




一、前言
虽然 Java 对线程的创建、中断、等待、通知、销毁、同步等功能提供了很多的支持,但是从操作系统角度来说,频繁的创建线程和销毁线程,其实是需要大量的时间和资源的。
例如,当有多个任务同时需要处理的时候,一个任务对应一个线程来执行,以此来提升任务的执行效率,模型图如下:
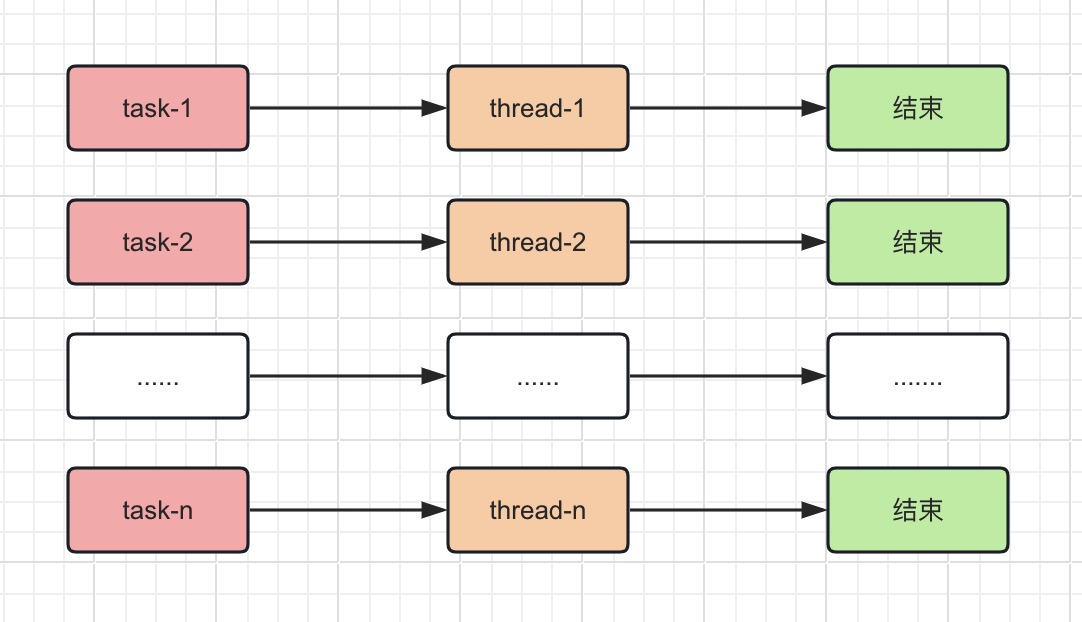
如果任务数非常少,这种模式倒问题不大,但是如果任务数非常的多,可能就会存在很大的问题:
- 1.线程数不可控:随着任务数的增多,线程数也会增多,这些线程都没办法进行统一管理
- 2.系统的开销很大:创建线程对系统来说开销很高,随着线程数也会增多,可能会出现系统资源紧张的问题,严重的情况系统可能直接死机
假如把很多任务让一组线程来执行,而不是一个任务对应一个新线程,这种通过接受任务并进行分发处理的就是线程池。
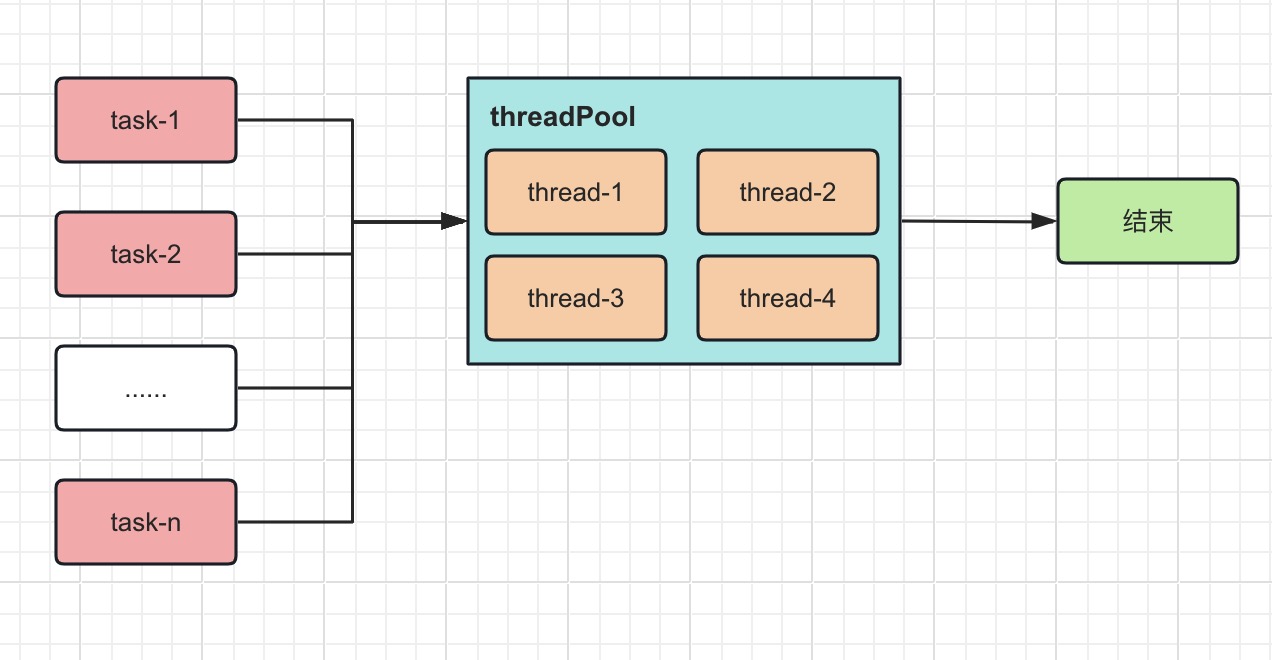
线程池内部维护了若干个线程,当没有任务的时候,这些线程都处于等待状态;当有新的任务进来时,就分配一个空闲线程执行;当所有线程都处于忙碌状态时,新任务要么放入队列中等待,要么增加一个新线程进行处理,要么直接拒绝。
很显然,这种通过线程池来执行多任务的思路,优势明显:
- 1.资源更加可控:能有效的控制线程数,防止线程数过多,导致系统资源紧张
- 2.资源消耗更低:因为线程可以复用,可以有效的降低创建和销毁线程的时间和资源
- 3.执行效率更高:当新的任务进来时,可以不需要等待线程的创建立即执行
关于这一点,我们可以看一个简单的对比示例。
/**
* 使用一个任务对应一个线程来执行
* @param args
*/
