



本人有时会看一些论文,发现每次下载附页后的一大堆引用论文很麻烦,我之前是使用tb等平台购买的收费数据库,来手动搜索解决问题,但是发现这些代理网站稳定性不高,通常访问几次就要重新刷新页面,所以就有了编写一个自动化下载论文的点子,这篇文章介绍了,我在开发中碰到的各种技术问题,提供给各位网友参考。
要下载论文,当然首先要解决:寻找到一个适合的数据库,稳定下载论文,这种国外有一些,最出名的就是scihub(https://sci-hub.se/),除了这两年最新的论文,基本80%的论文都能找到,剩下的我们可以手动去谷歌或官方论文平台找,因为scihub是通过论文的doi找论文,而一般文章中没有写doi号,只有一个论文名字,所以我们需要找一个论文名转换doi的方法,通过gpt我确实找到了一个简单的api,只要传入一个论文名可以较为准确的找到相应的doi(前面的这段文字是我两周以前写的,但是我觉得还是保留着更好,因为有些读者有时可能会用到这个搜索doi的功能api,这个api我封装成了一个小函数,有兴趣的同学可以试试,查出的doi可能没有这么准,我在后面的文章中会介绍另一种方法)
import requests
# 通过论文名查询DOI(可能不准)
def get_doi_by_title(title):
url = "https://api.crossref.org/works"
params = {
"query.title": title,
"rows": 1 # 最相关的1条
}
res = requests.get(url, params=params)
j = res.json()
if (
"message" in j and
"items" in j["message"] and
len(j["message"]["items"]) > 0
):
return j["message"]["items"][0].get("DOI")
else:
# 打印调试信息
print("未查到DOI,API原始返回:", j)
return None简单介绍下这个函数,参数title就是需要查询的论文名,直接传入就能得到函数返回的doi号。可以使用如下代码调用上面的代码:
title = "论文名"# 替换你自己的论文名称
doi = get_doi_by_title(title)# 调用上面的函数返回doi
print(doi)# 打印输出doi
