




 本文阐述了机器学习的基本步骤,包括模型选择、损失函数确定及函数优化,并介绍了常见的分类、回归、聚类和降维算法,为初学者提供了一个全面的入门指南。
本文阐述了机器学习的基本步骤,包括模型选择、损失函数确定及函数优化,并介绍了常见的分类、回归、聚类和降维算法,为初学者提供了一个全面的入门指南。
机器学习
机器学习可以看作是寻找一个函数,输入是样本数据,输出是期望的结果,只是这个函数过于复杂,以至于不太方便形式化表达。
机器学习步骤
通常学习一个好的函数,分为以下三步:
1、选择一个合适的模型,这通常需要依据实际问题而定,针对不同的问题和任务需要选取恰当的模型,模型就是一组函数的集合。
2、判断一个函数的好坏,这需要确定一个衡量标准,也就是我们通常说的损失函数(Loss Function),损失函数的确定也需要依据具体问题而定,如回归问题一般采用欧式距离,分类问题一般采用交叉熵代价函数。
3、找出“最好”的函数,如何从众多函数中最快的找出“最好”的那一个,这一步是最大的难点,做到又快又准往往不是一件容易的事情。常用的方法有梯度下降算法,最小二乘法等和其他一些技巧(tricks)。
学习得到“最好”的函数后,需要在新样本上进行测试,只有在新样本上表现很好,才算是一个“好”的函数。
官方文档:
https://scikit-learn.org/stable/
https://en.wikipedia.org/wiki/Machine_learning

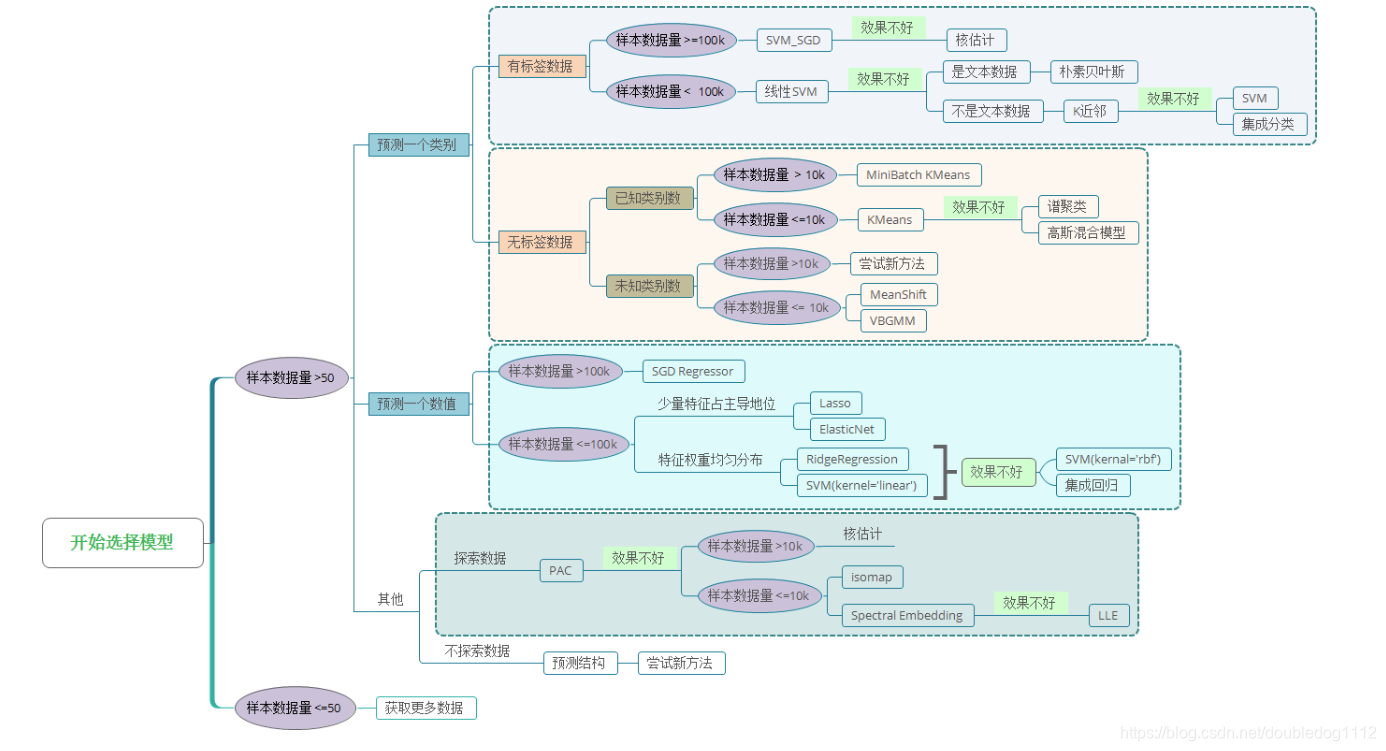
可以看到库的算法主要有四类:分类,回归,聚类,降维。
分类和回归是监督式学习,即每个数据对应一个 label。
聚类 是非监督式学习,即没有 label。
另外一类是 降维,当数据集有很多很多属性的时候,可以通过 降维 算法把属性归纳起来。例如 20 个属性只变成 2 个,注意,这不是挑出 2 个,而是压缩成为 2 个,它们集合了 20 个属性的所有特征,相当于把重要的信息提取的更好,不重要的信息就不要了。
然后看问题属于哪一类问题,是分类还是回归,还是聚类,就选择相应的算法。
可以发现有些方法是既可以作为分类,也可以作为回归,例如 SGD。
常用的回归:线性、决策树、SVM、KNN ;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用的分类:线性、决策树、SVM、KNN,朴素贝叶斯;集成分类:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用聚类:k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN
常用降维:LinearDiscriminantAnalysis、PCA
参考文档:
原文:https://blog.youkuaiyun.com/u014248127/article/details/78885180
原文:https://blog.youkuaiyun.com/hohaizx/article/details/80584307

















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









