



一、如何开发一个Servlet
1、步骤
1)、编写一个java类,继承自HttpServlet类
2)、重写doGet()方法和doPost()方法;
3)、Servlet程序交给tomcat服务运行(serlvet的class文件拷贝到WEB-INF/classes目录,在web.xml文件下配置)

<servlet>
<!-- servlet的内部名称,自定义。尽量有意义 -->
<servlet-name>Hello</servlet-name>
<display-name>This is the display name of my J2EE component</display-name>
<description>This is the description of my J2EE component</description>
<!-- servlet的类全名: 包名+简单类名 -->
<servlet-class>com.gqxing.servlet.Hello</servlet-class>
</servlet>
<servlet-mapping>
<!-- 需要和某一个servlet节点的servlet-name 子节点的文本节点一致 -->
<servlet-name>AServlet</servlet-name>
<!-- 映射具体的访问路径,/代表web应用的根目录 -->
<url-pattern>*.html</url-pattern>
</servlet-mapping>
注意:tomcat服务启动时,首先加载webapp中的每个web应用的web.xml配置文件
访问url: http://localhost:8080/Test/Hello
http://——> http协议
localhost——>到本地的hosts文件中查找是否存在该域名对应的IP地址
8080——> 通过端口号找到tomcat服务器
/Test ——> 在tomcat的webapps目录下找 Test的目录
Hello ——>资源名称
该过程可以如下描述:
1)在Test的web.xml中查找是否有匹配的url-pattern的内容(/Hello)
2)如果找到匹配的url-pattern,则使用当前servlet-name的名称到web.xml文件中查询是否相同名称的servlet(servlet-name)配置
3)如果找到,则取出对应的servlet配置信息中的servlet-class内容:
通过反射:
a)构造Hello的对象
b)然后调用Hello里面的方法
二、Servlet的映射路径
url-pattern 浏览器地址
精确匹配 /Hello/demo http://localhost:8080/Test/Hello/demo
模糊匹配 /* http://localhost:8080/Test/任意路径
*.后缀名 http://localhost:8080/day10/任意路径.后缀名
注意:
1)url-pattern要么以 / 开头,要么以*开头。 例如, itcast是非法路径。
2)不能同时使用两种模糊匹配,例如 /itcast/*.do是非法路径
3)当有输入的URL有多个servlet同时被匹配的情况下:
3.1 精确匹配优先。(长的最像优先被匹配)
3.2 以后缀名结尾的模糊url-pattern优先级最低!!!
缺省路径问题:
servlet的缺省路径(<url-pattern>/</url-pattern>)是在tomcat服务器内置的一个路径。该路径对应的是一个DefaultServlet(缺省Servlet)。这个缺省的Servlet的作用是用于解析web应用的静态资源文件。
问题: URL输入http://localhost:8080/Test/index.html 如何读取文件????
(当webroot目录下有一个index.html文件(诸如html、image等文件都是静态资源),同时还有一个index的servlet类(servlet是动态资源),在web.xml中为其配置了<url-pattern>/index.html</url-pattern>。此时该怎么访问!!!)
1)到当前day10应用下的web.xml文件查找是否有匹配的url-pattern。
2)如果没有匹配的url-pattern,则交给tomcat的内置的DefaultServlet处理
3)DefaultServlet程序到day10应用的根目录下查找是存在一个名称为index.html的静态文件。
4)如果找到该文件,则读取该文件内容,返回给浏览器。
5)如果找不到该文件,则返回404错误页面。
结论: 先找动态资源,再找静态资源。
三、Sevlet的生命周期
- Servlet 生命周期:Servlet 加载--->实例化--->服务--->销毁。
- init():在Servlet的生命周期中,仅执行一次init()方法。它是在服务器装入Servlet时执行的,负责初始化Servlet对象。可以配置服务器,以在启动服务器或客户机首次访问Servlet时装入Servlet。无论有多少客户机访问Servlet,都不会重复执行init()。
- service():它是Servlet的核心,负责响应客户的请求。每当一个客户请求一个HttpServlet对象,该对象的Service()方法就要调用,而且传递给这个方法一个“请求”(ServletRequest)对象和一个“响应”(ServletResponse)对象作为参数。在HttpServlet中已存在Service()方法。默认的服务功能是调用与HTTP请求的方法相应的do功能。
- destroy(): 仅执行一次,在服务器端停止且卸载Servlet时执行该方法。当Servlet对象退出生命周期时,负责释放占用的资源。一个Servlet在运行service()方法时可能会产生其他的线程,因此需要确认在调用destroy()方法时,这些线程已经终止或完成。
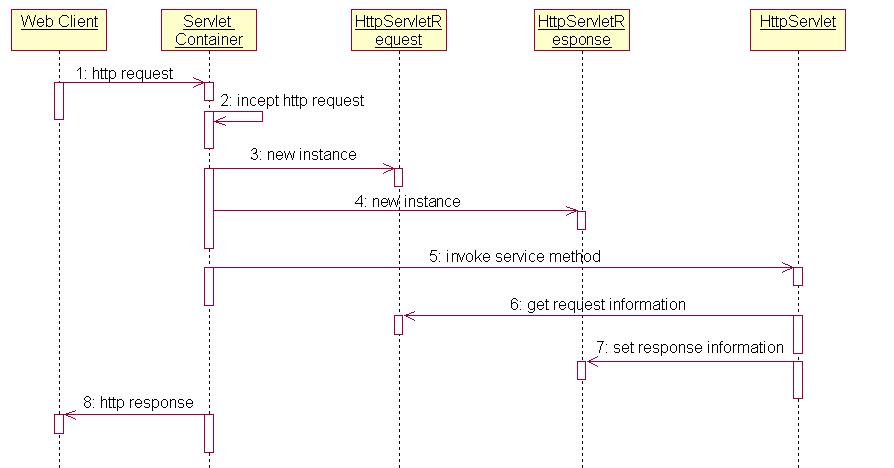
步骤:
- Web Client 向Servlet容器(Tomcat)发出Http请求
- Servlet容器接收Web Client的请求
- Servlet容器创建一个HttpRequest对象,将Web Client请求的信息封装到这个对象中。
- Servlet容器创建一个HttpResponse对象
- Servlet容器调用HttpServlet对象的service方法,把HttpRequest对象与HttpResponse对象作为参数传给 HttpServlet 对象。
- HttpServlet调用HttpRequest对象的有关方法,获取Http请求信息。
- HttpServlet调用HttpResponse对象的有关方法,生成响应数据。
- Servlet容器把HttpServlet的响应结果传给Web Client。

















 3260
3260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









