




 本文介绍了如何使用梯度下降算法求解单变量线性回归模型的局部最小值,详细阐述了线性回归模型代价函数的特殊性,即其为凸函数只有一个最小值。同时,通过可视化展示了梯度下降过程,并提到了批量梯度下降法与其他参数求解方法的对比。
本文介绍了如何使用梯度下降算法求解单变量线性回归模型的局部最小值,详细阐述了线性回归模型代价函数的特殊性,即其为凸函数只有一个最小值。同时,通过可视化展示了梯度下降过程,并提到了批量梯度下降法与其他参数求解方法的对比。
1、使用梯度下降算法来求解线性回归模型的局部最小值

在前面,我们已经得到了单变量线性回归模型的假设函数hθ(x)h_{\theta}(x)hθ(x)和采用均方误差的代价函数J(θ0,θ1)J(\theta_{0},\theta_{1})J(θ0,θ1),如图1右半部分所示,现在我们用梯度下降来求解使代价函数获得局部最小的对应参数值,如图2所示:
将假设函数的具体形式代入梯度下降算法的核心公式,更新θ0\theta_{0}θ0和θ1\theta_{1}θ1
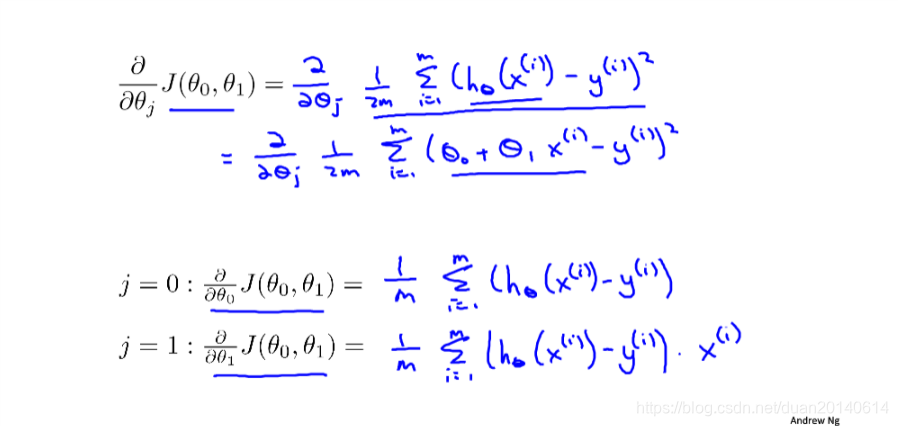
循环参数的更新过程,直至收敛:

收敛的可视化过程如下所示:
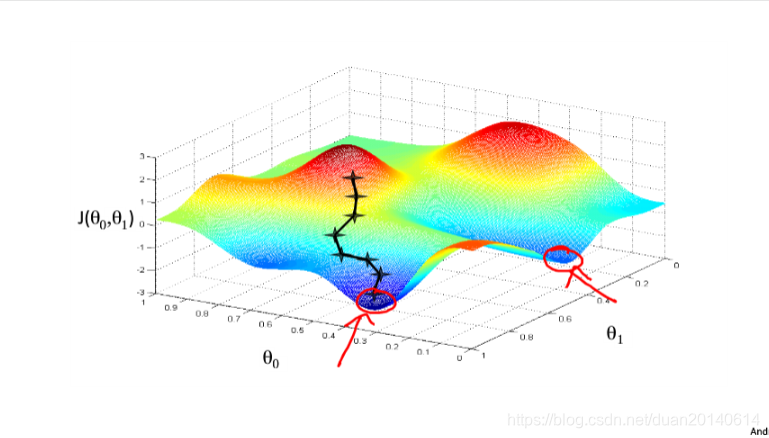
2、线性回归模型的代价函数的特殊性
从图3中我们可以发现一个问题,当代价函数有多个局部最小值时,只要在梯度下降的过程中方向出现了一点偏差,最后收敛到的局部最小值可能完全不同,如上图红色箭头所示。
但是,对于线性回归模型而言,根本不会存在这个问题,因为他的代价函数是一个凸函数(图4所示),仅有一个局部最小值,
