



一、零基础视角拆解核心知识点(通俗版)
先把上文中的核心概念、结构体、功能拆解成 “人话”,确保初学者能看懂每一个部分的作用和意义:
1. 先理解核心目标:单片机通信协议解析到底是干啥?
你可以把单片机之间 / 单片机和电脑之间的通信,想象成两个人打电话:
-
两个人说同一种语言(比如都讲中文)= 双方约定好通信协议(就是我们定义的帧头、长度、CRC、帧尾规则);
-
打电话时先喊 “喂,是小明吗?”(确认对方)= 协议里的帧头(0xAA+0x55);
-
接着说 “我要讲 3 句话”(告诉对方要听多少内容)= 协议里的数据长度;
-
然后说具体内容(“今天下雨、记得带伞、晚上吃火锅”)= 协议里的数据负载;
-
说完加一句 “我说的没错吧”(验证内容没传错)= 协议里的CRC 校验;
-
最后说 “拜拜”(表示说完了)= 协议里的帧尾(0x0D)。
我们写的代码,本质就是让单片机 “听懂” 这套 “通话规则”,能准确接收对方说的话,还能检查有没有听错(CRC 校验),听错了就重新听,没听错就处理内容。
2. 拆解核心代码模块(初学者能懂的解释)
|
代码模块 |
通俗解释 |
|---|---|
|
CRC16 计算函数(crc16_calc) |
给一段数据 “算个验证码”。发送方算好验证码一起发,接收方重新算一遍,对比验证码是否一致,一致就说明数据没传错。 |
|
解析器状态枚举(parse_state_t) |
给单片机的 “接收过程” 分阶段:比如 “先等对方喊喂→再等确认身份→再听要讲多少内容→再听具体内容→再验证验证码→最后等拜拜”,每个阶段就是一个 “状态”。 |
|
解析器结构体(proto_parser_t) |
给单片机准备一个 “小本子”,用来记:1. 当前听到哪个阶段了(state);2. 对方说的具体内容记下来(data_buf);3. 对方说要讲多少内容(data_len);4. 对方发的验证码是多少(recv_crc);5. 已经记了多少内容(buf_idx)。 |
|
初始化函数(proto_parser_init) |
通话前把 “小本子” 清空,让单片机从 “等待对方喊喂” 这个阶段开始准备。 |
|
单字节解析函数(proto_parse_byte) |
单片机每次只接 1 个字节(比如只听到 “喂”),这个函数就是判断 “当前该做什么”:比如听到 “喂” 就等下一句,听到 “拜拜” 就验证验证码,错了就清空本子重新来。 |
|
打包函数(proto_pack_frame) |
单片机要说话时,按 “喂→说长度→说内容→算验证码→说拜拜” 的顺序,把要讲的话打包成一串,方便发送。 |
3. 为什么要用这些结构(初学者最容易问的问题)
- 为什么用枚举(enum)?
不用记数字(比如用 1 代表等帧头、2 代表等长度),而是用 “STATE_WAIT_HEADER1” 这种一看就懂的名字,代码读起来像 “说人话”,不容易写错,也方便改。
- 为什么用结构体(struct)?
把和 “接收数据” 相关的所有信息(状态、缓存、长度等)放在一起,像一个 “打包文件”,不用零散记很多变量,比如要传这些信息时,直接传结构体就行,不用传 10 个单独的变量。
- 为什么用状态机(分阶段接收)?
单片机接收数据是 “一个字节一个字节来” 的,不可能一次性收到完整的一帧。状态机就像 “按步骤办事”,比如没听到 “喂” 之前,就算收到其他内容也不理,避免接收到错误数据。
- 为什么要 CRC 校验?
