




 本文详细介绍了Python3中的模块和包的概念及使用,包括模块的作用、创建、导入方式,以及深入探讨了模块搜索路径、编译后文件、标准模块、包的结构和导入机制。此外,还讲解了dir()函数、从包中导入模块的规则,并提供了模块加载流程图,帮助读者理解Python的模块系统。
本文详细介绍了Python3中的模块和包的概念及使用,包括模块的作用、创建、导入方式,以及深入探讨了模块搜索路径、编译后文件、标准模块、包的结构和导入机制。此外,还讲解了dir()函数、从包中导入模块的规则,并提供了模块加载流程图,帮助读者理解Python的模块系统。
查看全部 Python3 基础教程
认识模块
解决的问题
- 退出 Python 解释器后,以前创建的一切定义(变量和函数)就全部丢失了。因此,对于要长久保存的程序,最好用文本编辑器来编写并保存到文件中,把保存好的文件作为输入交给解释器运行,这叫做创建一个脚本。
- 当程序变得更长一些,为了方便维护可以把它分成几个文件。
- 想要在几个程序中都使用一个常用的函数,但是不想复制它的定义到每一个程序里。
为了满足这些需要,Python 提供了一个方式可以将定义放在文件中,并在脚本或解释器的交互式实例中使用它们。这样的文件称为模块;模块中的定义可以导入到其他模块或主模块中(在顶层执行的脚本和计算器模式中可以访问的变量集合)。
模块是一个包含 Python 定义和语句的文件。文件名就是模块名加上 .py 后缀。在模块中,模块的名称(作为字符串)可以由全局变量 __name__ 得到。
示例
在当前目录中创建一个名为 fibo.py 的文件:
# Fibonacci numbers module
def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a+b
return result
进入 Python 解释器,用如下命令导入这个模块:
>>> import fibo
这样做不会直接在当前的符号表中引入定义在 fibo 模块中的函数,它只是引入了模块名 fibo。可以通过模块名按如下方式访问其函数:
>>> fibo.fib(1000)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
>>> fibo.fib2(100)
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
>>> fibo.__name__
'fibo'
如果打算经常使用一个函数,则可以给它分配一个本地名称:
>>> fib = fibo.fib
>>> fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
深入模块
模块可以包含可执行语句和函数定义。这些语句用于初始化该模块,且仅在 import 该模块时执行,或者当文件作为脚本执行时,也会运行这些语句。
事实上,函数定义可以看作“已执行”的“语句”,执行模块层面的函数定义会引入函数名称到模块的全局符号表中。
每个模块都有自己的专用符号表,其被模块中定义的所有函数用作全局符号表。因此,模块的作者可以在模块中使用全局变量,而不必担心与用户的全局变量发生意外冲突。另一方面,如果有需要,可以像引用模块中的函数一样获取模块中的全局变量,形如:modname.itemname。
