



 本文指导如何在Linux系统中克隆并安装COCOAPI,包括从GitHub或Gitee获取源码,放置图像和注释数据,解决Python接口安装时的错误,以及验证安装成功的步骤。主要问题是make过程中的python版本问题,通过更新makefile和安装Cython来解决。
本文指导如何在Linux系统中克隆并安装COCOAPI,包括从GitHub或Gitee获取源码,放置图像和注释数据,解决Python接口安装时的错误,以及验证安装成功的步骤。主要问题是make过程中的python版本问题,通过更新makefile和安装Cython来解决。
参考博客:https://blog.youkuaiyun.com/ccbrid/article/details/79368639
在linux上
步骤
1.git clone cocoapi
github:
git clone https://github.com/pdollar/coco.git
gitee镜像(我用的这个):
git clone https://gitcode.net/mirrors/cocodataset/cocoapi.git
2.进入文件夹
cd coco
或者是
cd cocoapi
总之进入刚刚clone下来的文件夹
3.放入image和annotation
mkdir images
mkdir annotations
分别放官网https://cocodataset.org/#download下载的image和annotation文件夹(里面包含json),这里我只放了annotation就可以跑api里的demo了
我下载的数据如下:

解压后长这样:
我需要用的是captions
4.安装pythoncocoapi接口
cd PythonAPI
make
这里make报错
error: pycocotools/_mask.c: No such file or directory
解决参考:https://blog.youkuaiyun.com/ITtjt/article/details/122062849
解决方案:
pip install Cython
pip install pycocotools
将makefile文件中的python换成python3
5.在python中import pycocotools不报错,即安装成功
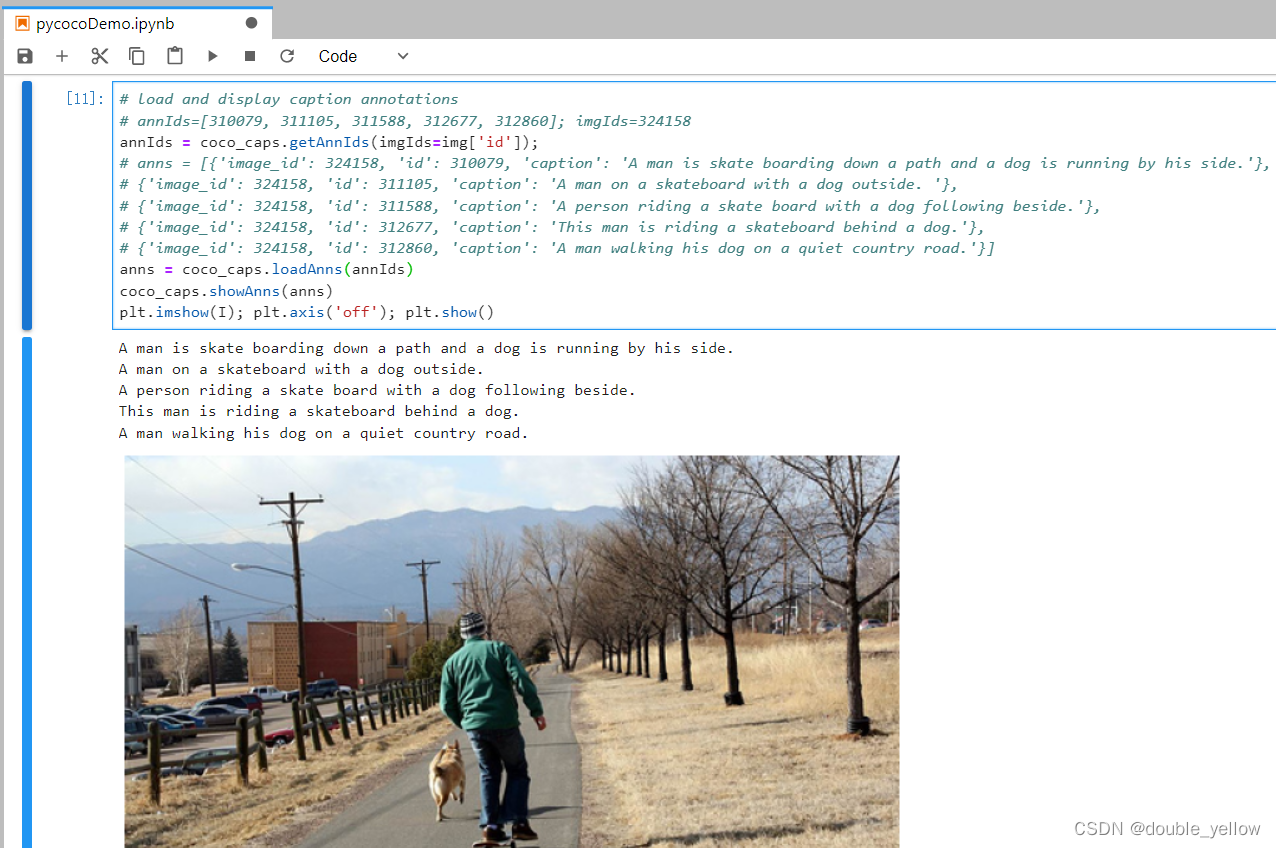
6.使用clone内容内pythonapi中的demo代码,就能用caption了


















 4893
4893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









