






 本文深入探讨了Gated Recurrent Units (GRU),这是为简化LSTM而提出的模型。介绍了GRU的两个关键门限:更新门和重置门,以及它们如何帮助解决长距离依赖和梯度消失问题。
本文深入探讨了Gated Recurrent Units (GRU),这是为简化LSTM而提出的模型。介绍了GRU的两个关键门限:更新门和重置门,以及它们如何帮助解决长距离依赖和梯度消失问题。
循环神经网络 3(Gated RNN - GRU)
LSTM 是1997年就提出来的模型,为了简化LSTM的复杂度,在2014年 Cho et al. 提出了 Gated Recurrent Units (GRU)。接下来,我们在LSTM的基础上,介绍一下GRU。
主要思路是:
• keep around memories to capture long distance dependencies
• allow error messages to flow at different strengths depending on the inputs
1. Gate 公式
相对于LSTM, GRU 的门限减少到2个gate(LSTM是3个)
(1) Update Gate
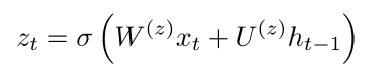
如果 update 接近于1,我们就直接copy以前的信息到现在的输入,有效地防止了梯度消失。
(2) Resst Gate
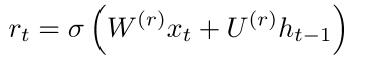
如果reset 接近于0,意味着忘记以前的hidden state。
(3) New memory content
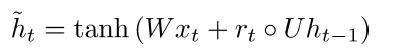
(4) Final memory
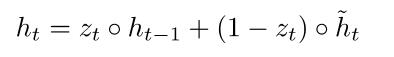
2.基础架构
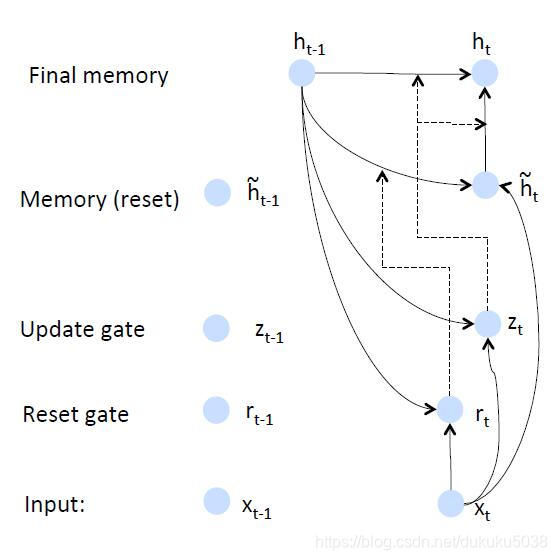
通过基础架构可以看出来,GRU比LSTM实现简单,但是最终的效果,二者不相上下。

本专栏图片、公式很多来自台湾大学李弘毅老师、斯坦福大学cs229,斯坦福大学cs231n 、斯坦福大学cs224n课程。在这里,感谢这些经典课程,向他们致敬!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