模块可以导入其他模块。习惯上所有的 import 语句都放在模块(或该脚本)的开头,但这并不是必须的。导入的模块名称被放置在导入模块的全局符号表中。
import 语句的变体:直接导入模块的命名实体到导入模块的符号表中。例如:
>>> from fibo import fib, fib2
>>> fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这种不会把模块名称引入到本地符号表中,如上
fibo并没有定义。
import 语句的变体:导入模块中定义的所有名称。例如:
>>> from fibo import *
>>> fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这种会导入除那些以下划线
_开头的所有名称。多数情况下 Python 程序员不会使用这个工具,因为它在解释器中引入了一组未知的名称,可能还会掩盖自己已经定义的一些东西。
注意,通常不赞成从模块或包导入*,因为它经常会降低代码的可读性。但是,在交互式会话中可以使用它节省输入。
如果模块名称后跟 as,则 as 后面的名称将直接绑定到导入的模块。
>>> import fibo as fib
>>> fib.fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这种方式与导入
fibo模块方式相同,唯一区别就是可以作为fib使用。
用类似效果使用 from 时也可以用到它:
>>> from fibo import fib as fibonacci
>>> fibonacci(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
注意:出于效率原因,每个模块在每个解释器会话中只会被导入一次。因此,如果更改了模块,则必须重新启动解释器。或者,如果它只是一个要在交互模式下测试的模块,则可以使用 importlib.reload(),例如:
import importlib
importlib.reload(modulename)
将模块作为脚本执行
python fibo.py <arguments>
可以用以上方式运行一个 Python 模块,就像导入该模块一样,但会把 __name__ 设置为 "__main__",这意味着会在模块的末尾添加如下代码:
if __name__ == "__main__":
import sys
fib(int(sys.argv[1])) # 解析命令行
可以使用该文件作为脚本和可导入的模块,因为只有当该模块作为 main 文件执行时,解析命令行的代码才会运行。
$ python fibo.py 50
0 1 1 2 3 5 8 13 21 34
如果导入的模块不会自动运行代码,这通常用于提供用户接口,或用于测试目的(将该模块作为执行测试套件的脚本来运行)。
>>> import fibo
>>>
模块搜索路径
当导入一个名为 spam 的模块时,解释器首先在内置模块中查找该名称,如果没找到,就会在由变量 sys.path 给定的目录列表中查找名为 spam.py 的文件。
sys.path 变量的初始化位置:
- 包含该输入脚本的目录,如果没指定文件,就是当前目录;
- PYTHONPATH,一个由若干目录名组成的列表,语法同 shell 变量
path一样; - 安装相关的默认值。
注意:在支持符号链接的文件系统上,在遵循符号链接之后会计算包含输入脚本的目录。换句话说,包含符号链接的目录不会添加到模块搜索路径中。
初始化后,Python 程序可以修改 sys.path。在模块搜索路径上,正在运行的脚本所在的目录位于搜索路径的开头,在标准库路径的前面,如果脚本目录和库目录中有同名模块,加载该模块时,将从脚本目录中加载,而不是库目录中的同名模块。因此,如果不是刻意要替换标准模块,应尽量避免脚本和库目录模块重名。
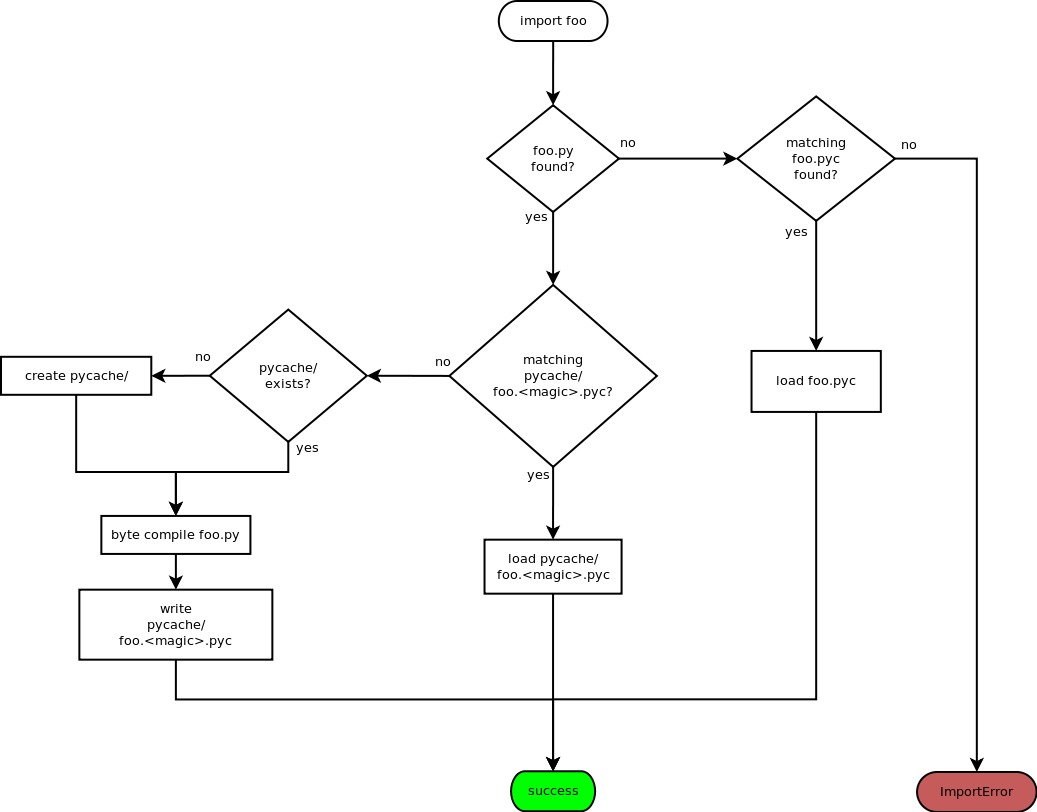
编译后的 Python 文件
为了提高模块加载速度,Python 会将每个模块以 module.version.pyc 的名称缓存在 __pycache__ 目录中,其中的 version 编码了编译文件的格式,通常包括了 Python 的版本号。例如,在 CPython release 3.3 中,spam.py 将会缓存为 __pycache__/spam.cpython-33.pyc。这种命名约定可以让不同 release 和 version 的 Python 编译的模块共存。
Python 会根据编译后的版本检查源代码的修改时间确定其是否过期,过期的话则重新编译,这是一个全自动的过程。此外,编译后的模块是独立于平台的,因此可以在不同架构的系统之间共享相同的库。
Python 在两种情况下不检查缓存:
- 首先,它总是重新编译而不存储直接从命令行加载的模块的结果。
- 其次,如果没有源模块,它将不检查缓存。要支持
非源(仅编译)的 distribution,编译的模块必须位于源目录中,并且不能有源模块。
给专家的一些建议:
-
可以在 Python 命令上用 -O 或 -OO 开关减小一个编译模块的大小。
-O开关会移除assert语句,-OO开关既移除assert语句,也移除__doc__字符串。应该在了解程序是否需要这些的前提下使用这个开关。“优化”模块有一个opt-标签且通常较小,未来的版本可能会改变优化的效果。 -
从
.pyc文件读取的程序不会比其从.py文件读取运行速度更快,但.pyc文件但加载速度更快。 -
模块 compileall 可以在某个目录中为所有模块创建
.pyc文件。 -
详情参考 PEP 3147.
模块加载流程图:
标准模块
Python 附带一个标准模块库,详见单独的文档 Python 库参考(以下称为“库参考”)。一些模块内置于解释器之中,这些模块提供非语言核心操作的访问接口,或是为了效率,或是为了给系统调用等操作系统原生访问提供接口。这类模块集合是一个依赖于底层平台的配置选项。例如,winreg 模块仅在 Windows 系统上提供。
要注意一个特别模块:sys,它被内置到每个 Python 解释器中,变量 sys.ps1 和 sys.ps2 定义了主提示符和辅助提示符的字符串:
>>> import sys
>>> sys.ps1
'>>> '
>>> sys.ps2
'... '
>>> sys.ps1 = 'C> '
C> print('Yuck!')
Yuck!