单片机通信(比如串口)容易受干扰(比如电线、电磁影响),数据可能传错(比如把 “3” 传成 “8”)。CRC 就是给数据做个 “指纹”,指纹对不上就说明数据错了,直接扔了重新接,保证数据准确。
二、初学者需要学习的核心知识(按优先级排序)
要能看懂、写得出上面的代码,初学者需要按以下顺序学习,每一步都打牢基础:
1. 必学基础(核心中的核心)
-
C 语言核心语法(优先级最高):
-
基本类型:
uint8_t/uint16_t(单片机常用的无符号 8 位 / 16 位整数,比 int 更精准); -
数组:理解
data_buf[MAX_DATA_LEN]是 “存数据的格子”,知道数组索引(buf_idx)怎么用; -
结构体(struct):理解 “把相关变量打包” 的思想,会定义、初始化、访问结构体成员(比如
parser->state); -
枚举(enum):理解 “给数字起名字” 的作用,会定义和使用;
-
函数:会写带参数、带返回值的函数(比如
crc16_calc),理解函数的输入输出; -
条件判断(if/else)、循环(for/while):状态机的核心逻辑全靠这两个,必须熟练。
-
-
单片机基础:
-
串口通信原理:知道单片机怎么通过串口发 / 收字节(比如 UART 的基本工作方式);
-
中断概念:理解 “串口接收中断”—— 数据来了单片机自动触发处理,而不是一直等(这是实时解析的关键);
-
内存常识:知道单片机的 RAM 有限,不能定义太大的数组(比如
MAX_DATA_LEN不能设成 10000),避免内存溢出。
-
2. 进阶知识(理解协议设计思想)
-
通信协议基本概念:
-
帧结构设计:理解 “帧头 + 长度 + 数据 + 校验 + 帧尾” 的设计逻辑(为什么要有帧头?防止误触发;为什么要有长度?知道该收多少数据);
-
校验算法(CRC16):不用死记 CRC 的计算细节,但要理解 “校验的目的是验证数据完整性”,会调用现成的 CRC 函数即可;
-
状态机思想:理解 “分阶段处理事件” 的逻辑(不只是通信,单片机的按键处理、传感器读取都能用)。
-
-
单片机编程规范:
-
宏定义(#define):用宏定义代替魔法数字(比如
FRAME_HEADER_1代替 0xAA),方便修改和阅读; -
错误处理:理解 “解析失败就重置解析器” 的思想,避免单片机卡死在错误状态;
-
内存安全:知道 “缓冲区溢出” 的危害(比如数据长度超过数组大小),会做长度校验(
if (len > MAX_DATA_LEN) return 0)。
-
3. 实践类知识(把代码落地)
- 硬件实操
:
-
会用串口助手(比如 SSCOM)模拟发送数据,测试单片机的解析功能(比如发
AA 55 03 11 22 33 XX XX 0D,看单片机是否能正确解析); -
会调试单片机代码:比如用 printf 打印解析状态(当前是等待帧头 / 读取数据),看哪里出了问题。
-
- 代码优化思路
:
-
精简代码:比如数据长度为 0 时,直接跳过数据读取阶段,减少无用操作;
-
适配不同单片机:比如把代码从 STM32 移植到 Arduino,只需修改串口接收的部分,核心解析逻辑不用改。
-
三、总结
- 核心概念
:单片机通信协议解析的本质是 “约定一套数据格式 + 分阶段接收验证”,结构体是 “存储接收状态的小本子”,状态机是 “分阶段接收的规则”,CRC 是 “数据验证码”;
- 学习顺序
:先吃透 C 语言的结构体 / 枚举 / 数组 → 理解单片机串口和中断 → 掌握状态机和校验的思想 → 动手调试代码;
- 关键思维
:初学者要从 “能跑通” 到 “能理解”,重点是搞懂 “为什么要这么设计”(比如为什么要帧头、为什么要 CRC),而不是死记代码。
初学者不用一开始就追求写完美的协议,先实现 “能接收数据 + 简单校验”,再逐步优化(比如加帧头帧尾、加 CRC),慢慢就能理解通信协议的核心逻辑了。
一、协议核心设计(帧结构 + 代码功能)
1. 帧结构定义(固定格式,便于单片机解析)
|
字段 |
字节数 |
说明 |
|---|---|---|
|
帧头 1 |
1 |
固定值 |
|
帧头 2 |
1 |
固定值 |
|
数据长度 |
1 |
后续数据负载的字节数(范围 0~64,可通过 |
|
数据负载 |
N |
实际传输的数据(N = 数据长度字段值,最大 64 字节) |
|
CRC-16 校验 |
2 |
多项式 |
|
帧尾 |
1 |
固定值 |
2. 核心代码功能
- 状态机解析
:按 “帧头→长度→数据→CRC→帧尾” 分步处理字节流,适配单片机串口中断接收场景。
- CRC 校验