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
final Random random = new Random();
List<Integer> list = new CopyOnWriteArrayList<>();
// 一个任务对应一个线程,使用20000个线程执行任务
for (int i = 0; i < 20000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
list.add(random.nextInt(100));
}
}).start();
}
// 等待任务执行完毕
while (true){
if(list.size() >= 20000){
break;
}
}
System.out.println("一个任务对应一个线程,执行耗时:" + (System.currentTimeMillis() - startTime) + "ms");
}
/**
* 使用线程池进行执行任务
* @param args
*/
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
final Random random = new Random();
List<Integer> list = new CopyOnWriteArrayList<>();
// 使用线程池进行执行任务,默认4个线程
ThreadPoolExecutor executor = new ThreadPoolExecutor(4, 4, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(20000));
for (int i = 0; i < 20000; i++) {
// 提交任务
executor.submit(new Runnable() {
@Override
public void run() {
list.add(random.nextInt(100));
}
});
}
// 等待任务执行完毕
while (true){
if(list.size() >= 20000){
break;
}
}
System.out.println("使用线程池,执行耗时:" + (System.currentTimeMillis() - startTime) + "ms");
// 关闭线程池
executor.shutdown();
}
两者执行耗时情况对比,如下:
一个任务对应一个线程,执行耗时:3073ms
---------------------------
使用线程池,执行耗时:578ms
从结果上可以看出,同样的任务数,采用线程池和不采用线程池,执行耗时差距非常明显,一个任务对应一个新的线程来执行,反而效率不如采用 4 个线程的线程池执行的快。
为什么会产生这种现象,下面我们就一起来聊聊线程池。
二、线程池概述
站在专业的角度讲,线程池其实是一种利用池化思想来实现线程管理的技术,它将线程的创建和任务的执行进行解耦,同时复用已经创建的线程来降低频繁创建和销毁线程所带来的资源消耗。通过合理的参数设置,可以实现更低的系统资源使用率、更高的任务并发执行效率。
在 Java 中,线程池最顶级的接口是Executor,名下的实现类关系图如下:
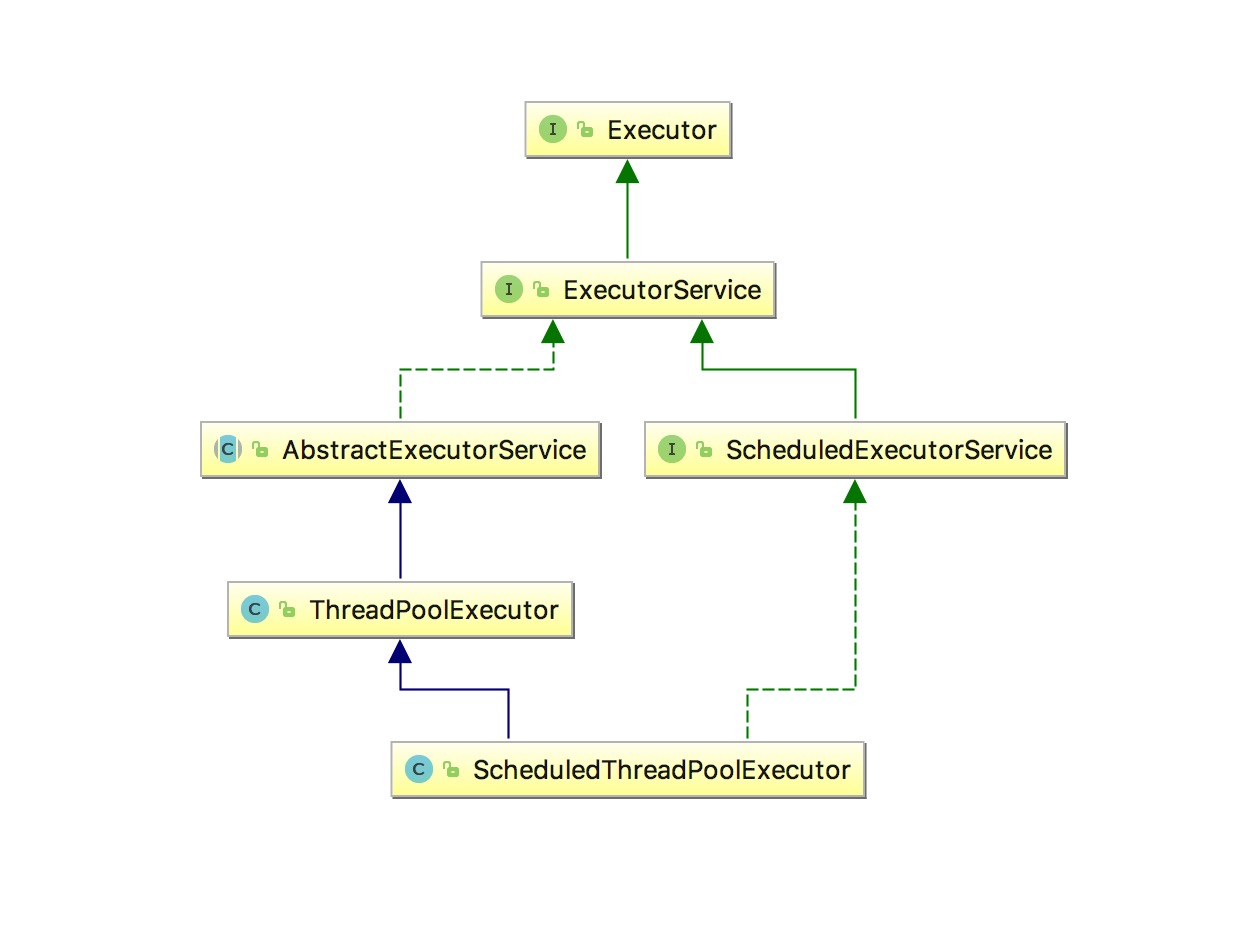
关键接口和实现类,相关的描述如下:
- 1.