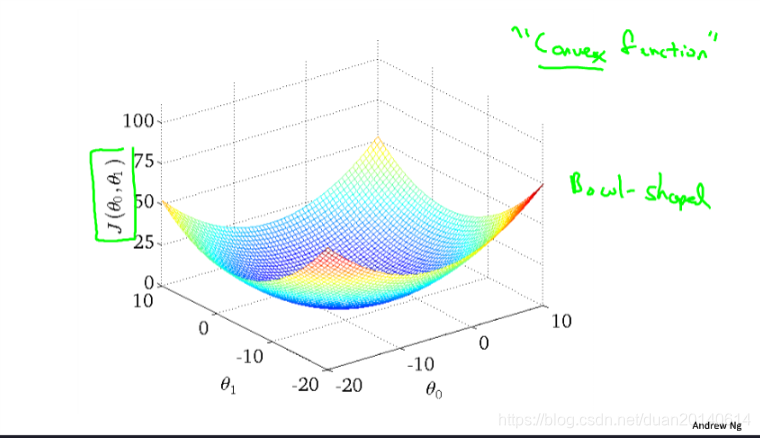
3、梯度下降算法在执行过程中假设函数对数据的拟合情况
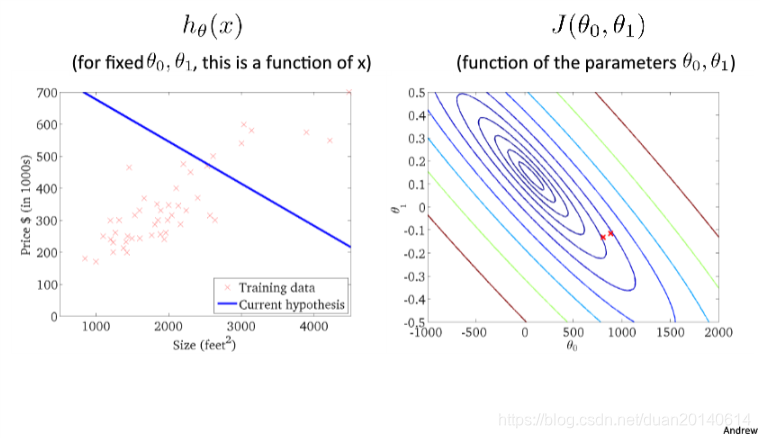
(1)初始值
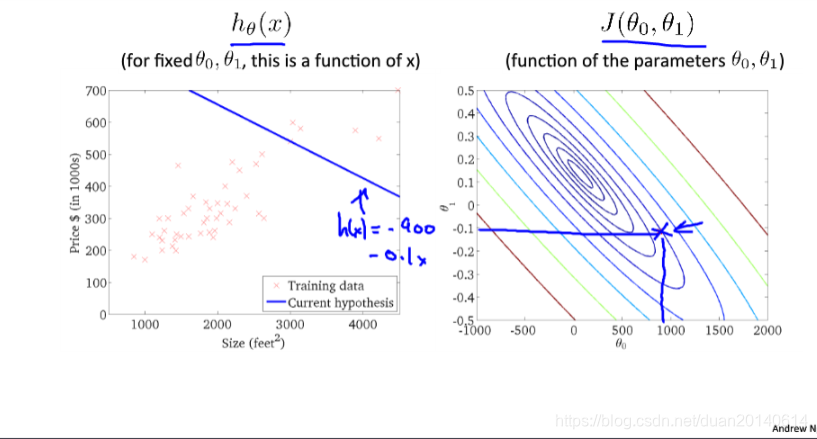
(2)第一次迭代
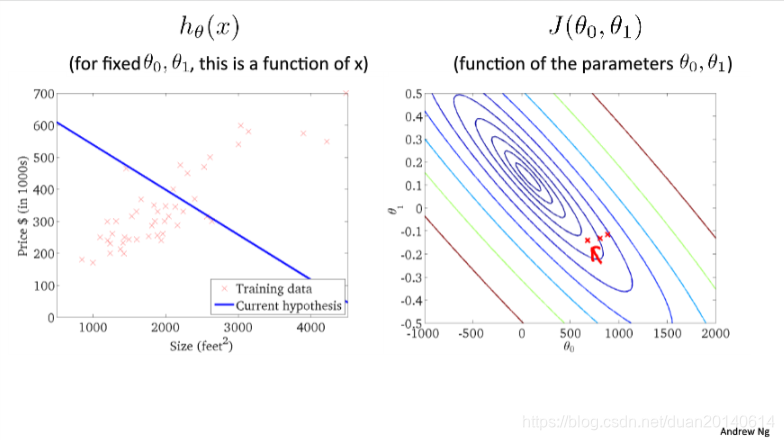
(3)第二次迭代
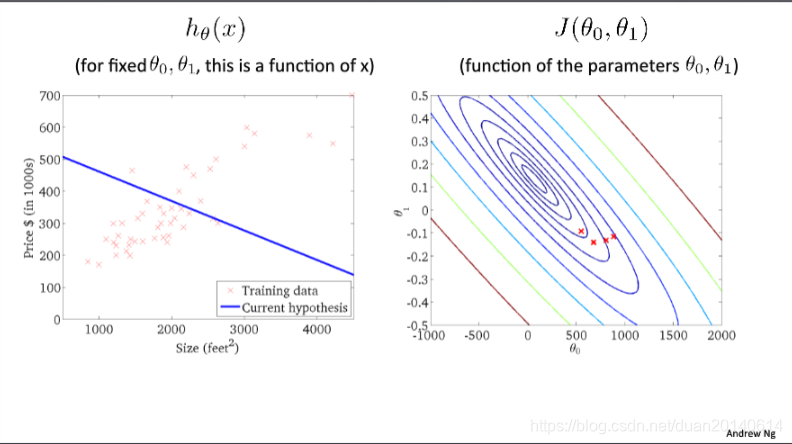
(4)第三次迭代
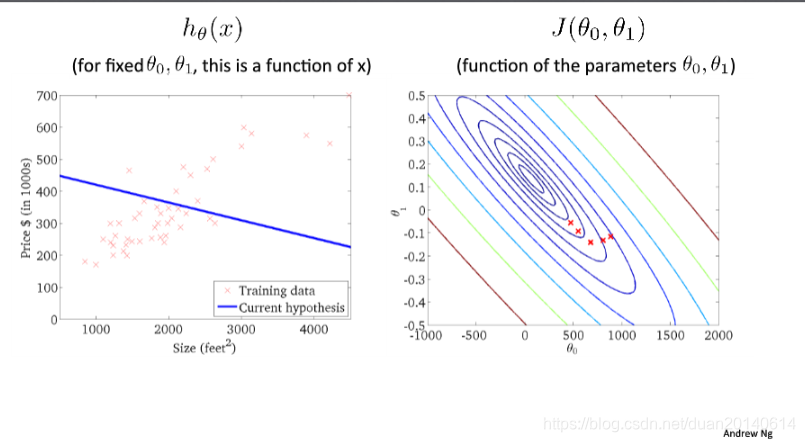
(5)第四次迭代
(6)第五次迭代
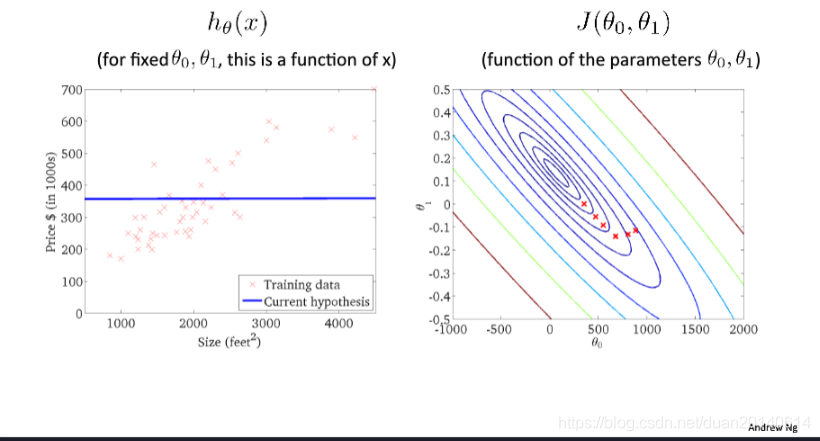
(7)第六次迭代
