




 这篇博客介绍了使用Python进行网页数据爬取的基本步骤,包括requests库获取网页源代码,BeautifulSoup解析HTML,以及遇到的如编码问题、版本不兼容和反爬虫机制的处理。此外,还分享了如何设置UserAgent避免被反爬,并强调理解HTML页面结构的重要性。
这篇博客介绍了使用Python进行网页数据爬取的基本步骤,包括requests库获取网页源代码,BeautifulSoup解析HTML,以及遇到的如编码问题、版本不兼容和反爬虫机制的处理。此外,还分享了如何设置UserAgent避免被反爬,并强调理解HTML页面结构的重要性。
一、涉及的Python库
requests:获取网页源代码
BeautifulSoup:从网页中抓取数据
xlwt:导出表格
(一)requests
1.requests库文档:
requests库文档链接
2.request库的常用方法:
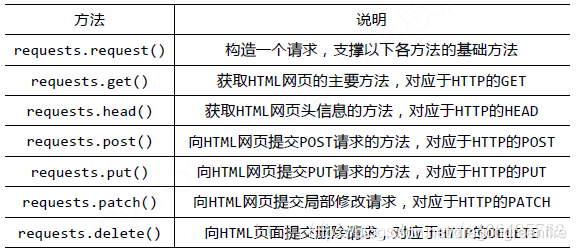
3.编写代码
#导入requests模块
import requests
#输入想获取的网页
url = 'https://movie.douban.com/chart'
#创建一个名为html的response对象
html = requests.get(url)
#设置系统默认编码为UTF-8,防止乱码
html.encoding='utf-8'
(二)beautifulsoup
1.简介:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式
2.beautifulsoup官方文档:
Beautiful Soup 4.4.0 文档链接
3.基本操作
from bs4 import BeautifulSoup
#使用BeautifulSoup解析这段代码,得到一个BeautifulSoup对象
soup=BeautifulSoup(html,'html.parser')
#按照标准的缩进格式的结构输出
print(soup.prettify() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5108
5108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