Executor是最顶级的接口,它的作用是将任务的执行和线程的创建进行抽象解藕 - 2.
ExecutorService接口继承了Executor接口,在Executor的基础上,增加了一些关于管理线程池的一些方法,比如查看任务的状态、获取线程池的状态、终止线程池等标准方法 - 3.
ThreadPoolExecutor是一个线程池的核心实现类,完整的封装了线程池相关的操作方法,通过它可以创建线程池 - 4.
ScheduledThreadPoolExecutor是一个使用线程池的定时调度实现类,完整的封装了定时调度相关的操作方法,通过它可以创建周期性线程池
整个关系图中,其中ThreadPoolExecutor是线程池最核心的实现类,开发者可以使用它来创建线程池。
2.1、ThreadPoolExecutor 构造方法
ThreadPoolExecutor类的完整构造方法一共有七个参数,理解这些参数的配置对使用好线程池至关重要,完整的构造方法核心源码如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
各个参数的解读如下:
- corePoolSize:核心线程数量,用于执行任务的核心线程数。
- maximumPoolSize:最大线程数量,线程池中允许创建线程的最大数量
- keepAliveTime:空闲线程存活的时间。只有当线程池中的线程数大于 corePoolSize 时,这个参数才会起作用
- unit:空闲线程存活的时间单位
- workQueue:任务队列,用于存储还没来得及执行的任务
- threadFactory:线程工厂。用于执行任务时创建新线程的工厂
- handler:拒绝策略,当线程池和和队列容量处于饱满,使用某种策略来拒绝任务提交
2.2、ThreadPoolExecutor 执行流程
创建完线程池之后就可以提交任务了,当有新的任务进来时,线程池就会工作并分配线程去执行任务。
ThreadPoolExecutor的典型用法如下:
// 创建固定大小的线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(4, 4, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(100));
// 提交任务
executor.execute(task1);
executor.execute(task2);
executor.execute(task3);
...
