




 本文介绍了一个基于Linux kfifo实现的环形缓冲区,并通过多线程模拟生产者与消费者进行测试。环形缓冲区使用互斥锁确保线程安全,测试程序在生产者与消费者之间传递学生信息数据。
本文介绍了一个基于Linux kfifo实现的环形缓冲区,并通过多线程模拟生产者与消费者进行测试。环形缓冲区使用互斥锁确保线程安全,测试程序在生产者与消费者之间传递学生信息数据。
/**@brief 仿照linux kfifo写的ring buffer
*@atuher Anker date:2013-12-18
* ring_buffer.h
* */
#ifndef KFIFO_HEADER_H
#define KFIFO_HEADER_H
#include <inttypes.h>
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <assert.h>
//判断x是否是2的次方
#define is_power_of_2(x) ((x) != 0 && (((x) & ((x) - 1)) == 0))
//取a和b中最小值
#define min(a, b) (((a) < (b)) ? (a) : (b))
struct ring_buffer
{
void *buffer; //缓冲区
uint32_t size; //大小
uint32_t in; //入口位置
uint32_t out; //出口位置
pthread_mutex_t *f_lock; //互斥锁
};
//初始化缓冲区
struct ring_buffer* ring_buffer_init(void *buffer, uint32_t size, pthread_mutex_t *f_lock)
{
assert(buffer);
struct ring_buffer *ring_buf = NULL;
if (!is_power_of_2(size))
{
fprintf(stderr,"size must be power of 2.\n");
return ring_buf;
}
ring_buf = (struct ring_buffer *)malloc(sizeof(struct ring_buffer));
if (!ring_buf)
{
fprintf(stderr,"Failed to malloc memory,errno:%u,reason:%s",
errno, strerror(errno));
return ring_buf;
}
memset(ring_buf, 0, sizeof(struct ring_buffer));
ring_buf->buffer = buffer;
ring_buf->size = size;
ring_buf->in = 0;
ring_buf->out = 0;
ring_buf->f_lock = f_lock;
return ring_buf;
}
//释放缓冲区
void ring_buffer_free(struct ring_buffer *ring_buf)
{
if (ring_buf)
{
if (ring_buf->buffer)
{
free(ring_buf->buffer);
ring_buf->buffer = NULL;
}
free(ring_buf);
ring_buf = NULL;
}
}
//缓冲区的长度
uint32_t __ring_buffer_len(const struct ring_buffer *ring_buf)
{
return (ring_buf->in - ring_buf->out);
}
//从缓冲区中取数据
uint32_t __ring_buffer_get(struct ring_buffer *ring_buf, void * buffer, uint32_t size)
{
assert(ring_buf || buffer);
uint32_t len = 0;
size = min(size, ring_buf->in - ring_buf->out);
/* first get the data from fifo->out until the end of the buffer */
len = min(size, ring_buf->size - (ring_buf->out & (ring_buf->size - 1)));
memcpy(buffer, ring_buf->buffer + (ring_buf->out & (ring_buf->size - 1)), len);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + len, ring_buf->buffer, size - len);
ring_buf->out += size;
return size;
}
//向缓冲区中存放数据
uint32_t __ring_buffer_put(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
{
assert(ring_buf || buffer);
uint32_t len = 0;
size = min(size, ring_buf->size - ring_buf->in + ring_buf->out);
/* first put the data starting from fifo->in to buffer end */
len = min(size, ring_buf->size - (ring_buf->in & (ring_buf->size - 1)));
memcpy(ring_buf->buffer + (ring_buf->in & (ring_buf->size - 1)), buffer, len);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(ring_buf->buffer, buffer + len, size - len);
ring_buf->in += size;
return size;
}
uint32_t ring_buffer_len(const struct ring_buffer *ring_buf)
{
uint32_t len = 0;
pthread_mutex_lock(ring_buf->f_lock);
len = __ring_buffer_len(ring_buf);
pthread_mutex_unlock(ring_buf->f_lock);
return len;
}
uint32_t ring_buffer_get(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
{
uint32_t ret;
pthread_mutex_lock(ring_buf->f_lock);
ret = __ring_buffer_get(ring_buf, buffer, size);
//buffer中没有数据
if (ring_buf->in == ring_buf->out)
ring_buf->in = ring_buf->out = 0;
pthread_mutex_unlock(ring_buf->f_lock);
return ret;
}
uint32_t ring_buffer_put(struct ring_buffer *ring_buf, void *buffer, uint32_t size)
{
uint32_t ret;
pthread_mutex_lock(ring_buf->f_lock);
ret = __ring_buffer_put(ring_buf, buffer, size);
pthread_mutex_unlock(ring_buf->f_lock);
return ret;
}
#endif
采用多线程模拟生产者和消费者编写测试程序,如下所示:
/**@brief ring buffer测试程序,创建两个线程,一个生产者,一个消费者。
* 生产者每隔1秒向buffer中投入数据,消费者每隔2秒去取数据。
*@atuher Anker date:2013-12-18