因为在本周,scihub官网更新过了,增加了防御ddos的验证码,所以我两周前编写的爬取scihub上论文的代码都不能用了,所以昨天我用selenium重新编写了一个,考虑到scihub的验证码比较复杂,所以请大家每次运行爬取代码前都输入一遍验证码就行,因为selenium会打开一个chrome浏览器的窗口,所以运行我的程序前,请安装下chrome浏览器(微软的edge浏览器不行),另外因为scihub需要代理才能访问,请大家自行准备,并设置成全局代理。scihub的验证窗口如下图:
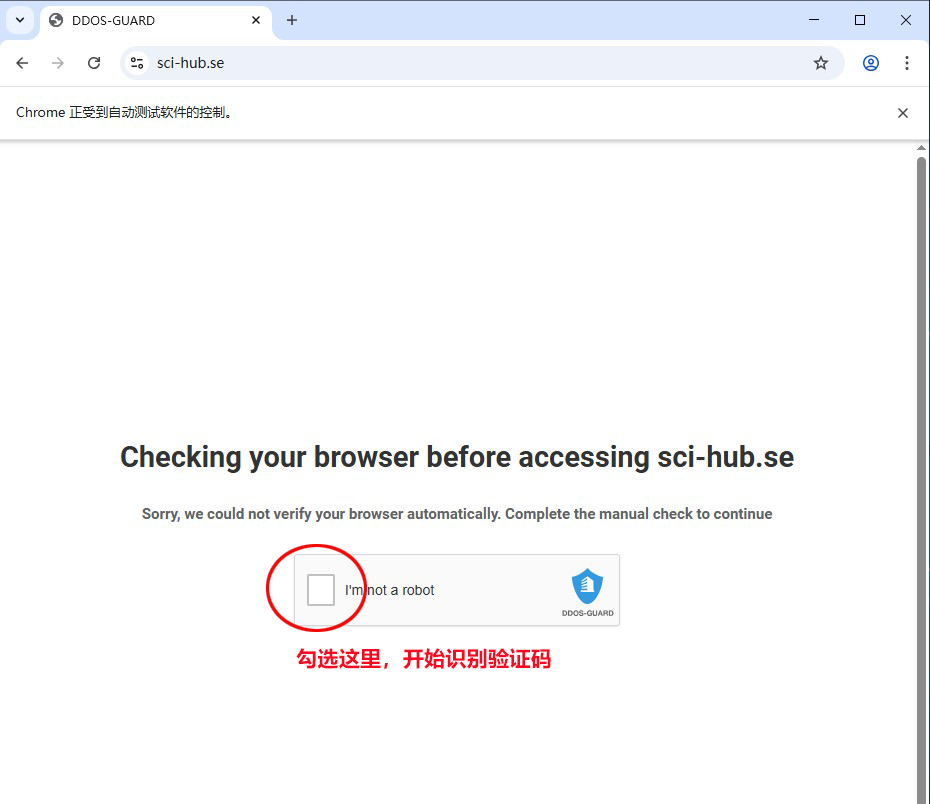
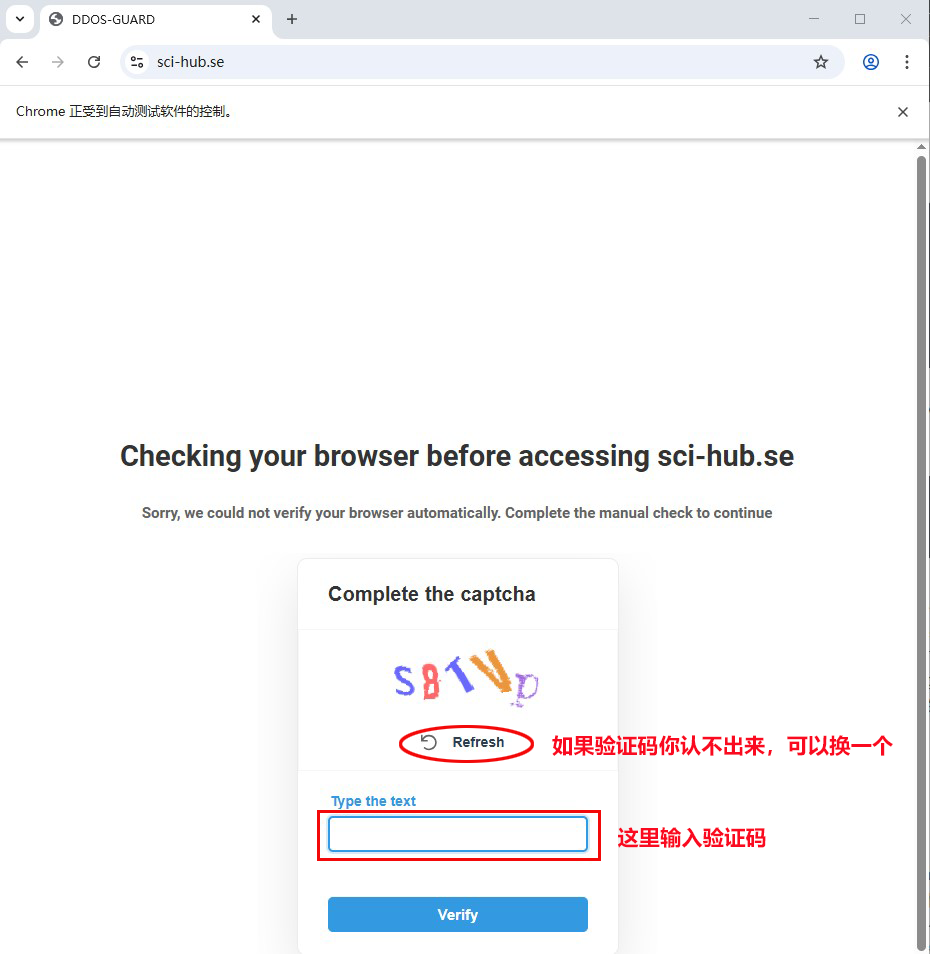 验证码输入成功后,就会进入我的爬虫程序,自动批量爬取论文,因为考虑到爬取论文是大家的主要目的,所以我决定开源这部分的代码,如下:
验证码输入成功后,就会进入我的爬虫程序,自动批量爬取论文,因为考虑到爬取论文是大家的主要目的,所以我决定开源这部分的代码,如下:
# Author: dong
# Date: 2025-06-20
# Description: This script is used for batch downloading papers from Sci-Hub.
import os
import time
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
project_path = "37.自动论文翻译\\完成版\\"
delay = 3
def main(titles):
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://sci-hub.se/"
title = "Image completion with structure propagation"
header = {
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-encoding":"gzip, deflate, br, zstd",
"accept-language":"zh-CN,zh;q=0.9",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0"
}
fail_download = []
title_index = 0
folder_path = f"{project_path}download\\"
if not os.path.exists(folder_path):
os.makedirs(folder_path, exist_ok=True)
print("开始下载论文程序...")
