






对于一些基于TCP Socket的大型C/S应用来说,能进行跨服务器通信可能是一个绕不开的功能性需求。出现这种需求的场景类似于下面描述的这种情况。
假设,我们一台TCP应用服务器能同时承载10000人同时在线,而同时在线用户数量通常为5万多,那可想而知,我们需要部署6台TCP应用服务器来分担这些负载。再假设,我们的应用中,任意的两个客户端都有可能需要互发消息(比如,传送文件),这时问题就来了 -- 因为要互发消息的这两个客户端连接的可能是不同的服务器。
如何解决了?这就需要引入群集平台的概念。群集平台中有一个应用群集管理服务器ACMS可以将所有的TCP应用服务器管理起来,并且能在它们之间转发消息。这样,即使位于不同的TCP应用服务器上的客户端之间也可以相互发送消息了。结构模型简化后如下所示:

以上图为例,两个客户端Client01与Client02分别连上不同的应用服务器AS01和AS02,我们假设由于路由器的原因(比如两个路由器的NAT类型都是Symmetric),Client01与Client02之间的P2P通道没有建立成功。此时,如果Client01与Client02之间要相互沟通信息,那么信息就会经过ACMS中转。比如Client01要发信息给Client02,信息经过的路线将会是:Client01 => AS01 => ACMS => AS02 => Client02。
能简单地实现这种模型吗?并且让这种跨服务器通信对于客户端而言是透明的?当然,基于ESPlatform群集平台,我们很容易做到这一点。 本文我们就实现一个这样的demo。我们之前有个老的简单的IM的Demo,它演示了客户端与服务器、以及客户端与客户端之间的基本通信功能。只不过,在那个Demo中,相互通信的客户端连上的是同一个服务端。本文的Demo就是在那个老Demo的基础上来进行升级,使得位于不同服务器上的两个客户端之间也可以相互通信。
一.Demo项目结构
本Demo总共包含4个项目。
1.ESPlatform.ACMServer:这个是基于ESPlatform的应用群集服务器ACMS。
2.ESPlatform.SimpleDemo.Core:用于定义公共的信息类型、通信协议。
3.ESPlatform.SimpleDemo.Server:Demo的服务端。
4.ESPlatform.SimpleDemo.Client:Demo的客户端。
二.应用群集管理服务器ACMS
我们不需要对ACMS进行任何修改,只需要关注配置文件中TransferPort和Remoting端口的值。