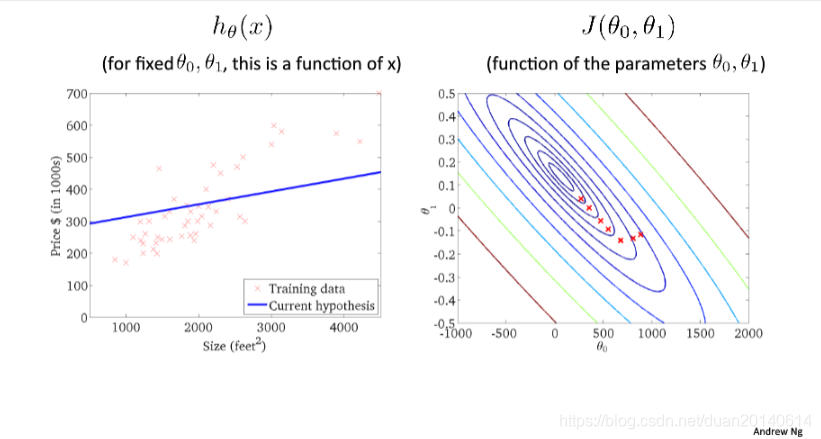
(8)第七次迭代
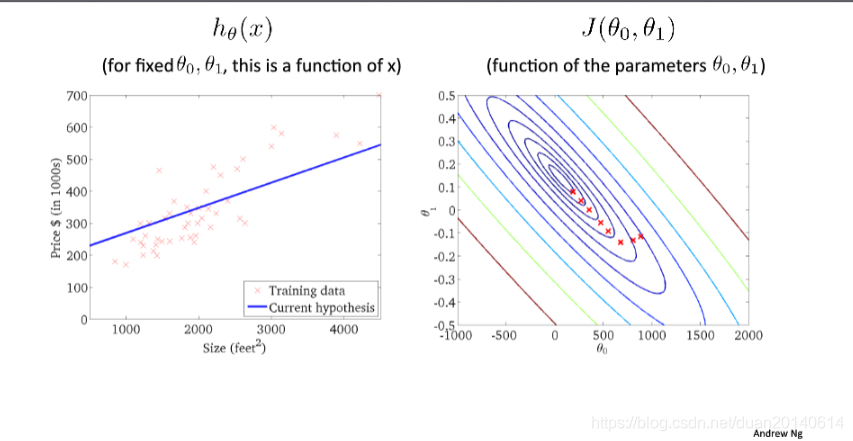
(9)第八次迭代
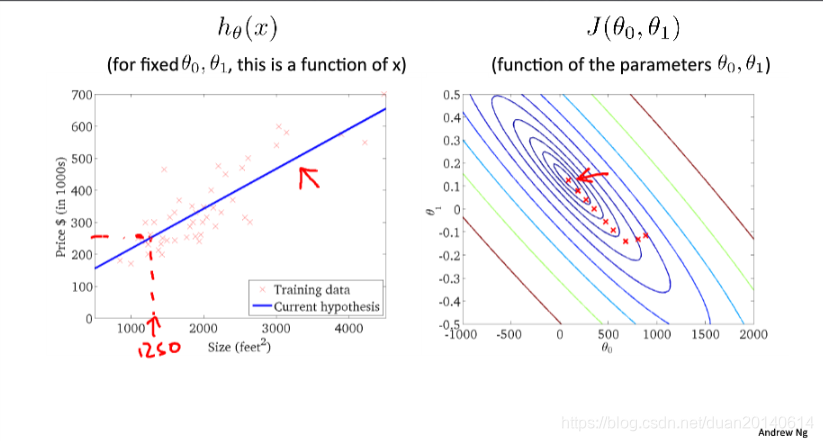
4、批量梯度下降(batch gradient descent,BGD)

批量梯度下降是指每一次迭代更新参数时,使用所有的训练样本。
5、参数求解的其他方法
事实上,参数学习还有很多方法,比如正规方程法,它和梯度下降的区别在于:
正规方程在小规模数据集上速度很快,而梯度下降法在大规模数据集上更有优势。


















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