for title in titles:
title_index += 1
title = title.replace(":", "")
# 打开网页
print(f"==============================开始下载 {title_index}.{title}==============================")
if os.path.exists(f"{project_path}download\\{title_index}.{title}.pdf"):
print("\033[42m", "此论文已下载,链接如下:", f"{project_path}download\\{title_index}.{title}.pdf", "\033[0m")
continue
print("\033[34m", f"1.正在查找论文链接...", "\033[0m")
driver.get(url) # 这里换成实际网页地址
while True:
try:
textarea = driver.find_element(By.ID, "request")
print("\033[32m", "2.网页已验证,正在查询论文...\033[0m")
break
except Exception:
# 没有找到就等待一会再查找
time.sleep(1)
print("\033[31m弹出网页,请手动验证!\033[0m")
time.sleep(delay)#延迟
print("\033[34m", "3.尝试打开论文链接...", "\033[0m")
ret = get_pdf_url(driver, title_index, textarea, title, header)
if not ret:
fail_download.append((str(title_index) + "." + title))
if fail_download:
print("\033[31m", "下载失败的论文:")
print("\n".join(fail_download),"\033[0m")
print("\033[42m下载已完成!\033[0m")
driver.quit()
def get_pdf_url(driver, title_index, textarea, title, header):
# 输入内容
textarea.send_keys(title)
# 还可以模拟按下 Enter 提交(相当于点击按钮)
textarea.send_keys(Keys.ENTER)
try:
element = WebDriverWait(driver, 60, 0.5).until(
lambda d: d.find_element(By.ID, "article") if len(d.find_elements(By.ID, "article")) > 0
else (d.find_element(By.ID, "smile") if len(d.find_elements(By.ID, "smile")) > 0 else False)
)
# print("找到元素:", element.get_attribute("id"))
if element.get_attribute("id") == "smile":
print("\033[33m", "4.没有找到这篇论文!\033[0m")
return False
print("\033[32m","4.论文页面 已加载!\033[0m")
# 可以后续输入内容等操作
# 2. 查找 <embed id="pdf">
embed = driver.find_element(By.ID, "pdf")
# 3. 获取 src 属性(PDF 链接)
pdf_url = embed.get_attribute("src")
# 4. 如果是 // 开头,补全协议前缀
if pdf_url.startswith("//"):
pdf_url = "https:" + pdf_url
print(pdf_url)
pdf_url = pdf_url.replace("#navpanes=0&view=FitH", "")
pdf_url = pdf_url.replace("#navpanes=0&view=FitH", "")
print("\033[36m", "5.读取PDF下载链接:", pdf_url, "\033[0m")
if pdf_url:
res = requests.get(pdf_url,headers=header)
# print(res.status_code)
if res.status_code == 200:
with open(f"{project_path}download\\{title_index}.{title}.pdf", "wb") as f:
f.write(res.content)
print("\033[32m", f"6.论文: {title_index}.{title} 已下载成功!", "\033[0m")
print("\033[32m", f"(文件路径: {project_path}download\\{title_index}.{title}.pdf)", "\033[0m")
return True
else:
print("\033[31m论文下载失败!(链接无法访问)\033[0m")
return False
except Exception as e:
# print("等待超时,页面未找到该 textarea!")
print("\033[31m程序出错:", e, "\033[0m")
return False
if __name__ == "__main__":
titles = [
"Authoring effective depictions of reality by combining multiple samples of the plenoptic function",
"Photographing long scenes with multi-viewpoint panoramas",
"Artistic Multiprojection Rendering",
"Seam Carving for Content-Aware Image Resizing",
"PatchMatch: A Randomized Correspondence Algorithm for Structural Image Editing",
"Learning OpenCV: Computer Vision with the OpenCV Library",
"Image warps for artistic perspective manipulation",
"Optimizing content-preserving projections for wide-angle images",
"Silhouette-Aware Warping for Image-Based Rendering",
"Ryan: rendering your animation nonlinearly projected",
"Single View Metrology",
"Perspective Drawing Handbook",
"Photoshop Masking & Compositing",
"Curvilinear Perspective: From Visual Space to the Constructed Image",
"Computer Vision: A Modern Approach",
"Feature-Aware Texturing",
"RTcams: A New Perspective on Nonphotorealistic Rendering from Photographs",
"Realistic or Abstract Imagery",
"Fundamentals of Texture Mapping and Image Warping",
"Geometry and the Imagination",
"Secret Knowledge: Rediscovering the Lost Techniques of the Old Masters",
"Automatic photo pop-up",
"Tour into the picture: using a spidery mesh interface to make animation from a single image",
"As-rigid-as-possible shape manipulation",
"A Model of Saliency-Based Visual Attention for Rapid Scene Analysis",
"Energy-based image deformation",
"Distributed gradient-domain processing of planar and spherical images",
"A system for retargeting of streaming video",
"The psychology of perspective and renaissance art",
"Nonlinear Disparity Mapping for Stereoscopic 3D",
"Content-preserving warps for 3D video stabilization",
"Applied Perspective for Architects and Painters",
"Numerical Optimization",
"Robust Image Retargeting via Axis-Aligned Deformation",
"Optics, Painting & Photography",
"The graph camera",
"Multiple-Center-of-Projection Images",
"Make3D: Learning 3D Scene Structure from a Single Still Image",
"Image deformation using moving least squares",
"Solving Unsymmetric Sparse Systems of Linear Equations with PARDISO",
"Pannini: A New Projection for Rendering Wide Angle Perspective Images",
"Mesh parameterization methods and their applications",
"Summarizing visual data using bidirectional similarity",
"Flattening the Earth, two thousand years of map projections",
"Map Projections – A Working Manual: U.S. Geological Survey Prof. Paper 1395",
"As-Rigid-As-Possible Surface Modeling",
"View Camera Technique",
"Robust Real-Time Face Detection",
"Why pictures look right when viewed from the wrong place",
"StereoBrush: interactive 2D to 3D conversion using discontinuous warps",
"Motion-based Video Retargeting with Optimized Crop-and-Warp",
"Optimized Scale-and-Stretch for Image Resizing",
"Fisheye Video Correction",
"Non-homogeneous Content-driven Video-retargeting",
"Multiperspective Panoramas for Cel Animation",
"WorldWide Telescope",
"General Linear Cameras",
"Automating joiners",
"Squaring the Circles in Panoramas",
"A Shape-Preserving Approach to Image Resizing",
"Parametric Reshaping of Human Bodies in Images",
"Correction of Geometric Perceptual Distortion in Pictures"
"Image completion with structure propagation"
]
main(titles)请自行替换if __name__ == "__main__":后的titles变量,如你所见,想要批量下载论文,只需替换titles论文名,如果觉得构造titles变量麻烦,你可以把论文名复制到deepseek或chatgpt里让它帮你构造下,把我的例子发给dp或gpt就行,注意:请把project_path = "37.自动论文翻译\\完成版\\"中的"37.自动论文翻译\\完成版\\"改成你自己存放代码的目录。下载的代码会放在"你的目录\download"下,比如我的下载目录就是"37.自动论文翻译\完成版\download"。
接下来说说翻译PDF的部分吧!
