



 本文介绍如何使用Python的pyaudio库进行录音,并利用百度AI平台实现语音转文字及文字转语音的功能。
本文介绍如何使用Python的pyaudio库进行录音,并利用百度AI平台实现语音转文字及文字转语音的功能。
一、在python中使用pyaudio进行录音
环境准备
1、首先在相关的项目下使用如下命令安装pyaudio。
pip install pyaudio
2、使用pip install pyaudio安装失败的解决方式
(1)在https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio下下载相关的版本。
因为我是win10,64bit的系统,同时python的相关版本为3.8,故选择下载如下的相关whl文件。
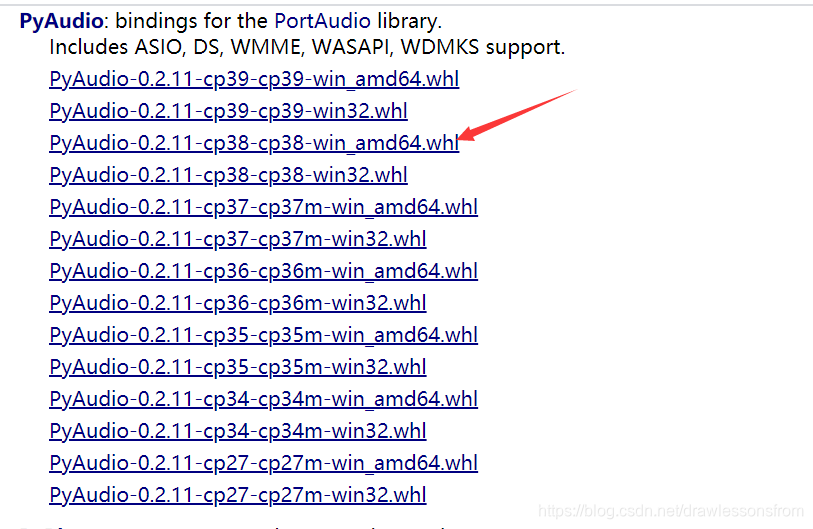
注意:cp38表示python 的版本为3.8,下载相关的文件应该根据自己系统所安装的python版本决定。