* */
#include "ring_buffer.h"
#include <pthread.h>
#include <time.h>
#define BUFFER_SIZE 1024 * 1024
typedef struct student_info
{
uint64_t stu_id;
uint32_t age;
uint32_t score;
}student_info;
void print_student_info(const student_info *stu_info)
{
assert(stu_info);
printf("id:%lu\t",stu_info->stu_id);
printf("age:%u\t",stu_info->age);
printf("score:%u\n",stu_info->score);
}
student_info * get_student_info(time_t timer)
{
student_info *stu_info = (student_info *)malloc(sizeof(student_info));
if (!stu_info)
{
fprintf(stderr, "Failed to malloc memory.\n");
return NULL;
}
srand(timer);
stu_info->stu_id = 10000 + rand() % 9999;
stu_info->age = rand() % 30;
stu_info->score = rand() % 101;
print_student_info(stu_info);
return stu_info;
}
void * consumer_proc(void *arg)
{
struct ring_buffer *ring_buf = (struct ring_buffer *)arg;
student_info stu_info;
while(1)
{
sleep(2);
printf("------------------------------------------\n");
printf("get a student info from ring buffer.\n");
ring_buffer_get(ring_buf, (void *)&stu_info, sizeof(student_info));
printf("ring buffer length: %u\n", ring_buffer_len(ring_buf));
print_student_info(&stu_info);
printf("------------------------------------------\n");
}
return (void *)ring_buf;
}
void * producer_proc(void *arg)
{
time_t cur_time;
struct ring_buffer *ring_buf = (struct ring_buffer *)arg;
while(1)
{
time(&cur_time);
srand(cur_time);
int seed = rand() % 11111;
printf("******************************************\n");
student_info *stu_info = get_student_info(cur_time + seed);
printf("put a student info to ring buffer.\n");
ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
printf("ring buffer length: %u\n", ring_buffer_len(ring_buf));
printf("******************************************\n");
sleep(1);
}
return (void *)ring_buf;
}
int consumer_thread(void *arg)
{
int err;
pthread_t tid;
err = pthread_create(&tid, NULL, consumer_proc, arg);
if (err != 0)
{
fprintf(stderr, "Failed to create consumer thread.errno:%u, reason:%s\n",
errno, strerror(errno));
return -1;
}
return tid;
}
int producer_thread(void *arg)
{
int err;
pthread_t tid;
err = pthread_create(&tid, NULL, producer_proc, arg);
if (err != 0)
{
fprintf(stderr, "Failed to create consumer thread.errno:%u, reason:%s\n",
errno, strerror(errno));
return -1;
}
return tid;
}
int main()
{
void * buffer = NULL;
uint32_t size = 0;
struct ring_buffer *ring_buf = NULL;
pthread_t consume_pid, produce_pid;
pthread_mutex_t *f_lock = (pthread_mutex_t *)malloc(sizeof(pthread_mutex_t));
if (pthread_mutex_init(f_lock, NULL) != 0)
{
fprintf(stderr, "Failed init mutex,errno:%u,reason:%s\n",
errno, strerror(errno));
return -1;
}
buffer = (void *)malloc(BUFFER_SIZE);
if (!buffer)
{
fprintf(stderr, "Failed to malloc memory.\n");
return -1;
}
size = BUFFER_SIZE;
ring_buf = ring_buffer_init(buffer, size, f_lock);
if (!ring_buf)
{
fprintf(stderr, "Failed to init ring buffer.\n");
return -1;
}
#if 0
student_info *stu_info = get_student_info(638946124);
ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
stu_info = get_student_info(976686464);
ring_buffer_put(ring_buf, (void *)stu_info, sizeof(student_info));
ring_buffer_get(ring_buf, (void *)stu_info, sizeof(student_info));
print_student_info(stu_info);
#endif
printf("multi thread test.......\n");
produce_pid = producer_thread((void*)ring_buf);
consume_pid = consumer_thread((void*)ring_buf);
pthread_join(produce_pid, NULL);
pthread_join(consume_pid, NULL);
ring_buffer_free(ring_buf);
free(f_lock);
return 0;
}
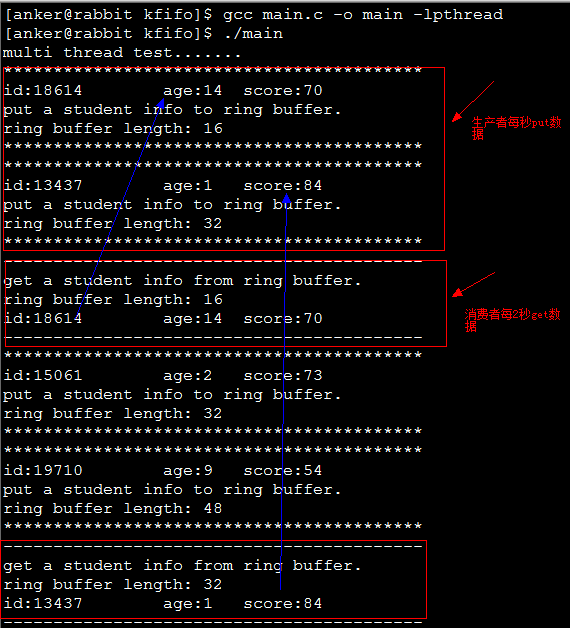
测试结果如下:

















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









