




 本文详细介绍了如何在Ubuntu 20.04虚拟机中安装Hadoop,包括创建Hadoop用户、安装Java 1.8、设置SSH免密登录、下载安装Hadoop并进行伪分布式配置。通过这些步骤,可以在本地通过xshell连接并管理Hadoop服务。
本文详细介绍了如何在Ubuntu 20.04虚拟机中安装Hadoop,包括创建Hadoop用户、安装Java 1.8、设置SSH免密登录、下载安装Hadoop并进行伪分布式配置。通过这些步骤,可以在本地通过xshell连接并管理Hadoop服务。
基于VM虚拟机下Ubuntu系统中Hadoop安装与详细配置
准备工作
需要有一个虚拟机里的ubuntu系统,我的是20.04版本。
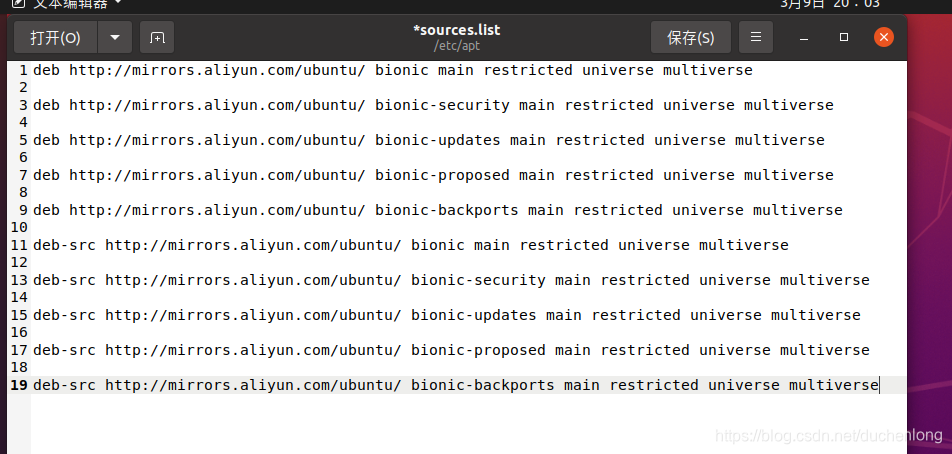
- 更换为阿里的源
# 备份原有的源
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
# 修改原文件权限为可编辑
sudo chmod 777 /etc/apt/sources.list
# 使用gedit打开,并清空里面内容
sudo gedit /etc/apt/sources.list
# 更换里面内容为阿里的源
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
# 更新
sudo apt update
sudo apt upgrade
- 配置xshell远程连接
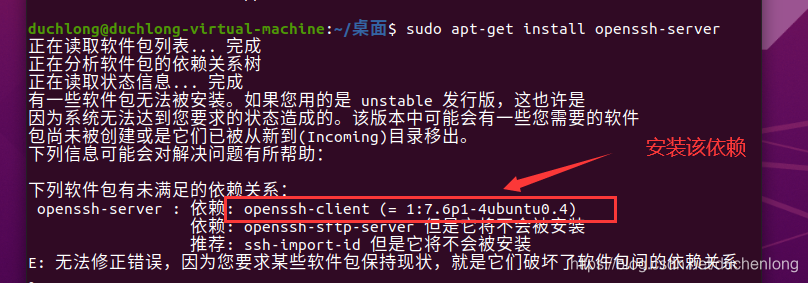
# 需要先安装该依赖 (后面跟着系统需要,可能不同)
sudo apt install openssh-client=1:7.6p1-4ubuntu0.4
# 再安装openssh
sudo apt-get install openssh-server
然后就可以在xshell中进行连接了
- 安装文件传输的工具
sudo apt install lrzsz
- 关闭防火墙( 不用单独开辟端口
sudo ufw disable
创建Hadoop用户
# 创建Hadoop用户,并使用/bin/bash作为shell
sudo useradd -m hadoop -s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+





 到【灌水乐园】发言
到【灌水乐园】发言







