






 本文分享了使用LIBSVM进行文本分类的经验,探讨了特征选择方法,包括词频法和信息增益法,并对比了不同设置下的分类效果。
本文分享了使用LIBSVM进行文本分类的经验,探讨了特征选择方法,包括词频法和信息增益法,并对比了不同设置下的分类效果。
最近期末事儿比较多,没什么大东西,最近在使用libsvm做文本分类,虽然感受到了LIBSVM的便捷之处,但是也感受到了Libsvm的调参的复杂性,写下来Mark一下
文本分类,使用的是路透社的语料最为训练和测试数据集,原始的语料有91类大概十几万篇文章,由于以一些类的数量太少(本次实验室将一个类别下的文本数量少于100篇的过滤)而不具备训练价值(对于有监督的学习而言),最后我们得到的是8个类别,包括训练数据集合测试数据集
文本分类的处理主要包括三个方面,第一,特征抽取;第二,特征选择;第三,机器学习方法训练模型【1】,特征抽取可以看做是文本的预处理,包括去停用词、去标点符号、同义词合并(如compute和computing),本次实验没有考虑到同义词合并,当然也有现成的算法来做处理。
伦理片 http://www.dotdy.com/
特征选择是选出能代表文本内容和能和其他文档有区分度的token(token不太好翻译,可以把它想象成单词,汉字之类的),主要的方法有:
1,词频法TF,也就是选取一个类别的频率比较高的若干个词
2,信息增益法Information Gain,信息增益法是文本处理中比较常用的预处理方法的一种,计算公式是
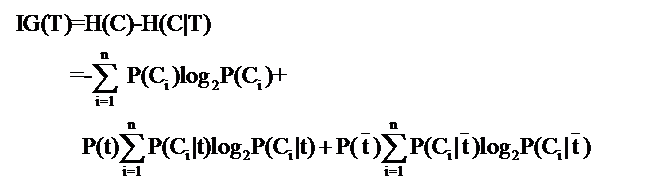
说明:公式中的东西看上去很多,其实也都很好计算。比如P(Ci),表示类别Ci出现的概率,其实只要用1除以类别总数就得到了(这是说你平等的看待每个类别而忽略它们的大小时这样算,如果考虑了大小就要把大小的影响加进去)。再比如P(t),就是特征T出现的概率,只要用出现过T的文档数除以总文档数就可以了,再比如P(Ci|t)表示出现T的时候,类别Ci出现的概率,只要用出现了T并且属于类别Ci的文档数除以出现了T的文档数就可以了。【2】
得到每个词的信息增益值之后,就可以把这些词从大到小的顺序呢排列,选取前面指定数量的词作为特征词(数量的多少需要根据文本数量和单词总数自己调节得到最优化)
3.卡法检测法
卡法检测法也是一种比较简单常用的方法,公式如下【3】

最后运用机器学习的方法对训练集进行模型训练即可
落实到本实验上,本实验主要使用LIBSVM,特征选择的方法主要是使用了信息增益和词频的方法
第一步,预处理文档:
预处理文档主要包括去除停用词,去除标点数字等无效token,主要的处理方法代码如下:

