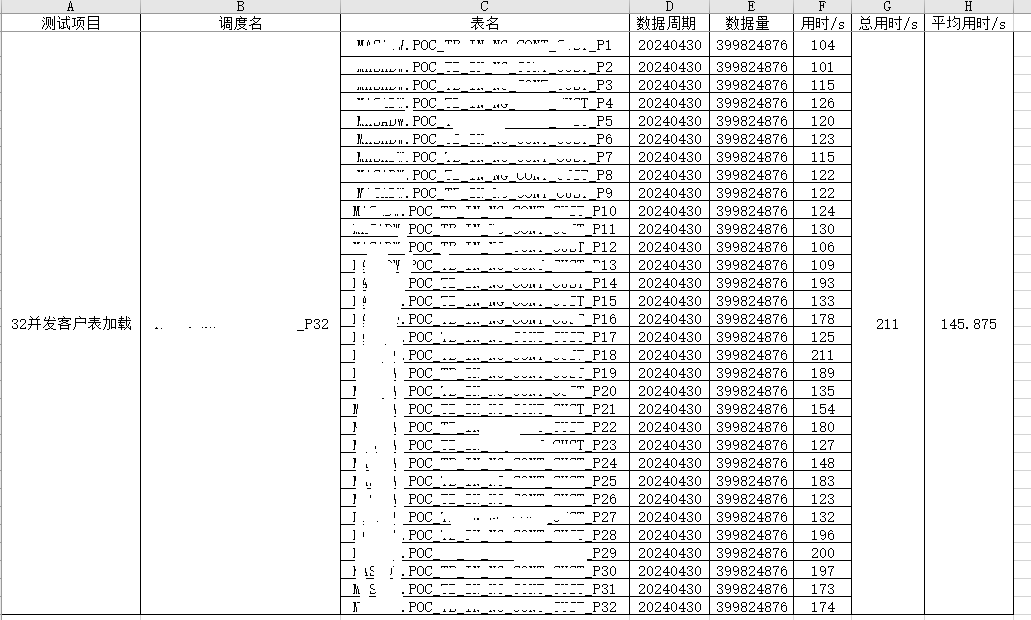
HIVE 数据库加载结果显示:
八、性能指标对比
hive数据库和梧桐云原生分析型数据库加载结果显示:

九、功能差异分析
hive数据仓库和梧桐云原生分析型数据库都是通过文件加载的方式入库的,功能一致。
十、缺陷和问题
1、梧桐数据加载过程存在无法实时监控数据加载进度。
十一、用户体验评价
梧桐云原生分析型数据库数据加载能力基本满足业务要求。
十二、结论和建议
通过 hive 数据仓库和梧桐云原生分析型数据库加载性能指标对比可以得出以下结论:
在相同的环境前提下,超大规模数据加载业务场景下,梧桐云原生分析型数据库加载和 hive 数据仓库加载运行效率差不多。
十三、附录
无


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









