RDD、DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同。
RDD和DataFrame
RDD-DataFrame
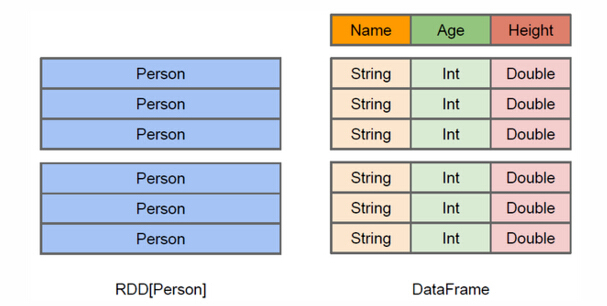
上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解 Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的 Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
DataFrame和DataSet
Dataset可以认为是DataFrame的一个特例,主要区别是Dataset每一个record存储的是一个强类型值而不是一个Row。因此具有如下三个特点:
DataSet可以在编译时检查类型
并且是面向对象的编程接口。用wordcount举例:
//DataFrame
// Load a text file and interpret each line as a java.lang.String
val
ds
=
sqlContext
.
read
.
text
(
"/home/spark/1.6/lines"
)
.
as
[
String
]
val
result
=
ds
.
flatMap
(
_
.
split
(
" "
)
)
// Split on whitespace
.
filter
(
_
!=
""
)
// Filter empty words
.
toDF
(
)
// Convert to DataFrame to perform aggregation / sorting
.
groupBy
(
$
"value"
)
// Count number of occurences of each word
.
agg
(
count
(
"*"
)
as
"numOccurances"
)
.
orderBy
(
$
"numOccurances"
desc
)
// Show most common words first
后面版本DataFrame会继承DataSet,DataFrame是面向Spark SQL的接口。
//DataSet,完全使用scala编程,不要切换到DataFrame
val
wordCount
=
ds
.
flatMap
(
_
.
split
(
" "
)
)
.
filter
(
_
!=
""
)
.
groupBy
(
_
.
toLowerCase
(
)
)
// Instead of grouping on a column expression (i.e. $"value") we pass a lambda function
.
count
(
)
DataFrame和DataSet可以相互转化, df.as[ElementType] 这样可以把DataFrame转化为DataSet, ds.toDF() 这样可以把DataSet转化为DataFrame。
DataFrame是一个组织成命名列的数据集。它在概念上等同于关系数据库中的表或R/Python中的数据框架,但其经过了优化。DataFrames可以从各种各样的源构建,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。DataFrame API 可以被Scala,Java,Python和R调用。在Scala和Java中,DataFrame由Rows的数据集表示。在Scala API中,DataFrame只是一个类型别名Dataset[Row]。而在Java API中,用户需要Dataset<Row>用来表示DataFrame。在本文档中,我们经常将Scala/Java数据集Row称为DataFrames。
那么DataFrame和spark核心数据结构RDD之间怎么进行转换呢?
代码如下:
from __future__ import print_function from pyspark.sql import SparkSession from pyspark.sql import Row if __name__ == "__main__" : spark = SparkSession \ .builder \ .appName("RDD_and_DataFrame" ) \ .config("spark.some.config.option" , "some-value" ) \ .getOrCreate() sc = spark.sparkContext lines = sc.textFile("employee.txt" ) parts = lines.map(lambda l: l.split( "," )) employee = parts.map(lambda p: Row(name=p[ 0 ], salary=int(p[ 1 ]))) employee_temp = spark.createDataFrame(employee) employee_temp.show() employee_temp.createOrReplaceTempView("employee" ) employee_result = spark.sql("SELECT name,salary FROM employee WHERE salary >= 14000 AND salary <= 20000" ) result = employee_result.rdd.map(lambda p: "name: " + p.name + " salary: " + str(p.salary)).collect() for n in result: print (n)





 本文探讨了Spark中RDD、DataFrame和DataSet的概念及其差异。详细解释了DataFrame如何提供额外的结构信息来提高执行效率,并展示了如何使用Scala进行编程。此外,还介绍了DataFrame和DataSet之间的转换方法。
本文探讨了Spark中RDD、DataFrame和DataSet的概念及其差异。详细解释了DataFrame如何提供额外的结构信息来提高执行效率,并展示了如何使用Scala进行编程。此外,还介绍了DataFrame和DataSet之间的转换方法。


















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