(2)在下载到相关的文件时,应该将该相关文件保存到项目所对应的python环境的Script中,然后通过终端进入到该whl文件所保存的路径,在相关的终端下输入如下命令:
pip install PyAudio-0.2.11-cp38-cp38-win_amd64.whl
然后使用如下命令进行相关的安装:
pip install pyaudio
通过以上的操作步骤,可以发现pyaudio安装成功。
具体代码实现
import pyaudio
import wave
# 每个缓冲区的帧数
CHUNK = 1024
# 采样位数
FORMAT = pyaudio.paInt16
# 单声道
CHANNELS = 1
# 采样频率
RATE = 44100
# 录制声音的相关函数(参数1:录制的路径;参数2:录制的声音秒数)
def record_audio(wave_out_path, record_second):
# 实例化相关的对象
p = pyaudio.PyAudio()
# 打开相关的流,然后传入响应参数
stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK)
# 打开wav文件
wf = wave.open(wave_out_path, 'wb')
# 设置相关的声道
wf.setnchannels(CHANNELS)
# 设置采样位数
wf.setsampwidth(p.get_sample_size((FORMAT)))
# 设置采样频率
wf.setframerate(RATE)
for _ in range(0, int(RATE * record_second / CHUNK)):
data = stream.read(CHUNK)
# 写入数据
wf.writeframes(data)
# 关闭流
stream.stop_stream()
stream.close()
p.terminate()
wf.close()
record_audio('text.mp3', 5)
二、使用百度的语音识别功能进行语音识别与将文字转化成语音
在百度AI开放平台上创建相关的应用,具体操作步骤如下:
1、进入到百度AI开放平台:https://ai.baidu.com/
2、使用百度账号进行登录到百度云中
3、进入语音技术功能界面
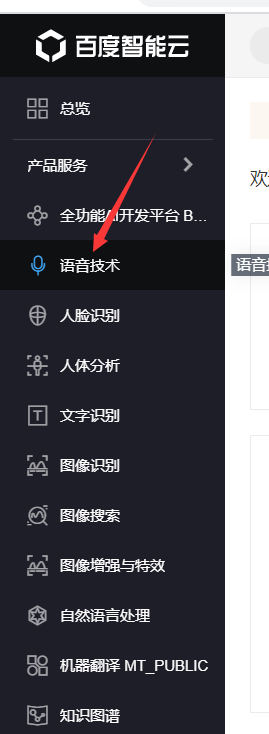
4、选择创建应用
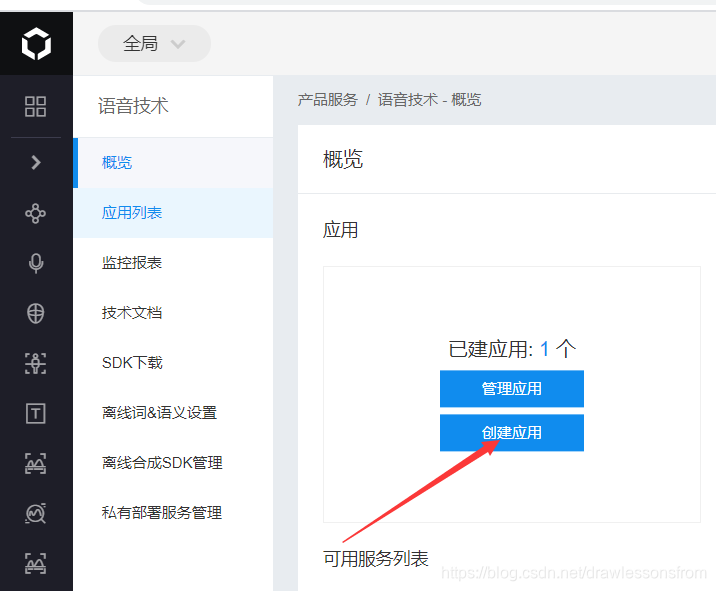
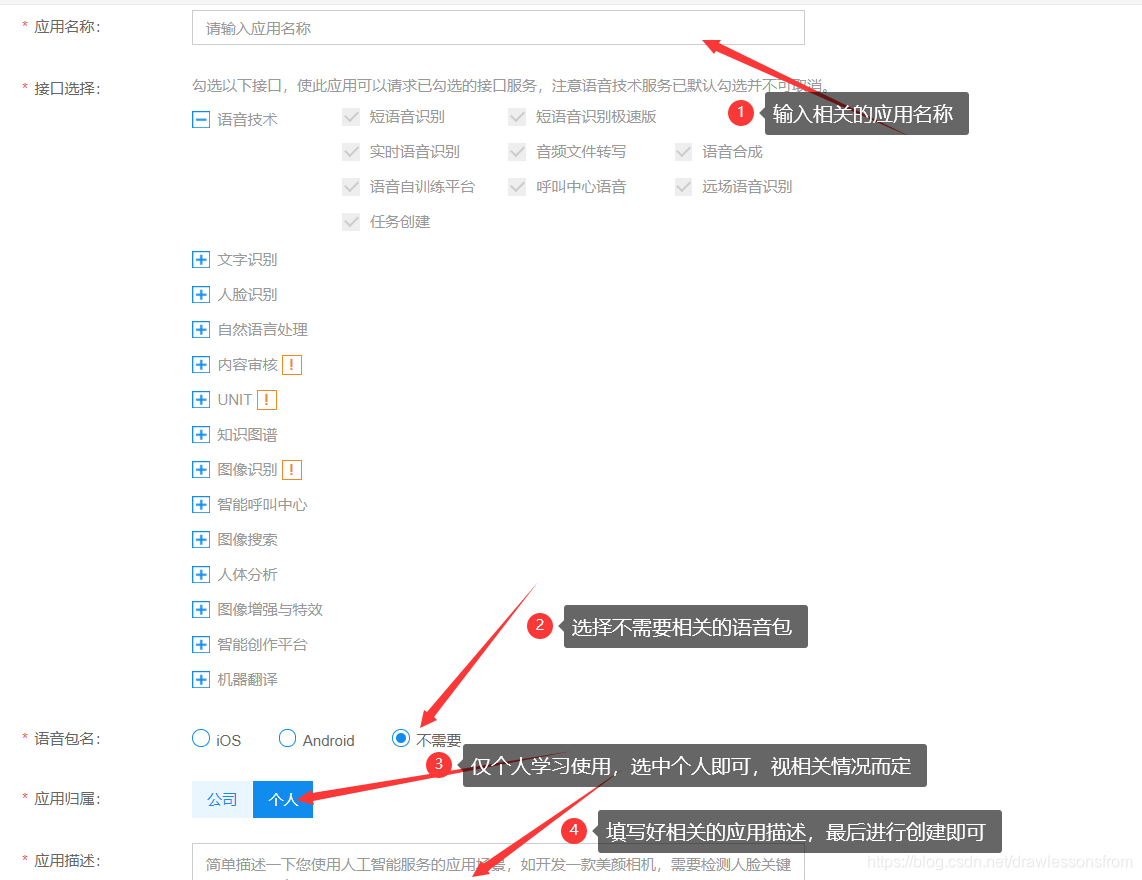
创建好后其相关的应用详情如下所示:
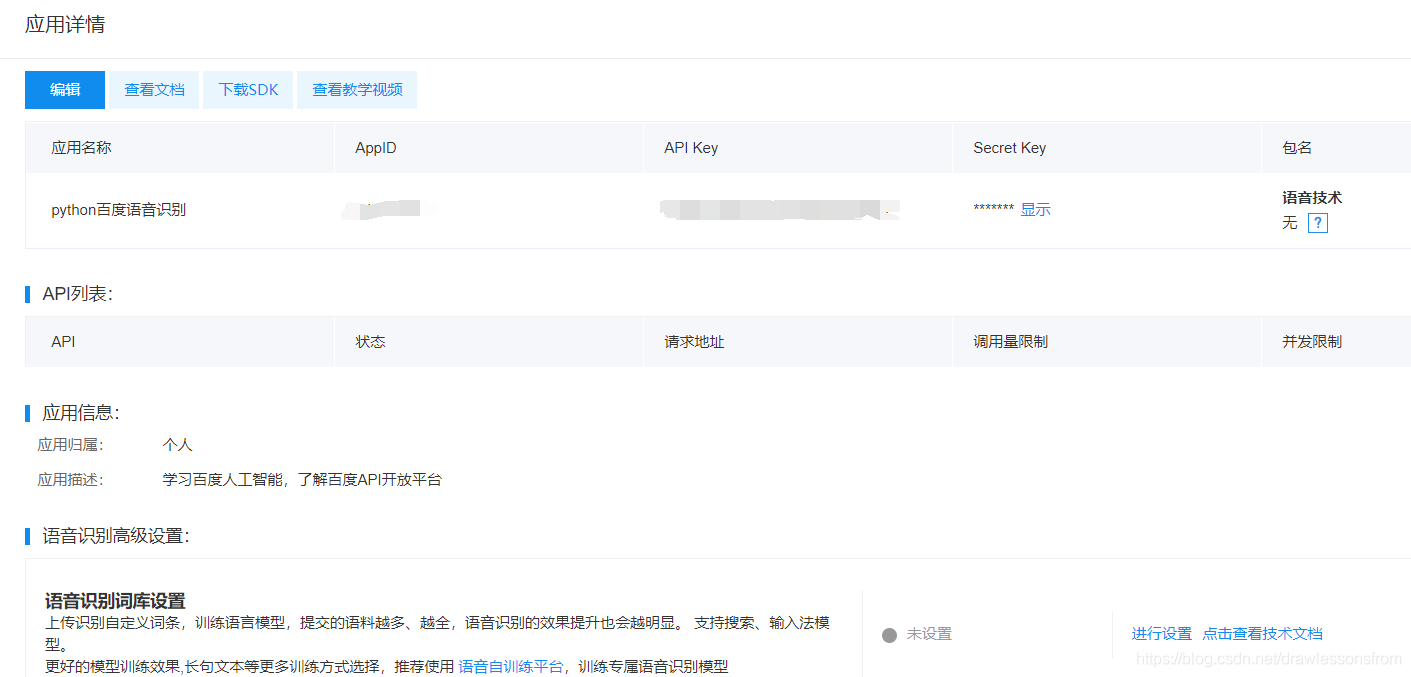
环境准备
在相关的项目下使用如下命令安装baidu-aip:
pip install baidu-aip
为了将所有相关的音频格式均转换成.pcm格式的音频文件,需要下载FFmpeg文件,相关文件的下载方式如下所示:
链接:https://pan.baidu.com/s/1pHw8mrg_AeTHiUqFl3PxQQ
密码:1499
下载好后需要进行相关的解压操作,然后进入到相关文件的bin目录下,赋值相关的bin的路径,相关操作如下所示:
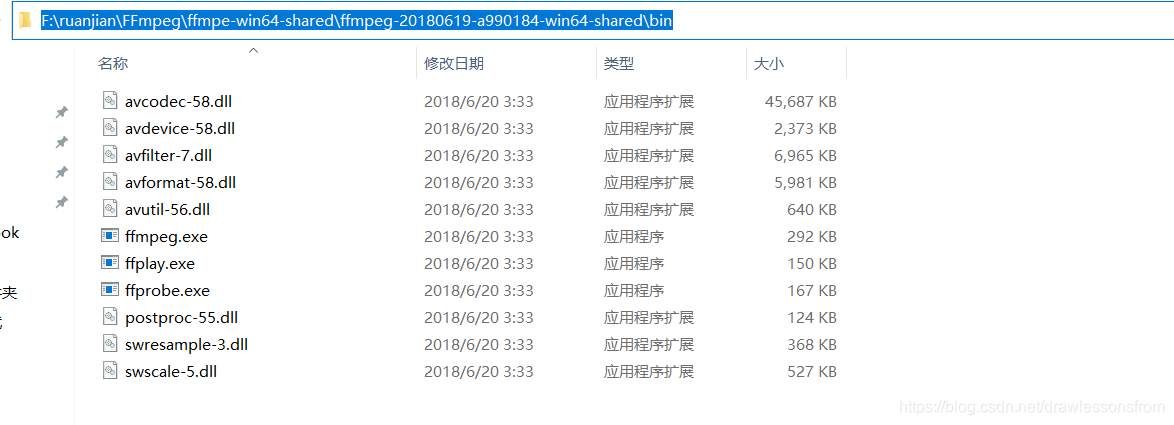
赋值好后进行相关的环境变量配置,相关配置的具体步骤如下所示
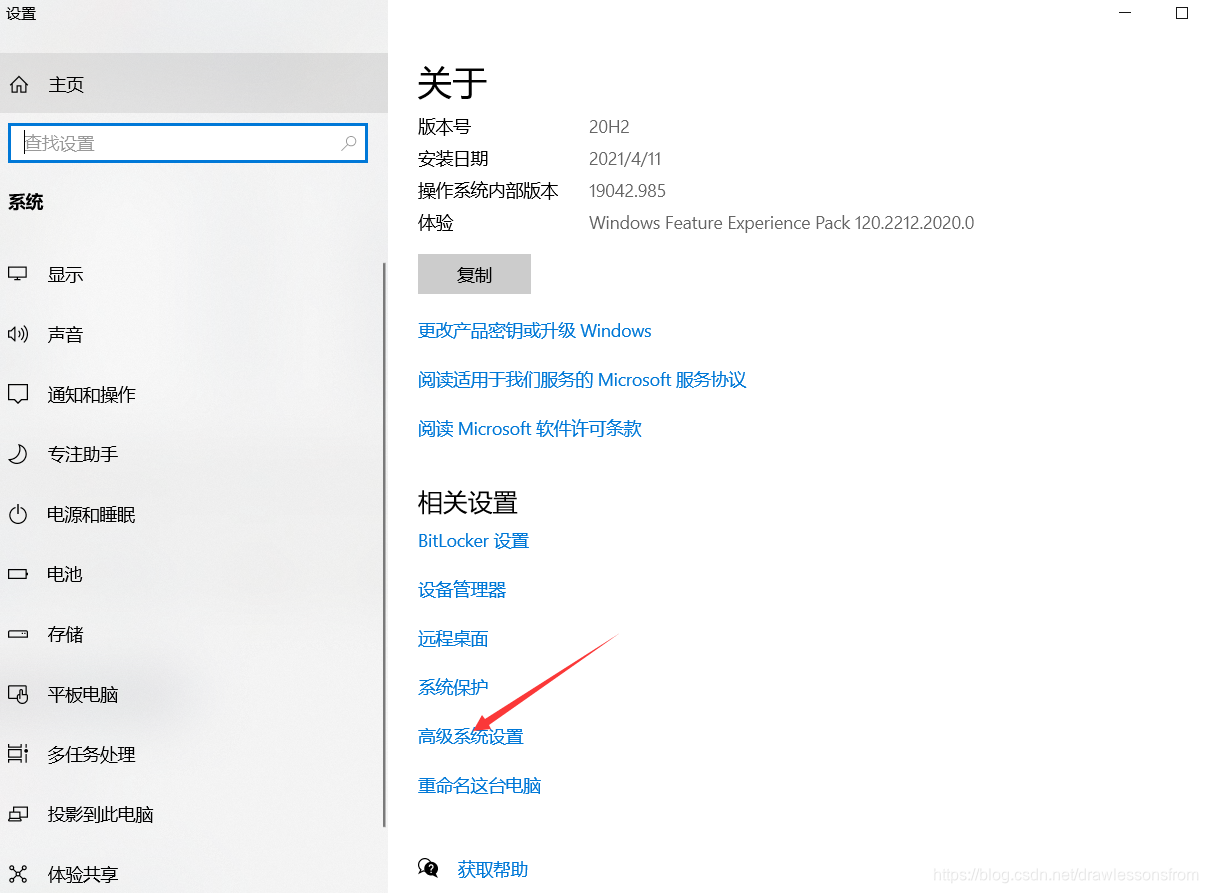
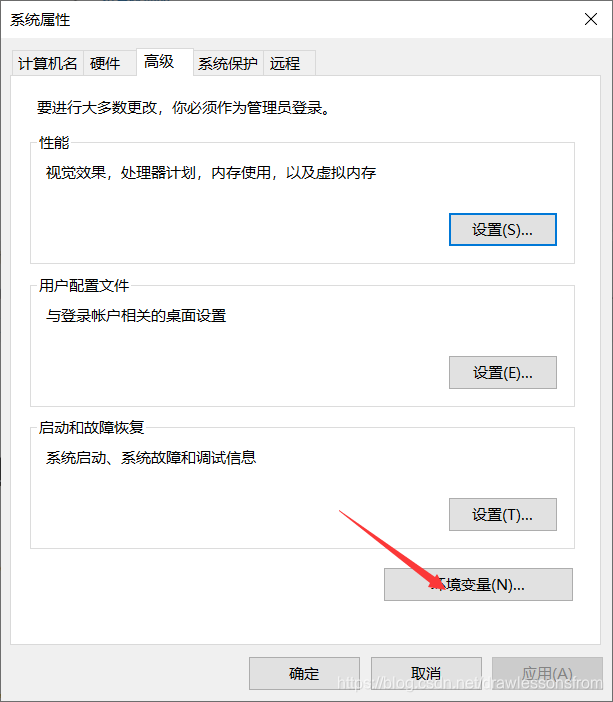
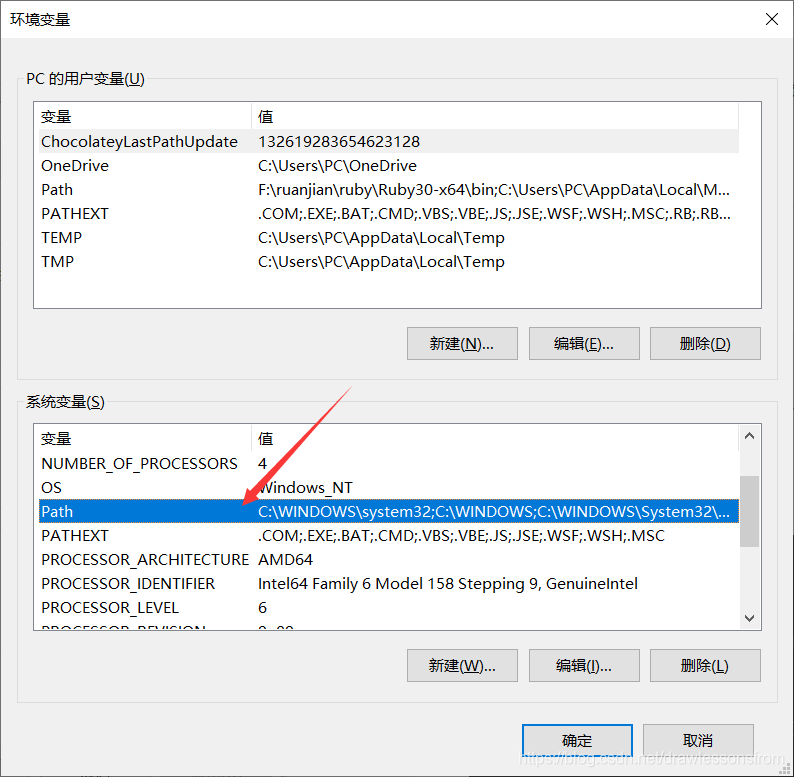
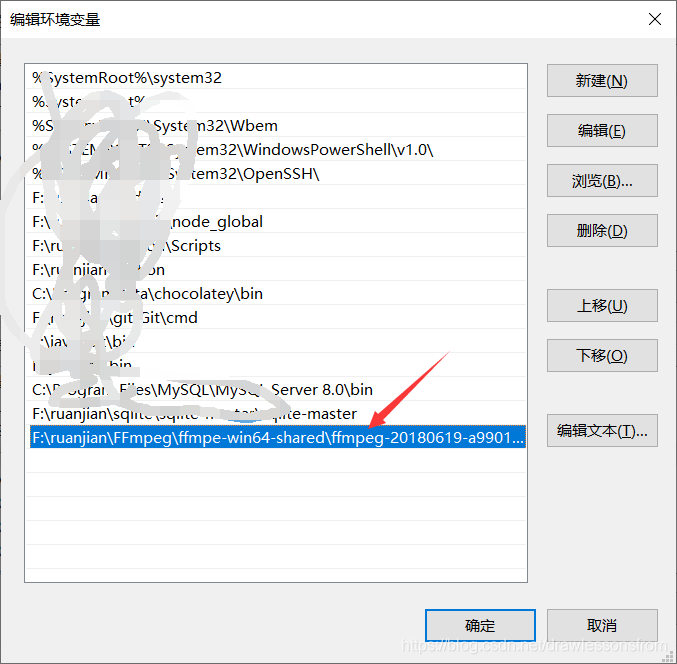
最后一直进行确定配置好相关的环境。
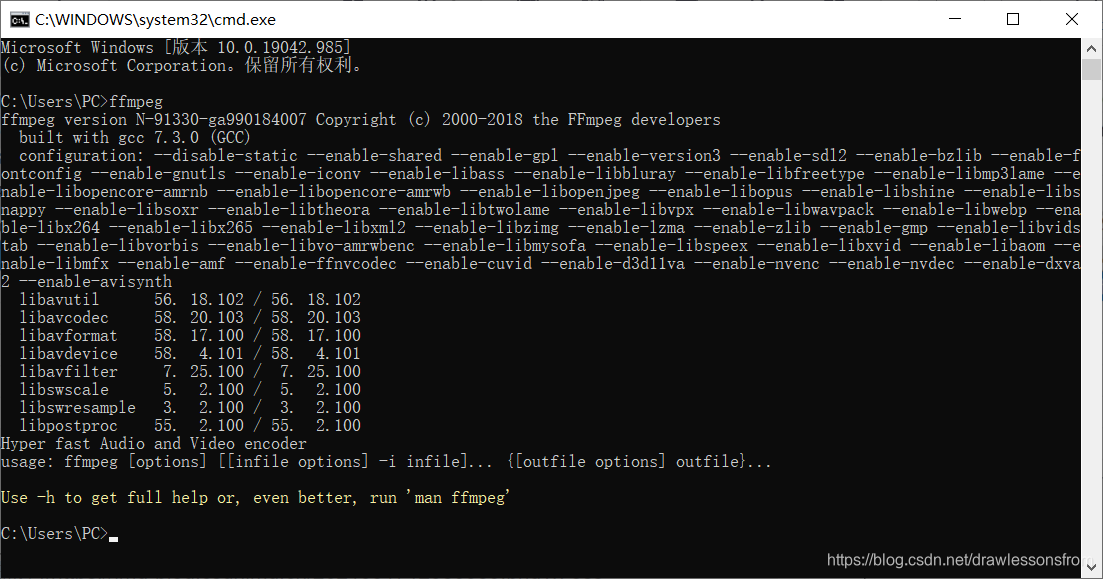
验证ffmpeg是否安装成功:
打开终端系统,然后输入如下命令:
ffmpeg
如果出现如下所示的界面,则安装成功。
如果需要将.mp3的音频文件转成.pcm的音频文件,可以执行如下相关的命令进行转化:
ffmpeg -y -i test.mp3 -acodec pcm_s16le -f s16le -ac 1 -ar 16000 test.pcm
相关代码的具体实现
from aip import AipSpeech
import os
# 百度语音创建的应用中所对的三个参数
APP_ID = '应用AppID的值'
API_KEY = '应用API Key的值'
SECRET_KEY = '应用Secret Key的值'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 语音转文字
def voiceToText(filename):
os.system(f'ffmpeg -y -i {filename}.mp3 -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filename}.pcm')
with open(f'{filename}.pcm', 'rb') as f:
res = client.asr(f.read(), 'pcm', 16000, {
'dev_pid': 1536
})
return res.get('result')[0]
# 文字转语音
def textTovoice(text):
res = client.synthesis(text, 'zh', 1, {
'vol': 5,
'per':4
})
if not isinstance(res, dict):
with open('audio.mp3', 'wb') as f:
f.write(res)
os.system('audio.mp3')
text = '你好!'
textTovoice(text)
os.system('audio.mp3')
注意:
APP_ID = '应用AppID的值'
API_KEY = '应用API Key的值'
SECRET_KEY = '应用Secret Key的值'
以上相关的值分别对应于以下相关应用的值


















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