:发送端计算校验值封装到帧中,接收端重新计算并比对,排除数据传输错误。
- 错误处理
:帧头不匹配、长度超限、CRC 校验失败、帧尾错误时,自动重置解析器重新同步。
- 资源优化
:使用静态缓冲区,不依赖动态内存分配,适合 STM32、Arduino 等资源受限的 MCU。
二、完整代码实现(单片机适配版)
#include <stdint.h>
#include <string.h>
// 协议配置参数(可根据实际需求修改)
#define FRAME_HEADER_1 0xAA // 帧头第1字节
#define FRAME_HEADER_2 0x55 // 帧头第2字节
#define FRAME_TAIL 0x0D // 帧尾字节
#define MAX_DATA_LEN 64 // 最大数据负载长度
#define CRC16_POLY 0x8005 // CRC-16多项式
// CRC-16计算函数(输入:数据地址+长度,输出:16位校验值)
uint16_t crc16_calc(const uint8_t *data, uint16_t len) {
uint16_t crc =0xFFFF;// 初始值
for(uint16_t i =0; i < len; i++){
crc =(uint16_t)data[i]<<8;// 数据左移8位后与CRC异或
for(uint8_t j =0; j <8; j++){// 逐位处理
crc =(crc &0x8000)?(crc <<1CRC16_POLY):(crc <<1);
}
}
return crc;
}
// 解析器状态枚举(状态机核心)
typedef enum {
STATE_WAIT_HEADER1,// 等待帧头第1字节
STATE_WAIT_HEADER2,// 等待帧头第2字节
STATE_READ_LEN,// 读取数据长度
STATE_READ_DATA,// 读取数据负载
STATE_READ_CRC_H,// 读取CRC高字节
STATE_READ_CRC_L,// 读取CRC低字节
STATE_READ_TAIL// 读取帧尾
} parse_state_t;
// 解析器结构体(存储解析状态和缓存数据)
typedef struct {
parse_state_t state;// 当前解析状态
uint8_t data_buf[MAX_DATA_LEN];// 数据负载缓存
uint8_t data_len;// 接收的数据长度
uint16_t recv_crc;// 接收的CRC值
uint8_t buf_idx;// 数据缓存索引
} proto_parser_t;
// 初始化解析器(调用一次即可)
void proto_parser_init(proto_parser_t *parser) {
parser->state =STATE_WAIT_HEADER1;
parser->data_len =0;
parser->recv_crc =0;
parser->buf_idx =0;
memset(parser->data_buf,0,MAX_DATA_LEN);
}
// 单字节解析函数(串口中断中调用,每接收1字节执行1次)
// 返回值:0=解析中,1=解析成功,-1=解析失败
int8_t proto_parse_byte(proto_parser_t *parser, uint8_t byte) {
switch(parser->state){
// 状态1:等待帧头第1字节(0xAA)
caseSTATE_WAIT_HEADER1:
if(byte ==FRAME_HEADER_1){
parser->state =STATE_WAIT_HEADER2;// 找到后进入下一状态
}
break;
// 状态2:等待帧头第2字节(0x55)
caseSTATE_WAIT_HEADER2:
if(byte ==FRAME_HEADER_2){
parser->state =STATE_READ_LEN;// 帧头完整,进入读取长度状态
}else{
parser->state =STATE_WAIT_HEADER1;// 帧头错误,重置
}
break;
// 状态3:读取数据长度
caseSTATE_READ_LEN:
if(byte <=MAX_DATA_LEN){// 长度合法(不超过最大限制)
parser->data_len = byte;
parser->state =(byte ==0)?STATE_READ_CRC_H:STATE_READ_DATA;
// 数据长度为0时,直接跳过数据读取,进入CRC读取
}else{