<configuration> <appSettings> <!--应用群集中的服务器分配策略--> <add key="ServerAssignedPolicy" value="MinUserCount"/> <!--用于在AS之间转发消息的Port--> <add key="TransferPort" value="12000"/> </appSettings> <system.runtime.remoting> <application> <channels> <!--提供IPlatformCustomizeService和IClusterControlService Remoting服务的Port--> <channel ref="tcp" port="11000" > <serverProviders> <provider ref="wsdl" /> <formatter ref="soap" typeFilterLevel="Full" /> <formatter ref="binary" typeFilterLevel="Full" /> </serverProviders> <clientProviders> <formatter ref="binary" /> </clientProviders> </channel> </channels> </application> </system.runtime.remoting> </configuration>
三.Demo服务端
在升级老的Demo时,首先需要添加ESPlatform.dll的引用,然后,使用ESPlatform.dll程序集中的ESPlatform.Rapid.RapidServerEngine替代ESPlus.Rapid.RapidServerEngine,并在构造函数中指定:当前服务端实例的ID、ACMS的IP地址及其TransferPort和Remoting端口。
//使用简单的好友管理器,假设所有在线用户都是好友。(仅仅用于demo) ESPlatform.Server.DefaultFriendsManager friendManager = new ESPlatform.Server.DefaultFriendsManager(); this.engine = new ESPlatform.Rapid.RapidServerEngine(int.Parse(this.textBox_serverID.Text), this.textBox_acmsIP.Text, int.Parse(this.textBox_acmsPort.Text) ,int.Parse(this.textBox_transferPort.Text)); this.engine.FriendsManager = friendManager; this.engine.Initialize(int.Parse(this.textBox_serverPort.Text), new CustomizeHandler(), new BasicHandler()); friendManager.PlatformUserManager = this.engine.PlatformUserManager;
其它的部分与老Demo完全一致。
四.Demo客户端
相对于老的Demo而言,客户端的修改非常小,只是将配置文件中的服务器的IP和端口移到了登录界面上,这样方便指定要连接的服务端的地址。除此之外,没有其它变化,甚至,客户端的项目都不需要引用ESPlatform.dll。
五.运行Demo
1.启动应用群集管理服务器ACMS。
2.启动第一个服务端,ServerID指定为0,监听6000端口。
3.启动第二个服务端,ServerID指定为1,监听6001端口。
4.启动第一个客户端,连接ServerID为0的服务端。
5.启动第二个客户端,连接ServerID为1的服务端。
6.两个客户端之间可以相互对话了。
(在正式的应用场景中,ACMS、两个服务端、两个客户端 可以部署在不同的机器器上)
下图是Demo运行起来的效果:
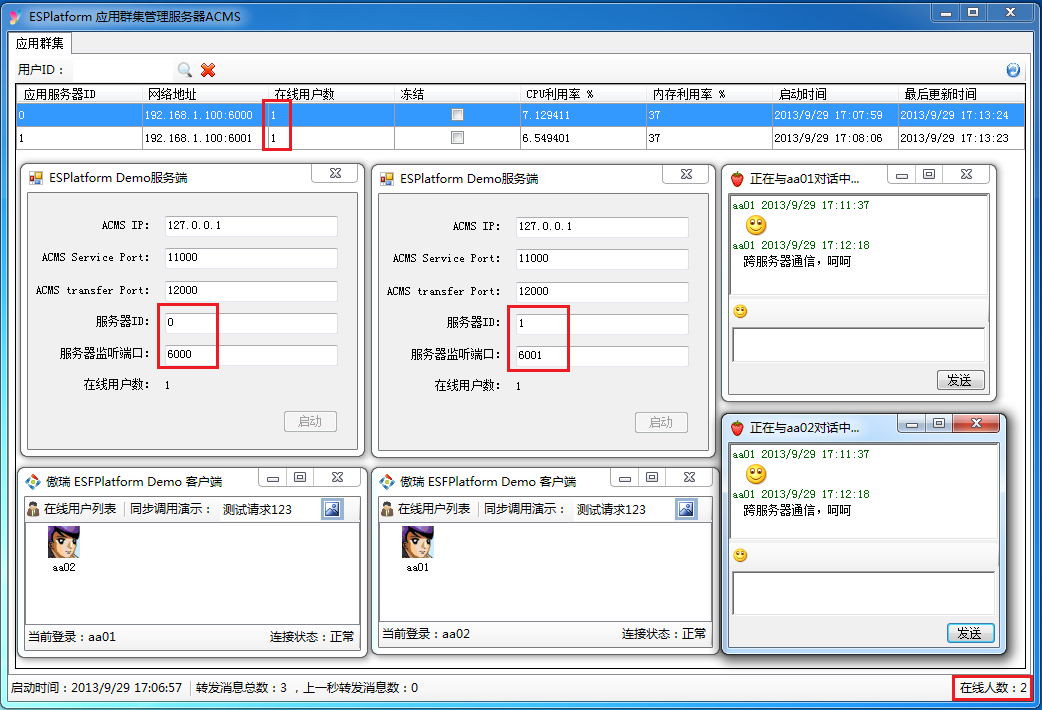
题外话:从上图中可以看到,ACMS实时知道每台应用服务器的在线人数、CPU利用率、内存利用率等信息,基于这些信息,我们可以轻松实现简单的负载均衡的机制 -- 比如,党有一个新的客户端要登录时,我们可以指派它去连接那个在线人数最少的应用服务器,或者,CPU利用率最低的应用服务器。

















 172万+
172万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









