




1.概述
这篇主要讲一下C编码器的主要实现思路和主要注意事项。
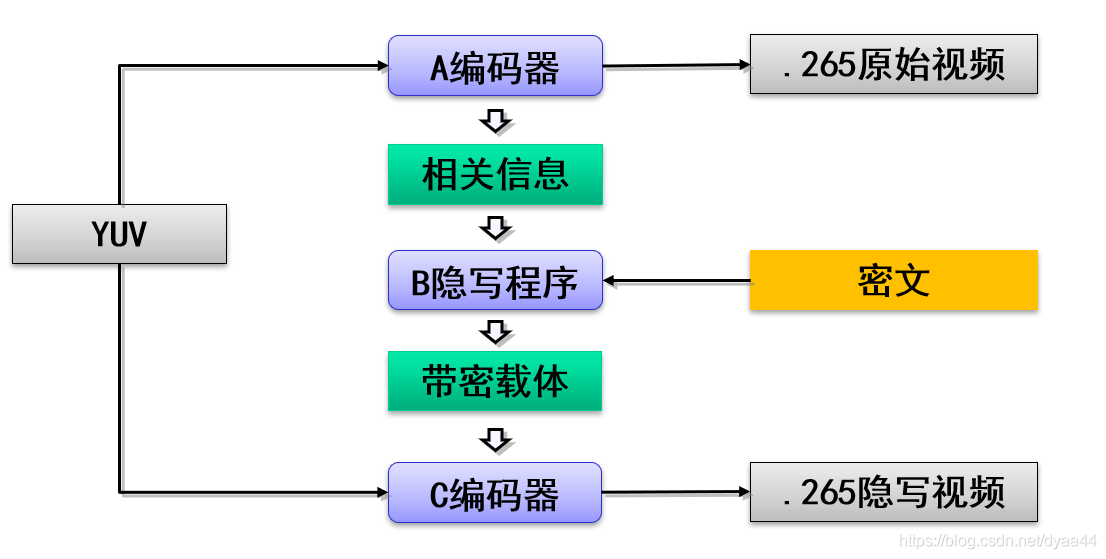
2.C编码器的基本思路
C编码器的主体流程图如下所示:
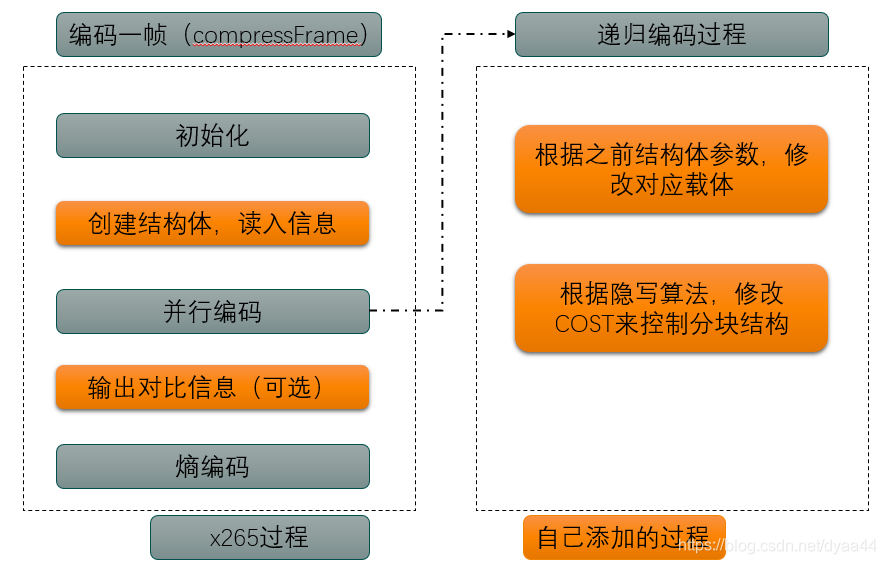
图中灰色的是X265原始的代码/函数,橙色是需要自己添加的代码。Compressframe是X265的编码一帧的函数,我们涉及到的最上层函数就是这个。在编码一帧的过程中,在这一层次,我们需要做三件事情:
- 创建并初始化根据ctu序号和cu序号定位的结构体数组。(所有取值按cu序号和ctu序号来,这样不会因为并行编码而取值混乱,切记不可用i++啥的定位)
- 在x265并行编码开始前,将所需信息读入结构体数组中。
- 在并行编码(修改过程)完成后,输出对应的载体信息,主要用于检测是否嵌入正确/这里是否能恢复密文/与后续解码提取过程提取出来的载体进行对比。(可选,可同时用之前提到elecard工具,在全部嵌入完成后,打开视频文件手动计算是否嵌入正确)
而在递归编码过程这一层次中,根据不同的算法,我们主要需要做两件事情:
- 根据之前结构体数组的值,修改对应载体
- 控制HEVC的分块结构,保证修改完载体不会被编码器用其他的块覆盖(不同隐写方式控制cost的方法稍有不同)。(分块模式隐写的话,这两步合并成一步)
根据帧内/帧间的不同,我们所需要修改的递归函数也不同,并且在帧间过程,其编码参数rd值也会影响X265所使用的递归函数,但主体思路都是一样的。
2.1 结构体数组的创建和读入数据
主体思路是模仿m_picCTU的创建方式,因此在framedata.h里面的class FrameData下,m_picCTU附近创建自己的变量,如
Dy_para* dy_p;
CUData* m_picCTU;
这个结构体我们可以简单的在里面创建所有所需要的的信息,比如我们需要所有的CU大小,PU类型和帧内模式的话,按创建3个数组即可。具体数目根据具体算法来。
struct Dy_para
{
int* dy_lumaIntraDir = NULL;
int* dy_log2CUSize = NULL;
int* dy_partSize = NULL;};
对这个结构体指针和里面的指针分别分配空间并初始化(在对应函数中完成,有些帧间算法需要的信息可能需要你在initsubcu里也添加对应的初始化,来完成参数的传递),然后读入你隐写算法的数据,当你可以在x265递归过程中看到你创建的结构体中的数据时,基本工作就完成了。
对于这样创建的指针,一个常见的在x265递归过程中取值的方法是:
cu.m_encData->dy_p[cu.m_cuAddr].dy_log2CUSize[cu.m_absIdxInCTU];
里面的cu是当前编码的cu的变量,在不同递归函数的位置,cu可以有很多种具体变量形式(这里按checkintra里给出)
输出对比信息和A编码器一样,就不展开讲述了。记住,不是输出自己创建的数组,而是x265内部的数组,m_开头的,不然就没有意义了,如
m_frame->m_encData->m_picCTU[numctu].m_log2CUSize[numintra]
2.2 递归编码过程—修改载体
这一部分和你所选取的载体非常相关,DCT系数/帧内模式/运动向量等等一系列载体的修改方式都不太一样,不过基本过程都是差不多的,主要能理解递归编码的递归顺序和cost比较覆盖的顺序的话,所有载体的修改都可以完成。
