




 本文详细记录了使用larbin进行网页爬取,通过BeautifulSoup和pandas处理数据,转化为xunsearch可用格式,并配置搜索引擎实现搜索功能的过程。适合初学者理解爬虫与搜索集成。
本文详细记录了使用larbin进行网页爬取,通过BeautifulSoup和pandas处理数据,转化为xunsearch可用格式,并配置搜索引擎实现搜索功能的过程。适合初学者理解爬虫与搜索集成。
参考:https://blog.youkuaiyun.com/chh13502/article/details/112985864
本文为该大佬项目的试错版菜鸡复盘
总框架:
一、准备工作:下载VMWare和Ubuntu,配环境python3+apache+php,在github上按照官方文档下载larbin
二、爬虫:使用larbin,爬出信息,信息在larbin/build/save里
三、爬取信息的转化:写一个python解析器程序,利用beautifulsoup4和pandas库将爬取的信息转换为xunsearch能利用的csv文件
四、生成网页:用xunsearch分析csv文件,生成骨架代码,将骨架代码放在var/www/html中
五、使用搜索引擎:打开浏览器访问php文件
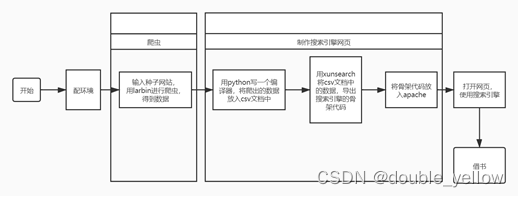
具体流程+注意事项:
①下载VMWare和Ubuntu
②配环境python3+apache+php(能用什么版本就用什么版本)
php5配置出错怎么办:https://blog.youkuaiyun.com/Tdbtx_j/article/details/79464535
解决办法:终端中输入
sudo apt-get install -y language-pack-en-base
sudo LC_ALL=en_US.UTF-8 add-apt-repository ppa:ondrej/php
sudo add-apt-repository ppa:ondrej/php
sudo apt-get update
apt-cache search php5
sudo apt-get install php5.5-common
sudo apt-get install libapache2-mod-php5.5
(最后两条代码中的php5.5根据倒
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









