




 本文介绍了决策树的基本概念,包括信息熵的定义及其计算公式,信息增益的概念及其在特征选择中的应用。此外还讨论了决策树处理连续特征的方法,以及防止过拟合的策略和技术参数。
本文介绍了决策树的基本概念,包括信息熵的定义及其计算公式,信息增益的概念及其在特征选择中的应用。此外还讨论了决策树处理连续特征的方法,以及防止过拟合的策略和技术参数。
1.什么是信息熵?其计算公式是什么?
信息的量化。
一条信息的信息量和它的不确定性有直接关系。一个问题不确定性越大,要搞清楚这个问题,需要了解的信息就越多,其信息熵越大。
公式:
2.什么是信息增益?
特征划分数据集前后信息熵的变化值。
3.在决策树创建过程中,用什么办法来选择特征,从而进行数据集的划分?
选择信息增益最大的特征
4.决策树如何处理连续值的特征?
对连续数值离散化
5.除了信息增益外,还有什么标准可以用来选择决策树的特征?
基尼不纯度
6.解决决策树过拟合的方法有哪些?
前剪枝,后剪枝
7.DecisionTreeClassifier提供了哪些参数来解决决策树过拟合问题?
max_depth,min_samples_split,min_samples_leaf,max_leaf_nodes,min_impurity_split
8.运行ch07.02.ipynb的实例代码,试着考察min_samples_split这个参数的变化与模型准确性的关系。
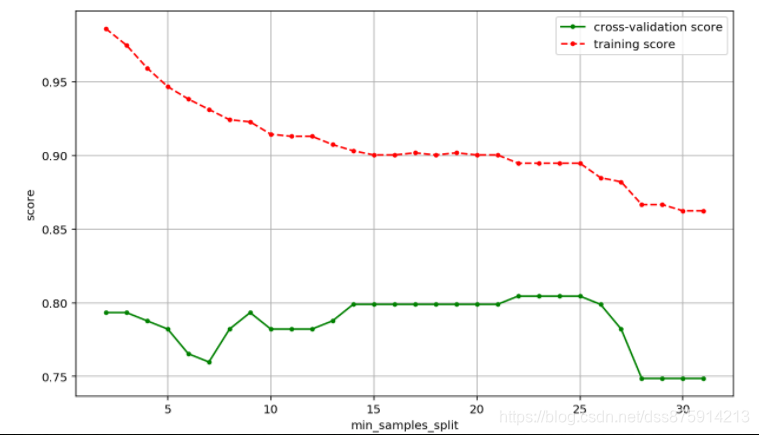
9.请读者登录https://www.kaggle.com,注册一个账号。以ch07.02.ipynb代码为基础,按照https:www.kaggle.com/c/titanic#evaluation的要求,计算test.csv的预测值,并把结果提交到kaggle.com上。
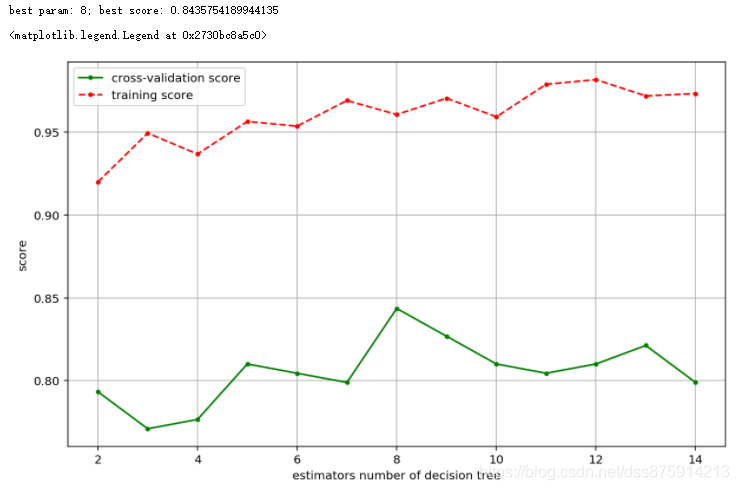
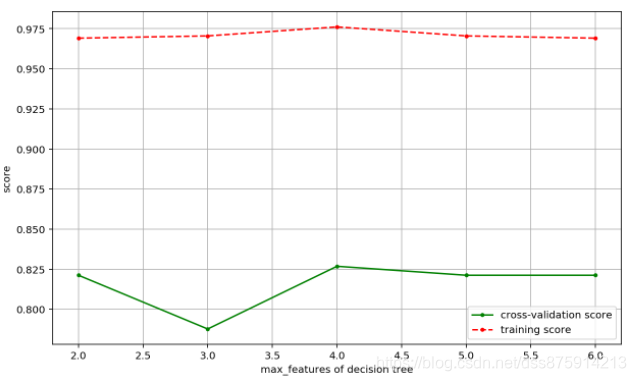
10.针对本章的预测泰坦尼克号幸存者数据集,使用随机森林对模型进行训练,观察训练出的模型的准确性和稳定性。

















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