C>
仅当解释器在交互模式时,才定义这两个变量。
变量 sys.path 是解释器模块搜索路径的字符串列表。它由环境变量 PYTHONPATH 初始化,如果没有设定 PYTHONPATH ,就由内置的默认值初始化。可以使用标准列表操作来修改它:
>>> import sys
>>> sys.path.append('/ufs/guido/lib/python')
dir() 函数
内置函数 dir() 用于列出某个模块定义的命名实体,它返回一个有序的字符串列表。
>>> import fibo, sys
>>> dir(fibo)
['__name__', 'fib', 'fib2']
>>> dir(sys)
['__breakpointhook__', '__displayhook__', '__doc__', '__excepthook__',
'__interactivehook__', '__loader__', '__name__', '__package__', '__spec__',
'__stderr__', '__stdin__', '__stdout__', '__unraisablehook__',
'_clear_type_cache', '_current_frames', '_debugmallocstats', '_framework',
'_getframe', '_git', '_home', '_xoptions', 'abiflags', 'addaudithook',
'api_version', 'argv', 'audit', 'base_exec_prefix', 'base_prefix',
'breakpointhook', 'builtin_module_names', 'byteorder', 'call_tracing',
'callstats', 'copyright', 'displayhook', 'dont_write_bytecode', 'exc_info',
'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info',
'float_repr_style', 'get_asyncgen_hooks', 'get_coroutine_origin_tracking_depth',
'getallocatedblocks', 'getdefaultencoding', 'getdlopenflags',
'getfilesystemencodeerrors', 'getfilesystemencoding', 'getprofile',
'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval',
'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
'intern', 'is_finalizing', 'last_traceback', 'last_type', 'last_value',
'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks',
'path_importer_cache', 'platform', 'prefix', 'ps1', 'ps2', 'pycache_prefix',
'set_asyncgen_hooks', 'set_coroutine_origin_tracking_depth', 'setdlopenflags',
'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr',
'stdin', 'stdout', 'thread_info', 'unraisablehook', 'version', 'version_info',
'warnoptions']
无参调用时,dir() 将返回一个当前已定义的命名列表。
>>> a = [1, 2, 3, 4, 5]
>>> import fibo
>>> fib = fibo.fib
>>> dir()
['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys']
注意,以上列出了所有类型实体的名称,如变量、模块、函数等。
dir() 函数不会列出内置函数和变量的名称,它们定义在标准模块 builtins 中。
>>> import builtins
>>> dir(builtins)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException',
'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning',
'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError',
'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning',
'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False',
'FileExistsError', 'FileNotFoundError', 'FloatingPointError',
'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError',
'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError',
'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError',
'MemoryError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented',
'NotImplementedError', 'OSError', 'OverflowError',
'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError',
'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning',
'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError',
'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError',
'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError',
'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning',
'ValueError', 'Warning', 'ZeroDivisionError', '_', '__build_class__',
'__debug__', '__doc__', '__import__', '__name__', '__package__', 'abs',
'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable',
'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits',
'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit',
'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr',
'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass',
'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview',
'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property',
'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice',
'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars',
'zip']
包
包使用圆点模块名称的方式来结构化模块命名空间。例如,模块 A.B 表示子模块 B 位于包 A 中。就像不同模块的作者不必担心彼此的全局变量命名会冲突,使用圆点模块名称的方式让 NumPy 或 Pillow 等多模块包的作者不必担心彼此的模块命名会冲突。
假设要设计一个模块集(一个“包”)来统一处理声音文件和声音数据。声音格式有许多,通常根据其扩展名来标识,例如:.wav, .aiff, .au,于是,为了在不同文件格式之间转换,就需要创建并维护一个不断增长的模块集合。可能还要对声音数据做很多不同的操作,例如混音、添加回声、应用平衡功能、创建一个人造效果,所以还要编写一个没完没了的模块流来执行这些操作。
下面是包的可能结构(用分层文件系统表示):
sound/ Top-level package
__init__.py Initialize the sound package
formats/ Subpackage for file format conversions
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ Subpackage for sound effects
__init__.py
echo.py
surround.py
reverse.py
...