proto_parser_init(parser);// 长度非法,重置解析器
return-1;
}
break;
// 状态4:读取数据负载
caseSTATE_READ_DATA:
parser->data_buf[parser->buf_idx++]= byte;// 存入缓存
// 数据读取完成(索引达到长度)
if(parser->buf_idx >= parser->data_len){
parser->buf_idx =0;// 重置索引
parser->state =STATE_READ_CRC_H;// 进入CRC读取状态
}
break;
// 状态5:读取CRC高字节
caseSTATE_READ_CRC_H:
parser->recv_crc =(uint16_t)byte <<8;// 高字节左移8位
parser->state =STATE_READ_CRC_L;
break;
// 状态6:读取CRC低字节
caseSTATE_READ_CRC_L:
parser->recv_crc |= byte;// 拼接低字节
parser->state =STATE_READ_TAIL;
break;
// 状态7:读取帧尾(0x0D)
caseSTATE_READ_TAIL:
if(byte ==FRAME_TAIL){// 帧尾正确,验证CRC
// 计算CRC:数据长度字段 + 数据负载
uint8_t crc_input[MAX_DATA_LEN+1];
crc_input[0]= parser->data_len;
memcpy(&crc_input[1], parser->data_buf, parser->data_len);
uint16_t calc_crc =crc16_calc(crc_input, parser->data_len +1);
if(calc_crc == parser->recv_crc){// CRC校验通过
proto_parser_init(parser);// 重置解析器,准备下一包
return1;// 解析成功
}else{
proto_parser_init(parser);
return-1;// CRC错误
}
}else{
proto_parser_init(parser);
return-1;// 帧尾错误
}
break;
default:
proto_parser_init(parser);// 异常状态重置
return-1;
}
return0;// 解析中
}
// 示例:发送帧封装函数(将数据打包为协议帧)
uint8_t proto_pack_frame(uint8_t *data, uint8_t len, uint8_t *frame_buf) {
if(len >MAX_DATA_LEN)return0;// 数据长度超限
// 帧头
frame_buf[0]=FRAME_HEADER_1;
frame_buf[1]=FRAME_HEADER_2;
// 数据长度
frame_buf[2]= len;
// 数据负载
memcpy(&frame_buf[3], data, len);
// CRC校验(计算范围:长度+数据)
uint16_t crc =crc16_calc(&frame_buf[2], len +1);
frame_buf[3+ len]=(crc >>8)&0xFF;// CRC高字节
frame_buf[4+ len]= crc &0xFF;// CRC低字节
// 帧尾
frame_buf[5+ len]=FRAME_TAIL;
return6+ len;// 返回帧总长度(6=头2+长1+CRC2+尾1)
}
// 主函数示例(模拟单片机运行逻辑)
int main(void) {
proto_parser_t parser;
proto_parser_init(&parser);// 初始化解析器
// 模拟:发送端打包数据
uint8_t send_data[]={0x11,0x22,0x33};// 待发送数据
uint8_t send_frame[100];
uint8_t frame_len =proto_pack_frame(send_data,sizeof(send_data), send_frame);
// 模拟:接收端逐字节解析(实际中在串口中断中调用)
for(uint8_t i =0; i < frame_len; i++){
int8_t ret =proto_parse_byte(&parser, send_frame[i]);
if(ret 1){