一般而言,所有预测过程和变换量化过程的载体,都是在checkxxxx过程中修改,然后checkBestxxx中比较对应cost,注意有addsplitflag之类在之后修改cost的地方。递归返回时会一层层的比较前一层和当前层的结果并保留。
在checkxxxx过程中,修改载体就是通过前述的结构体取值,判断现在进入checkxxx的函数的递归层数是否是我想要的层数,如果是,则把载体对应修改,比如:
cu.m_encData->dy_p[cu.m_cuAddr].dy_log2CUSize[cu.m_absIdxInCTU];
cu.m_encData->dy_p[cu.m_cuAddr].dy_partSize[cu.m_absIdxInCTU];
你可以通过取对应CU和PU的值和当前函数中指示cu,pu的变量比较来判断是否同一层次(dct需要多涉及tu的取值,过程是一样的)。注意这里log2CUSize和partSize的取值范围可能与当前函数中指示cu,pu的变量的范围不一致,不一定可以用直接相等来判断。
当一致时,修改对应载体。(注意,DCT/DST需要在刚刚量化完成,并且反量化之前修改,只能是这个位置)
2.3 递归编码过程—控制分块结构
不同的算法对分块结构的要求不一样。比如只嵌入4x4的算法,你只需要保证所有4x4的块位置和数量不变,不能增多也不能减少。一些分块结构算法和一部分全尺寸隐写算法则需要全修改/全保留分块结构。
基本思路是通过递归过程中,控制cost来完成。由于x265是在递归返回过程中,是将所有前一层递归的cost结果相加与当前层比较,所以只将你修改的块的cost改成0是不够的。举个例子,比如帧内,你修改了一个8x8块下的全部4x4的cost为0,当递归往上第一次时,全部4x4会保留,而当再往上递归时,是之前全部4x4和其他3块8x8的cost相加,如果你没修改所有的cost为0,那么有可能4x4会被16x16覆盖。但是根据算法,你不一定可以修改全部cost。因此,处理方式如下:
这是修改前某一Cost:
uint64_t rdCost; // sum of partition (psy) RD costs (sse(fenc, recon) + lambda2 * bits)
uint64_t sa8dCost;
这是修改后某一Cost:
int64_t rdCost; // sum of partition (psy) RD costs (sse(fenc, recon) + lambda2 * bits)
uint64_t sa8dCost;
主体思路是将你所需的cost修改为负值(如-999999),这样不论与其他任何数相加,结果将都为负值,这样保证了你修改块必然保留。因此需要注意对应变量的类型,从无符号改成有符号。
根据算法的不同,cost修改的地方稍有不同。大致都是在checkxxxx里面的函数修改完后,在checkxxx/compressintra inter里面也判断一次递归层次,相同的话修改对应cost为负数。
另外,需要注意所有addsplitflag的地方,这里会覆盖你修改的cost,在这个之后重新修改(帧间过程较多)。而在递归返回之后,splitPred也需要判断一次,是否层次符合,符合的话修改pred整体的cost为负值。
总结来说基本是两步,递归过程中判断层次修改cost,递归返回过程中,判断层次修改cost。

















 1341
1341


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