filters/ Subpackage for filters
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
导入模块时,Python 通过 sys.path 中的目录列表来搜索存放包的子目录。
目录中必须要有 __init__.py 文件,Python 才会把该目录当作包。这是为了防止某些目录使用了 string 这样的通用名而无意中在随后的模块搜索路径中覆盖了正确的模块。最简单的情况下,__init__.py 可以只是一个空文件,不过它也可以包含包的初始化代码或设置 __all__ 变量。
从包中导入单个模块:
import sound.effects.echo
这样就加载了子模块 sound.effects.echo,必须用全限定名来引用它:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
另一种导入子模块的方式:
from sound.effects import echo
这样就加载了子模块 echo,使用它不需要包前缀:
echo.echofilter(input, output, delay=0.7, atten=4)
还有另一种方式可以直接导入所需函数或变量:
from sound.effects.echo import echofilter
这样再次加载了子模块 echo,但这次可以直接使用它的函数 echofilter():
echofilter(input, output, delay=0.7, atten=4)
注意使用
from package import item时,这个item既可以是包中的一个子模块(或子包),也可以是包中定义的其它命名,像函数、类或变量。import语句首先检查包中是否有这个item,如果没有,它会假定这是一个模块并尝试加载它,如果没有找到它,就会引发一个 ImportError 异常。
与之相反,当使用类似import item.subitem.subsubitem的语法时,最后的item可以是包或模块,但不能是前面item中定义的类、函数或变量,而其他item必须是包。
从包中导入 *
用户输入 from sound.effects import *,希望能以某种方式进入文件系统,找到包中存在的子模块并全部导入它们。这可能需要很长时间,且导入子模块可能会产生不必要的副作用,而这些副作用本该在显式导入子模块时才会发生。
唯一的解决方案是让包作者提供包的显式索引。import 语句使用以下约定:如果包的 __init__.py 代码定义了名为 __all__ 的列表,该列表会被作为当遇到 from package import * 时应导入的模块名称列表。当包的新版本发布时,包的作者必须保持这个列表为最新状态。如果包作者没见到对自己的包有 from package import * 的用法,他们也许会决定不支持它。
例如,文件 sound/effects/__init__.py 可以包含以下代码:
__all__ = ["echo", "surround", "reverse"]
这表示
from sound.effects import *会从sound包中导入以上三个已命名的子模块。
如果没有定义 __all__,语句 from sound.effects import * 就不会从 sound.effects 包导入全部的子模块到当前命名空间,它只确保 sound.effects 包已经被导入(可能会运行 __init__.py 中的初始化代码),然后导入定义在该包中的任何名称。这包括 __init__.py 定义的任何名称以及它显式加载的任何子模块,还包括以前的 import 语句显式加载的该包的任何子模块。
考虑以下代码:
import sound.effects.echo
import sound.effects.surround
from sound.effects import *
在本例中,当
from...import语句被执行时,会导入echo和surround模块到当前命名空间中,因为它们定义在sound.effects包中。当定义了__all__时,同样会如此。
虽然某些模块被设计成在使用 import * 时只导出遵循特定模式的名称,但这在生产代码中仍然被认为是错误的做法。
使用 from package import specific_submodule 是没有问题的,实际上推荐这么做,除非导入的模块需要使用其它包中的同名子模块。
内部包引用
当包结构中有子包时,如同前面例子中的 sound 包,就可以使用绝对导入来引用兄弟包的子模块。例如,如果模块 sound.filters.vocoder 需要使用 sound.effects 包中的 echo 模块,可以使用 from sound.effects import echo。
还可以用 from module import name 的导入语句形式进行相对导入。这些导入使用前导点符号来表示相对导入中涉及的当前包和父级包。
例如,从 surround 模块中,可以使用:
from . import echo
from .. import formats
from ..filters import equalizer
注意,相对导入是基于当前模块名的。由于主模块的名称总是
__main__,因此打算用作 Python 应用程序主模块的模块必须始终使用绝对导入。
多重路径中的包
包还支持另外一个特殊属性,即 __path__,该属性会被初始化为一个目录名列表,然后这些目录中的包的 __init__.py 文件代码会被执行。可以修改此变量,这将影响之后对包中的模块和子包的搜索。
虽然这个功能不常需要,但它能用于扩展包中的模块集。

















 4574
4574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