// 解析成功,处理数据(parser.data_buf中存储有效数据)
// 此处可添加数据处理逻辑(如控制GPIO、上报数据等)
}elseif(ret -1){
// 解析失败,可记录错误日志
}
}
while(1){
// 单片机主循环
}
}
三、解析流程流程图(初学者友好版)
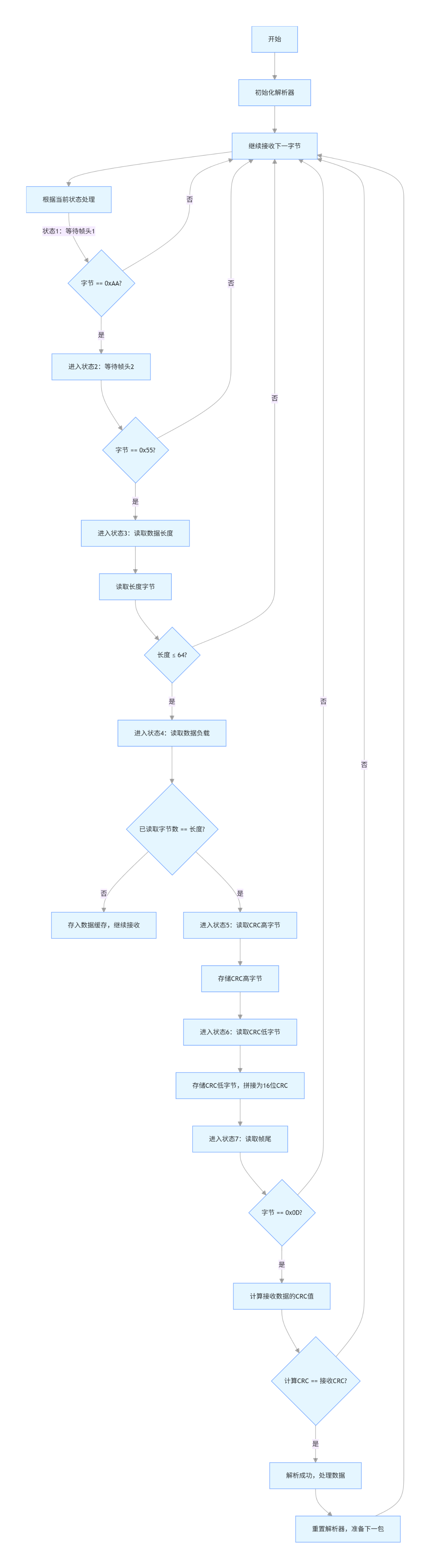
四、流程图关键步骤解释(初学者必看)
- 初始化阶段
:解析器默认处于 “等待帧头 1” 状态,所有缓存和索引清零,确保初始状态干净。
- 帧头校验
:必须连续收到
0xAA和0x55才认为帧开始,避免单个错误字节触发解析(比如数据中恰好有0xAA)。 - 长度校验
:限制数据长度不超过
MAX_DATA_LEN,防止缓冲区溢出(单片机内存有限,需避免越界)。 - 数据读取
:按长度字段指定的字节数读取数据,读完后自动进入 CRC 校验阶段,无需手动控制。
- CRC 校验
:核心是 “发送端和接收端计算范围一致”(均包含长度 + 数据),确保数据传输中无篡改、无丢失。
- 错误重置
:任何环节出错(帧头不匹配、长度超限、CRC 错误、帧尾错误),都会立即重置解析器,重新等待下一个帧头,保证解析鲁棒性。
五、实际使用场景说明
- 串口中断集成
:在单片机串口接收中断服务函数中,调用
proto_parse_byte,每接收 1 字节触发 1 次解析,实时性高。 - 数据处理
:当
proto_parse_byte返回 1 时,parser.data_buf中存储的就是有效数据,可直接用于控制(如点亮 LED、驱动电机)或上报(如通过 WiFi 发送到服务器)。 - 灵活调整
:如果需要修改协议,只需修改
FRAME_HEADER_1、CRC16_POLY等宏定义,无需改动核心逻辑(比如将帧尾改为0x0A,或 CRC 改为 8 位)。
为了让你彻底理解,我会把代码按 “模块 + 功能 + 逐行解释” 的方式拆解,重点标注结构体、核心函数的设计思路和作用:
模块 1:头文件与协议配置(代码最开头)
#include <stdint.h>
#include <string.h>
// 协议配置参数(可根据实际需求修改)
#define FRAME_HEADER_1 0xAA // 帧头第1字节
#define FRAME_HEADER_2 0x55 // 帧头第2字节
#define FRAME_TAIL 0x0D // 帧尾字节
#define MAX_DATA_LEN 64 // 最大数据负载长度
#define CRC16_POLY 0x8005 // CRC-16多项式
功能解释:
#include <stdint.h>:引入单片机常用的 “固定位数整数类型”(比如
uint8_t=8 位无符号整数,uint16_t=16 位),避免不同单片机对int的位数定义不同导致错误;#include <string.h>:引入内存操作函数(比如
memset清空数组、memcpy复制数组);#define宏定义:把协议里的 “固定值” 用 “见名知意” 的名字代替(比如
FRAME_HEADER_1代替 0xAA),初学者改参数时不用翻代码,直接改宏定义就行,还能避免写错数字。
// CRC-16计算函数(输入:数据地址+长度,输出:16位校验值)
uint16_t crc16_calc(const uint8_t *data, uint16_t len){
uint16_t crc =0xFFFF;// 初始值(行业通用,不用改)
for(uint16_t i =0; i < len; i++){// 遍历每一个字节
crc =(uint16_t)data[i]<<8;// 把8位数据左移8位,和CRC异或(对齐位数)
for(uint8_t j =0; j <8; j++){// 对每个字节的8个位逐位处理
// 核心逻辑:如果CRC最高位是1,左移后异或多项式;否则只左移
crc =(crc &0x8000)?(crc <<1CRC16_POLY):(crc <<1);
}
}
return crc;// 返回最终计算的CRC值
}
功能解释:
-
作用:给一段数据生成唯一的 “校验码”(比如数据
{0x11,0x22}算出的 CRC 是固定值),发送方算好一起发,接收方重新算一遍,对比校验码就知道数据有没有传错; -
初学者重点:不用死记计算逻辑(这是行业标准的 CRC16 算法),只需知道:
-
输入:要校验的数据(
data)+ 数据长度(len); -
输出:16 位的 CRC 值;
-
调用示例:
crc16_calc(send_data, 3)就能算出send_data数组前 3 个字节的 CRC。