研究了下网上现存的一些开源的python翻译库,发现最近一年出现了很多新的库,比较有名的就是babeldoc,网址如下:https://github.com/funstory-ai/BabelDOC,这个库好像新出来没多久,但是更新版本很快,很多其他有名的python翻译开源库都有参考它的意思,当然也可能互相参考了吧。
pip install babeldoc # 国外或代理
pip install babeldoc -i https://pypi.tuna.tsinghua.edu.cn/simple # 国内网络环境稍微研究了下babeldoc,发现它能调用deepseek api,通过命令行传入api key就能让deepseek翻译pdf论文,具体的命令如下:
babeldoc --files "input.pdf" -o "output_cn.pdf" --lang-in "en-US" --lang-out "zh-CN" --openai --openai-model "deepseek-chat" --openai-base-url "https://api.deepseek.com" --openai-api-key "sk-xxxxxxxxxxxxx"上面的命令中请添加上自己的deepseek api key:
--openai-api-key "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx" 同时修改如下位置:
--files "input.pdf" # 待翻译文件路径
-o "output" # 输出翻译路径在命令行输入上面构造好的命令后,运行界面如下: 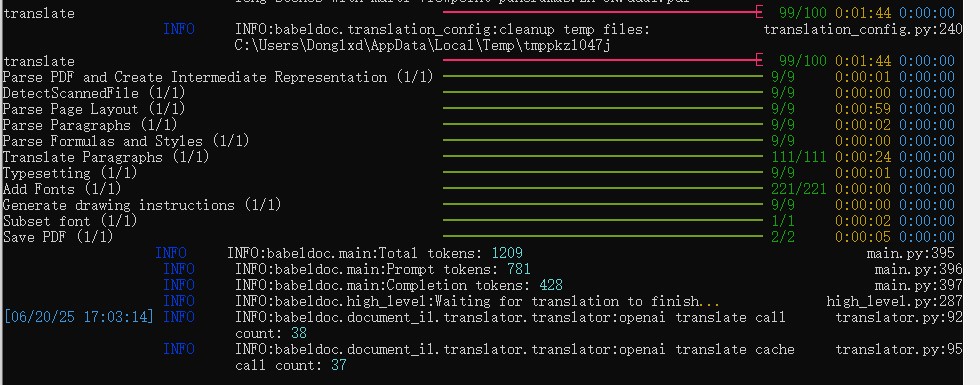
在上面的-o后的目录下会生成两个翻译文件,如图:

上面文件名dual结尾的文件是双语翻译,一页中左边是英文原稿,右边是中文翻译,如下图:

下面的mono是单独中文翻译。
可以看到babeldoc在deepseek的帮助下,翻译的质量很高,加上babeldoc对于pdf的页面布局解析做的相当还原,翻译质量那是确实高,如果和收费那些翻译pdf网站对比,比如有道、百度、彩云小译,翻译质量感觉更好,页面的还原也是无可挑剔的,加上deepseek api这样的性价比,相对收费的那些商业翻译,有限的字数额度限制,那是真香。
不管怎么说babeldoc还是需要有支出(可能我研究babeldoc时间比较短,没发现免费的使用方法,有知道的小伙伴也可以评论区留言),那么有没有一种免费的方法那,因为大家都知道现在的论文动不动就几十上百页,就是用deepseek api也是开销,答案是显然有,不然我也不会提这个问题了,因为babeldoc主页已经告诉我们了,如下图:

就是这个PDFMathTranslate,简称pdf2zh,需要注意的是它需要python3.10以上,python3.12以下(含python3.12),使用如下命令安装:
pip install pdf2zh # 国外或代理环境
pip install pdf2zh -i https://pypi.tuna.tsinghua.edu.cn/simple # 国内网络环境使用如下简单的命令翻译:
pdf2zh document.pdf# 谷歌翻译需代理网络,好像也支持deepseek等api,但需自己构造命令参数请自行替换上面命令的document.pdf为你自己需要翻译的pdf文档目录
这个pdf2zh感觉和上面的babeldoc有点像,显然是参考过它的代码,但是易用性和性价比更高,因为它支持各种免费和收费的搜索api,其中有我们需要的免费谷歌翻译,pdf2zh也是生成两个翻译文件,这点两个库是一致的。
运行上面的翻译命令后,你可以会碰到一个numpy的报错,如下:
File "D:\Program Files\Python\Lib\site-packages\pdf2zh\high_level.py", line 167, in extract_text_to_fp
image = np.fromstring(pix.samples, np.uint8).reshape(pix.height, pix.width, 3)[:, :, ::-1]
~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^
ValueError: The binary mode of fromstring is removed, use frombuffer instead请定位到这个high_level.py文件,修改第167行的代码(可能最近的更新版本已修正错误,不提示此错误请忽略此项说明),如下:
# image = np.fromstring(pix.samples, np.uint8).reshape(pix.height, pix.width, 3)[:, :, ::-1]# 原出错代码
image = np.frombuffer(pix.samples, np.uint8).reshape(pix.height, pix.width, 3)[:, :, ::-1]