针对任务的提交方式,ThreadPoolExecutor还提供了两种方法。
execute()方法:一种无返回值的方法,也是最核心的任务提交方法submit()方法:支持有返回值,通过FutureTask对象来获取任务执行完后的返回值,底层依然调用的是execute()方法
ThreadPoolExecutor执行提交的任务流程虽然比较复杂,但是通过对源码的分析,大致的任务执行流程,可以用如下图来概括。
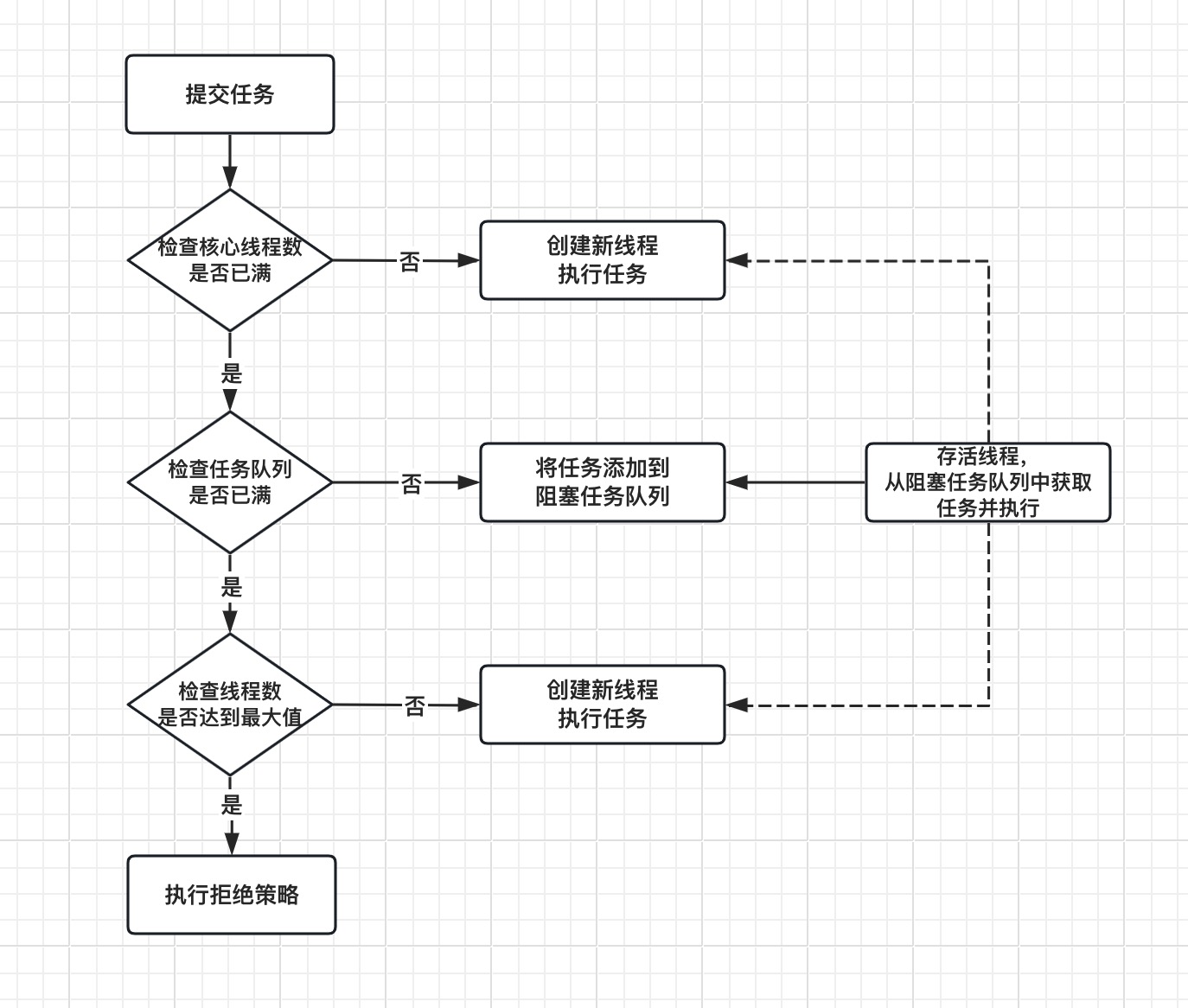
整个执行流程,大体步骤如下:
- 1.初始化完线程池之后,默认情况下,线程数为0,当有任务到来后才会创建新线程去执行任务
- 2.每次收到提交的任务之后,会先检查核心线程数是否已满,如果没有,就会继续创建新线程来执行任务,直到核心线程数达到设定值
- 3.当核心线程数已满,会检查任务队列是否已满,如果没有,就会将任务存储到阻塞任务队列中
- 4.当任务队列已满,会再次检查线程池中的线程数是否达到最大值,如果没有,就会创建新的线程来执行任务
- 5.如果任务队列已满、线程数已达到最大值,此时线程池已经无法再接受新的任务,当收到任务之后,会执行拒绝策略
我们再回头来看上文提到的ThreadPoolExecutor构造方法中的七个参数,这些参数会直接影响线程的执行情况,各个参数的变化情况,可以用如下几点来概括:
- 1.当线程池中的线程数小于 corePoolSize 时,新任务都不排队而是直接创新新线程来执行
- 2.当线程池中的线程数大于等于 corePoolSize,workQueue 未满时,将新任务添加到 workQueue 中而不是创建新线程来执行
- 3.当线程池中的线程数大于等于 corePoolSize,workQueue 已满,但是线程数小于 maximumPoolSize 时,此时会创建新的线程来处理被添加的任务
- 4.当线程池中的线程数大于等于 maximumPoolSize,并且 workQueue 已满,新任务会被拒绝,使用 handler 执行被拒绝的任务
ThreadPoolExecutor执行任务的部分核心源码如下!
2.2.1、execute 提交任务
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 工作线程数量 < corePoolSize,直接创建线程执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