-
// 解析器状态枚举(状态机核心)
typedef enum{
STATE_WAIT_HEADER1,// 等待帧头第1字节(0xAA)
STATE_WAIT_HEADER2,// 等待帧头第2字节(0x55)
STATE_READ_LEN,// 读取数据长度
STATE_READ_DATA,// 读取数据负载
STATE_READ_CRC_H,// 读取CRC高字节
STATE_READ_CRC_L,// 读取CRC低字节
STATE_READ_TAIL// 读取帧尾(0x0D)
} parse_state_t;
功能解释:
typedef enum:枚举类型,把 “数字” 和 “状态名字” 绑定(比如
STATE_WAIT_HEADER1对应 0,STATE_WAIT_HEADER2对应 1);-
初学者理解:把单片机接收数据的过程拆成 7 个 “阶段”,就像玩游戏的 “关卡”,必须过了第一关(收到 0xAA)才能进第二关(等 0x55),错了就回到第一关,避免混乱。
模块 4:解析器结构体(“存储接收数据的小本子”)
// 解析器结构体(存储解析状态和缓存数据)
typedef struct {
parse_state_t state;// 当前解析到哪个阶段(比如在等帧头、读数据)
uint8_t data_buf[MAX_DATA_LEN];// 存接收的实际数据(比如传感器值、控制指令)
uint8_t data_len;// 记录数据长度(比如对方说要发3个字节,这里就存3)
uint16_t recv_crc;// 存接收的CRC值(用来和计算的CRC对比)
uint8_t buf_idx;// 记录已经存了几个字节到data_buf(比如存了2个,idx=2)
} proto_parser_t;
功能解释(初学者必懂):
typedef struct:结构体,把 “和接收数据相关的所有变量” 打包成一个整体,就像给单片机准备一个 “专用笔记本”,所有接收相关的信息都记在这本子里,不用零散记 5 个变量;
- 各成员作用:
成员名
通俗解释
state
记当前 “关卡”(比如现在在等帧头,还是在读数据)
data_buf
记对方发的实际内容(比如对方发 “11 22 33”,这里就存这 3 个字节)
data_len
记对方说要发多少字节(比如对方说发 3 个,这里就存 3,防止存多了溢出)
recv_crc
记对方发的 CRC 校验码(比如对方发的是 0x1234,这里就存 0x1234)
buf_idx
记已经存了几个字节到 data_buf(比如存了 2 个,idx=2,再存 1 个就凑够 3 个)
模块 5:解析器初始化函数(清空 “小本子”)
// 初始化解析器(调用一次即可)
voidproto_parser_init(proto_parser_t *parser){
parser->state =STATE_WAIT_HEADER1;// 初始关卡:等帧头1(0xAA)
parser->data_len =0;// 数据长度清零
parser->recv_crc =0;// CRC值清零
parser->buf_idx =0;// 缓存索引清零
memset(parser->data_buf,0,MAX_DATA_LEN);// 清空数据缓存(填0)
}
功能解释:
-
作用:每次开始接收数据前,把 “小本子” 清空,让单片机从 “第一关(等帧头)” 开始;
parser->state:访问结构体成员的方式(
->用于结构体指针,.用于结构体变量),初学者记住:定义结构体指针(proto_parser_t *parser)就用->,定义普通结构体(proto_parser_t parser)就用.;memset(parser->data_buf, 0, MAX_DATA_LEN):把
data_buf数组的所有元素设为 0,相当于清空笔记本。
模块 6:核心解析函数(状态机处理,逐字节解析)
// 单字节解析函数(串口中断中调用,每接收1字节执行1次)
// 返回值:0=解析中,1=解析成功,-1=解析失败
int8_t proto_parse_byte(proto_parser_t *parser, uint8_t byte){
switch(parser->state){// 根据当前“关卡”处理字节
// 关卡1:等帧头1(0xAA)
caseSTATE_WAIT_HEADER1:
if(byte ==FRAME_HEADER_1){
parser->state =STATE_WAIT_HEADER2;// 收到0xAA,进下一关
}
break;
// 关卡2:等帧头2(0x55)
