




 这篇博客介绍了如何使用pandas的DataFrame.corr()函数计算数据集中的列与列之间的相关系数,并探讨了不同相关系数的含义。示例中展示了相关系数矩阵及其与线性相关性的关系。此外,还提到了scatter_matrix函数用于绘制散点图矩阵,帮助理解变量间的关系,特别是在房价分析案例中,强调了房价与收入的相关性较强。
这篇博客介绍了如何使用pandas的DataFrame.corr()函数计算数据集中的列与列之间的相关系数,并探讨了不同相关系数的含义。示例中展示了相关系数矩阵及其与线性相关性的关系。此外,还提到了scatter_matrix函数用于绘制散点图矩阵,帮助理解变量间的关系,特别是在房价分析案例中,强调了房价与收入的相关性较强。
DataFrame.corr(method=‘pearson’, min_periods=1)
计算列与列之间的相关系数,返回相关系数矩阵
- method : {‘pearson’, ‘kendall’, ‘spearman’}
- pearson : standard correlation coefficient
- kendall : Kendall Tau correlation coefficient
- spearman : Spearman rank correlation
解释:相关系数的取值范围为[-1, 1],当接近1时,表示两者具有强烈的正相关性,比如‘s’和‘x’;当接近-1时,表示有强烈的的负相关性,比如‘s’和‘c’,而若值接近0,则表示相关性很低.
代码:
allDf = pd.DataFrame({
'x':[0,1,2,4,7,10],
'y':[0,3,2,4,5,7],
's':[0,1,2,3,4,5],
'c':[5,4,3,2,1,0]
},index = ['p1','p2','p3','p4','p5','p6'])
# print(allDf)
corr_matrix = allDf.corr()
print(corr_matrix)
out:
x y s c
x 1.000000 0.941729 0.972598 -0.972598
y 0.941729 1.000000 0.946256 -0.946256
s 0.972598 0.946256 1.000000 -1.000000
c -0.972598 -0.946256 -1.000000 1.000000
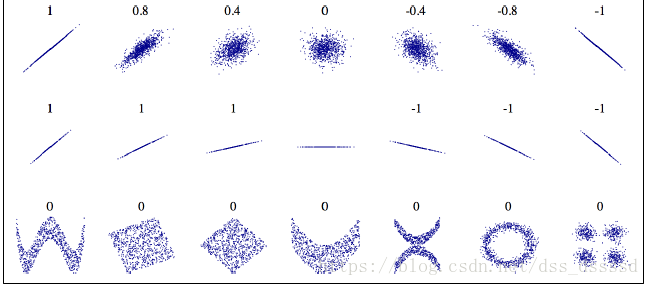
注意: 这里的相关性指的是线性相关性,下图是一些简单的例子:
数字为相关系数,数字下面为数据图形展示
接下来是房价分析的例子:
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
out:
median_house_value 1.000000
median_income 0.687160
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population -0.026920
longitude -0.047432
latitude -0.142724
Name: median_house_value, dtype: float64
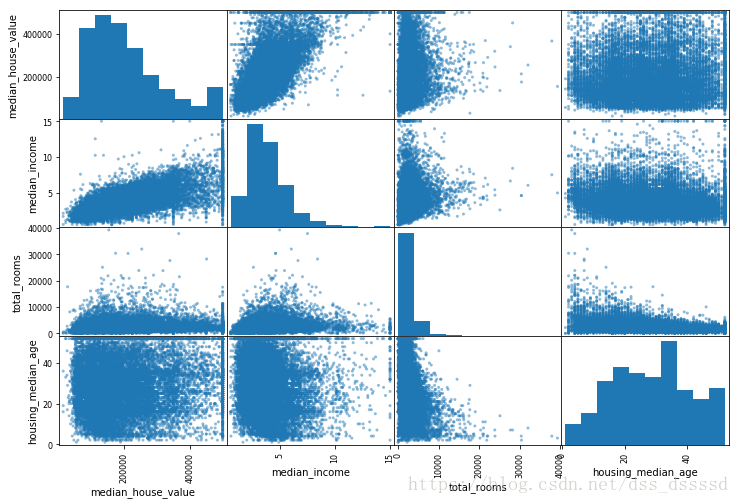
可以看出,房价与收入有比较强的相关性,而与纬度的相关性很低。
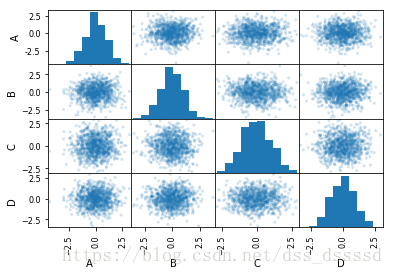
scatter_matrix
pandas.plotting.scatter_matrix(frame, alpha=0.5, figsize=None, ax=None, grid=False, diagonal=‘hist’, marker=’.’, density_kwds=None, hist_kwds=None, range_padding=0.05, **kwds)
画任意两列数值属性的散点图,最后画一个散点图的矩阵,对角线为分布直方图。
- figsize 图片大小
df = DataFrame(np.random.randn(1000, 4), columns=['A','B','C','D'])
scatter_matrix(df, alpha=0.2)
继续分析房价的例子,通过计算相关系数,只看几个与房价相关性较大的数据
from pandas.tools.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))

















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