- private void processTextString(String str){
- str=str.replaceAll("[().,<>'\":-]", " ").replaceAll("[\\\\/]", " ").replaceAll("[0-9]"," ").toLowerCase().replaceAll("(author.*author)", "");//1
- String []words=str.split(" ");
- String newStr="";
- String line="";
- for(String word:words){
- word=word.trim().toLowerCase();
- if(!stopwords.contains(word) ){ //2
- if(line.length()>100){
- newStr+=line+"\r\n"+" ";
- line="";
- }else{
- line+=word+" ";
- }
- }
- }
- fh.writeToFileNonRandom(newStr);
- }
其中,1是为了去除数字和一些符号,2是为了去除停用词
第二步,特征抽取与选择,这里我尝试了两种方法,词频和信息增益的方法
词频的方法比较简单,就是选取每个类的前几个词频比较高的词语,然后将每个类的这些词合并到一起作为最后的特征词
信息增益的计算方法是根据上文提到的计算公式计算每个不重复单词的信息增益值,然后根据其信息增益值按照从大到小的顺序排列
主要代码如下:前者是词频方法,后者是信息增益方法
- public void getFeatureVector() throws IOException{
- //选择特征词
- feature_words=new ArrayList<String>();
- for(Map.Entry<Integer, Map<String,Integer>> entry:cwf.entrySet()){
- Map<String,Integer> wf=entry.getValue();
- int cat=entry.getKey();
- int count=0;
- int val=0;
- /*if(wf.size()<80){
- val=200;
- }else{
- val=100;
- }*/
- //二分类给个25就行了
- for(Map.Entry<String, Integer> nEntry: wf.entrySet()){
- if(count<=200){ //说明,每类提取前200个词频最高的词语作为特征词
- String word=nEntry.getKey();
- if(!feature_words.contains(word)){
- feature_words.add(word);
- System.out.println(word);
- }else{
- feature_words.remove(word);
- }
- count++;
- }
- }
- }
- System.out.println("feature: "+feature_words.size());
- //抽取文档词向量
- File rootFile=new File(Constants.ROOT_PATH);
- File testFile=new File(Constants.TEST_PATH);
- processFileVector(rootFile);
- fHelper=new FileHelper(Constants.TEST_FEATURE_PATH);
- processFileVector(testFile);
- }
- public void getFeatureVector() throws IOException{
- //选择特征词
- Map<String,Double> sortMap=MapSort.sortMapByValue(wordScore);
- feature_words=new ArrayList<>();
- int count=0;
- System.out.println("sortMap size: "+sortMap.size());
- for (Entry<String, Double> entry : sortMap.entrySet()){
- //before 16500
- if(count<16500){ //选取信息增益值前16500的词语作为特征词
- String feature_word=entry.getKey();
- feature_words.add(feature_word);
- }
- count++;
- }
- //抽取文档词向量
- File rootFile=new File(Constants.ROOT_PATH);
- File testFile=new File(Constants.TEST_PATH);
- processFileVector(rootFile);
- fHelper=new FileHelper(Constants.TEST_FEATURE_PATH);
- processFileVector(testFile);
- }
选取到特征词之后,就可以对训练集和测试集计算得到词向量,注意这里采用的是词袋模型,词语之间没有顺序关系。
得到词向量之后就可以使用LIBSVM进行训练了,训练的代码不多,就几行
- /*ExtractFeatureVector3 ef=new ExtractFeatureVector3();
- ef.loadDataSet();
- ef.sortCWF();
- ef.getFeatureVector();*/ //词频
- ExtractFeatureVector2 ef=new ExtractFeatureVector2();
- ef.loadDataSet(); //采用IG
- ef.calcWordScore();
- ef.getFeatureVector();
- String[] trainArgs = {Constants.TRAIN_FEATURE_PATH};//directory of training file
- String modelFile = svm_train.main(trainArgs);
- String[] testArgs = {Constants.TEST_FEATURE_PATH, modelFile, Constants.TEST_FEATURE_RESULT};//directory of test file, model file, result file
- svm_predict.main(testArgs);
上面代码中,第一个注释的是采用词频的特征选择方法。
最后来比较一下结果:
对于二分类:
使用词频分类的参数是,每类选取前25个词频最高的词作为特征词,整个的特征向量也就40多维,测试数据集是目录下面的tmp1文件夹,但是结果惊人,达到了94%
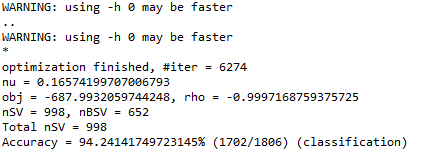
使用信息增益的方法是选取前13500维度的词作为特征词,结果为:
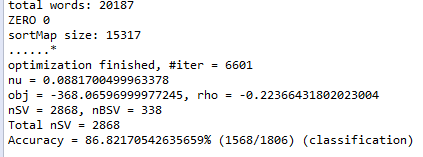
然后我们比较了一下八分类:
对于词频的方法,每类选取前200个最高频的词,然后八个类一起作为特征向量。结果如下:
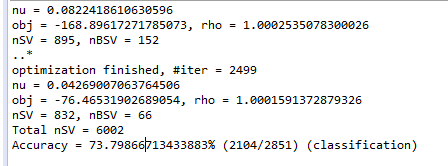
对于信息增益的方法:我们选取信息增益值前16500个词作为特征词,结果如下
影音先锋电影 http://www.iskdy.com/
可见LIBSVM对于多类的分类准确性明显没有二分类准确,当然这里也存在着一个问题,就是分类数据的均匀问题,在测试数据集里有两个类的训练数据比其他类都要多,而对于数据比较多的类,SVM往往在计算函数间隔的时候会将线性空间的划分倾向这些数据比较多的类,这样也会造成一些准确率损失,因此尽量选择的语料是均匀的,如果不均匀的话就需要考虑额外的优化算法,现在也有不少的研究,谷歌学术一查一大把。
最后,我说一下LIBSVM的优化情况,
我也是刚开始使用LIBSVM,对这个优化不是很了解,但是也是看了一些资料,可以参考下【3--5】
其实LIBSVM主要的步骤有5:
1)按照LIBSVM软件包所要求的格式准备数据集;
2)对数据进行简单的缩放操作;
3)首要考虑选用RBF 核函数;
4)采用交叉验证选择最佳参数C与g ;
5)采用最佳参数C与g 对整个训练集进行训练获取支持向量机模型;
6)利用获取的模型进行测试与预测。
其中2-4是LIBSVM的优化,第二部的缩放也叫归一化操作,归一化的命令式:svm-scale.exe -l 0 -u 1 train.txt > train-scale.txt,其中-l表示归一化的下界 -u表示归一化的上界,train.txt是原始特征值,trainscale.txt是归一化后的特征值,需要说明的是归一化并不一定会带来准确度提升,而且有可能造成特征值文本大小骤增
对于第三步,从实验结果上看,对于大数据(特征值远大于文档词数)的训练还是采用线性模型比较好,因为特征向量的维度已经很多了,不需要再映射到一个更高的维度
对于第四步骤,现在可以使用grid.py或者easy.py进行调优,调优步骤详见【4】,很遗憾,这个实验没有调出来,一直在报:RuntimeError: get no rate 错误,调了半天也没调成功
LAST BUT NOT LEAST
综合这个实验来看,信息增益的方法对于数据集不均匀的训练集,往往不会有好的效果,因为对于比较大的一类数据,其中的与其他类不一致的token可能过多,导致最终的得到的特征词向量中包含在该类的token数量过多,达不到很好的效果,而使用词频可以避免该问题,但是词频的分类效果不是很好,当然还有很多其他的特征选择方法,这里我没有一一尝试。
还有一点,不知道是不是我的特征向量训练的不是很好,LIBSVM对于多分类的问题支持并不是很给力,这点还有待日后研究
相应的程序和数据集都在下面给出来了.

















 2607
2607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