caseSTATE_WAIT_HEADER2:
if(byte ==FRAME_HEADER_2){
parser->state =STATE_READ_LEN;// 收到0x55,进“读长度”关卡
}else{
parser->state =STATE_WAIT_HEADER1;// 没收到0x55,回第一关
}
break;
// 关卡3:读数据长度
caseSTATE_READ_LEN:
if(byte <=MAX_DATA_LEN){// 长度合法(不超过64)
parser->data_len = byte;// 记录数据长度
// 如果长度是0(没数据),直接跳去读CRC;否则读数据
parser->state =(byte ==0)?STATE_READ_CRC_H:STATE_READ_DATA;
}else{
proto_parser_init(parser);// 长度非法,清空本子
return-1;
}
break;
// 关卡4:读数据负载
caseSTATE_READ_DATA:
parser->data_buf[parser->buf_idx++]= byte;// 把字节存到缓存,索引+1
if(parser->buf_idx >= parser->data_len){// 存够了指定长度
parser->buf_idx =0;// 索引清零
parser->state =STATE_READ_CRC_H;// 进“读CRC高字节”关卡
}
break;
// 关卡5:读CRC高字节
caseSTATE_READ_CRC_H:
parser->recv_crc =(uint16_t)byte <<8;// 高字节左移8位(比如0x12→0x1200)
parser->state =STATE_READ_CRC_L;// 进下一关
break;
// 关卡6:读CRC低字节
caseSTATE_READ_CRC_L:
parser->recv_crc |= byte;// 拼接低字节(0x1200 | 0x34 = 0x1234)
parser->state =STATE_READ_TAIL;// 进“读帧尾”关卡
break;
// 关卡7:读帧尾(0x0D)
caseSTATE_READ_TAIL:
if(byte ==FRAME_TAIL){// 收到帧尾
// 准备计算CRC:把“长度+数据”打包成数组
uint8_t crc_input[MAX_DATA_LEN+1];
crc_input[0]= parser->data_len;// 第0位存长度
memcpy(&crc_input[1], parser->data_buf, parser->data_len);// 后面存数据
uint16_t calc_crc =crc16_calc(crc_input, parser->data_len +1);// 算CRC
if(calc_crc == parser->recv_crc){// CRC对比一致
proto_parser_init(parser);// 清空本子,准备下一次接收
return1;// 解析成功
}else{
proto_parser_init(parser);// CRC错,清空
return-1;
}
}else{
proto_parser_init(parser);// 帧尾错,清空
return-1;
}
break;
default:// 异常状态(比如state变成了不存在的数字)
proto_parser_init(parser);
return-1;
}
return0;// 还在解析中,没完成
}
核心解释(初学者重点):
-
调用时机:单片机串口每收到 1 个字节,就调用一次这个函数(比如串口中断里调用);
switch (parser->state):根据当前 “关卡” 处理字节,比如在 “等帧头 1” 时,只关心字节是不是 0xAA,其他字节都忽略;
-
错误处理:任何一步出错(比如帧头错、长度超了、CRC 错),都会调用
proto_parser_init清空本子,回到第一关,避免单片机卡死; -
返回值:
-
0:还在解析(比如刚收到 0xAA,还在等 0x55);
-
1:解析成功(可以去处理
data_buf里的数据了); -
-1:解析失败(数据错了,重新等)。
-
模块 7:发送帧封装函数(打包数据)
// 示例:发送帧封装函数(将数据打包为协议帧)
uint8_t proto_pack_frame(uint8_t *data, uint8_t len, uint8_t *frame_buf){
if(len >MAX_DATA_LEN)return0;// 数据太长,打包失败
// 步骤1:填帧头
frame_buf[0]=FRAME_HEADER_1;
frame_buf[1]=FRAME_HEADER_2;
// 步骤2:填数据长度
frame_buf[2]= len;
// 步骤3:填数据负载
memcpy(&frame_buf[3], data, len);
// 步骤4:算CRC并填进去
uint16_t crc =crc16_calc(&frame_buf[2], len +1);// 计算“长度+数据”的CRC
frame_buf[3+ len]=(crc >>8)&0xFF;// CRC高字节
frame_buf[4+ len]= crc &0xFF;// CRC低字节
// 步骤5:填帧尾
frame_buf[5+ len]=FRAME_TAIL;
return6+ len;// 返回帧总长度(2帧头+1长度+len数据+2CRC+1帧尾=6+len)
}
功能解释:
-
作用:把要发送的 “原始数据”(比如
{0x11,0x22,0x33})打包成符合协议的 “完整帧”(比如AA 55 03 11 22 33 XX XX 0D); -
输入:
data(要发送的原始数据)、len(数据长度)、frame_buf(用来存打包后的完整帧); -
输出:返回打包后的帧总长度(方便串口发送时知道要发多少字节)。
模块 8:主函数示例(模拟单片机运行)
// 主函数示例(模拟单片机运行逻辑)
int main(void){
proto_parser_t parser;// 定义一个解析器结构体(普通变量,用.访问)
proto_parser_init(&parser);// 初始化解析器(传地址,用&)
// 模拟:发送端打包数据
uint8_t send_data[]={0x11,0x22,0x33};// 要发送的原始数据
uint8_t send_frame[100];// 存打包后的帧
uint8_t frame_len =proto_pack_frame(send_data,sizeof(send_data), send_frame);
// 模拟:接收端逐字节解析(实际中在串口中断中调用)
for(uint8_t i =0; i < frame_len; i++){
int8_t ret =proto_parse_byte(&parser, send_frame[i]);
if(ret 1){
// 解析成功,处理数据(比如把data_buf里的数发给传感器/点亮LED)
}elseif(ret -1){
// 解析失败,记录错误(比如闪灯提示)
}
}
while(1){// 单片机主循环(一直运行)
// 这里可以加其他逻辑(比如定时发送数据、处理按键)
}
}
功能解释:
proto_parser_t parser;:定义一个解析器结构体变量(普通变量,不是指针),初学者注意:定义指针用
proto_parser_t *parser,定义普通变量用proto_parser_t parser;proto_parser_init(&parser);:初始化解析器,
&parser是取结构体的地址(因为初始化函数的参数是指针);-
模拟发送:打包
send_data成send_frame,模拟实际项目中 “单片机发送数据” 的场景; -
模拟接收:逐字节解析
send_frame,模拟 “串口中断接收字节并解析” 的场景; while (1):单片机的主循环,一旦进入就永远运行(单片机不能像电脑一样运行完就退出)。
二、核心知识点总结(初学者必记)
- 结构体(struct)
:把 “相关变量打包”,比如解析器的状态、缓存、长度等放在一起,方便管理和传递,访问方式:指针用
->,普通变量用.; - 状态机(enum+switch)
:把 “分步接收数据” 拆成多个阶段,每个阶段只处理对应字节,避免混乱,是单片机通信解析的核心思想;
- CRC 校验
:不用记计算逻辑,只需知道 “发送方算 CRC 一起发,接收方重算对比,一致则数据正确”;
- 逐字节解析
:单片机串口接收是 “一个字节一个字节来”,所以解析函数要按字节处理,不能一次性处理整帧;
- 错误处理
:任何环节出错都要 “重置解析器”,回到初始状态,避免单片机卡死。
初学者先把 “结构体成员作用”“状态机的 7 个阶段” 记熟,再动手把代码烧到单片机里,用串口助手发数据测试(比如发AA 55 03 11 22 33 78 9A 0D),看解析是否成功,就能快速理解每段代码的实际作用了。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