# 修改后的代码第一次运行pdf2zh会安装很多模型,等安装完毕后,会出现一个如下的翻译进度条,说明安装成功.
安装模型中,如图:
翻译进度条,如图(可以看到有1152*768的分辨率,每人显示的可能不同):

上面的pdf2zh虽然好,但是有一个问题,有些比较老的论文都是扫描版,可能没有隐藏的可复制文字层,或者是使用ocr识别,但是识别不到位,都是混乱的字符,导致pdf2zh不能翻译,虽然我在pdf2zh说明文档中看到有ocr的参数,但是在最新版里好像已经去掉了,找过pdf2zh识别此类pdf的报错源码,发现也没有相关的ocr识别代码。显然这个ocr识别,是这个项目中比较难搞的东西,但是现在我们有网络、有AI,一般的东西不至于搞不出来,又不是手搓原子弹、cpu。
先在网上找了一圈,然后又在gpt中深度研究了一下,最后在小红书中发现这个github项目--ocrmypdf,它可以生成比较正规的带公式图片、可复制文字的pdf/a,格式文档,但是因为它把ocr识别的文字做成了tr3文字层隐藏,然后上面加了一层原来的图像层来还原原始文稿的样子,导致使用pdf2zh翻译出的pdf,有图像层中的图像文字和翻译后的可见文字,两种文字重叠,影响阅读体验。现在开发走到了死胡同,我当时能想到的是改造ocrmypdf的python源码,找出文字层后,把隐藏的tr3改成可见的tr0层,改了几次后,发现并没这么简单,而且它的源码文件比较多,修改相对复杂很多。没有办法,只能使用gpt的深度研究下ocrmypdf的源码,找出一个可行的ocr提取可见文字的办法,运气很好,确实找到了关键点,原来ocrmypdf也是套壳了谷歌的开源tesseract项目,熟悉ocr的同学一般都知道这个东西,这个东西有点年份了,不过谷歌竟然还在免费更新它,真的让我很意外,记得十几年前刚学编程的时候就使用过它,那时难忘、神奇的回忆马上涌上心头。因为我们的程序需要tesseract,除了需要用pip安装pytesseract,命令如下:
pip install pytesseract还需要安装下tesseract的主程序,网址如下:https://github.com/tesseract-ocr/tesseract/releases/download/5.5.0/tesseract-ocr-w64-setup-5.5.0.20241111.exe
你可以到它的release下载最新版,网址如下:
https://github.com/tesseract-ocr/tesseract/releases
如下是安装完成的界面,点击next完成安装。
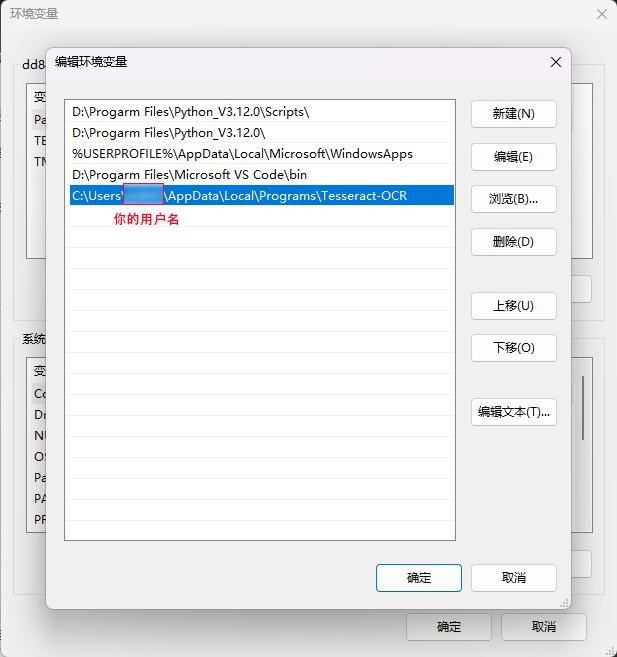
然后在环境变量中添加你自己的tesseract路径(每个人的路径都不一样,主要是用户名不同,下面的截图供大家参考)
安装tesseract后,因为我们需要自己处理识别文字和插图、公式等,所以需要使用hocr的这个技术,具体就是使用tessertact识别后,会生成一个hocr格式的xml文件,然后我们使用requests和BueatifulSoup库可以方便的解析这个xml文件,这个hocr文件的内容如下:
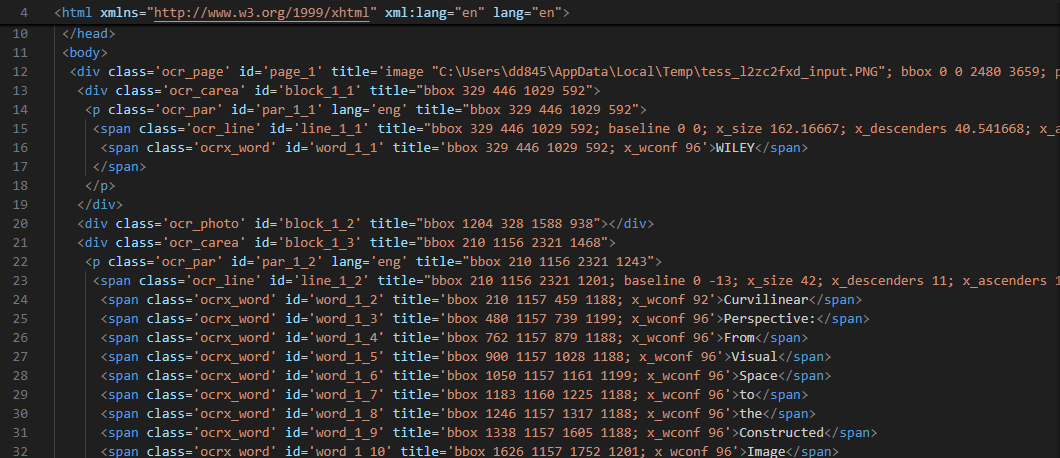
可以看到里面包含了识别文本内容的坐标,这让我们可以很方便的通过这些坐标,组合出我们自己的pdf,我给每页pdf都生成了一个hocr文件(如page1.hocr),和一个识别出并格式化后的文本pdf文档(如page1.pdf).生成的pdf文字版刚开始会有一点小问题,比如文字大小不一,同行的文字高高低低,我们现在有AI,甚至还有AI Agent,这些都是小问题,真正麻烦的公式识别,我开始想到的方法是,使用python的正则匹配公式,基本思路如下:
比如有一个公式:X+Y=10 (1),我直接匹配"="加上"()",这样能把论文中的主要公式匹配出来,我们需要匹配的内容就是刚刚说的hocr文件中span标签里的文本内容,然后通过匹配到的span标签中的title属性,我们可以得到公式的坐标,当然这不是整行公式,所以我们需要合并整行公式。得到坐标后,我们通过之前导出的每页pdf图片(这个步骤可以去除掉原始pdf中的乱码文本等问题,获得的图片名称如:page_001.png),我们使用了dpi=300的分辨率来转换整行公式坐标,并定位到page_00x.png中的相应公式位置,并截取公式小图,最后把公式小图插入到之前格式化文本的pdf文档中去。
使用上面的方法,我做出了粗略版本的ocr识别文档,可以复制文本,虽然识别了部分公式,但是论文中有时会出现一些公式变量,这些东西通过正则识别并不是很好,显然需要更先进的技术,搜索了下资源占用较少,运行速度较快的,能使用cpu运行的AI识别公式模型,正好找到一个合适的,就是pix2text,这个免费开源库完美符合了我的所有要求,能比较好的识别公式,运行速度也很快,是一个小型模型,但是它也有缺点,就是它只能一行行的识别,如果论文有分列的话,会把同行的旁边段落内容也一起识别了,但是这是小问题,知道原因后,只要把先通过pix2text识别出公式或公式变量的坐标范围(pix2text也可以导出类似hocr这样的坐标集合),然后把每个hocr中的单词都与公式坐标比较是否重叠,这样就能很快识别出公式坐标,然后和以前粗略版的方法一样,到图片中截取公式就行,如下就是截取的公式和公式变量的小图效果:

如上的这种方法,能很好的还原出公式原始显示,但是如果你要像word公式这样的能编辑的效果,显然需要很多的适配代码,就是把LaTeX公式代码转换成word公式,理论上有做出的可能性,但是对于我这种小成本的项目,显然需要的开发时间更长,大家如果想把这个项目变成商用的,可以自己实现看看,当然如果只是需要快速使用的话,也有其他的选择,比如mathpix这样的商用软件,我在这里简单介绍下吧!当然我不是打广告,只是觉得有些东西,个人开发和商业开发的效果还是有区别的。mathpix的主页在这里:https://mathpix.com/,可以看到主页下,有很多大厂使用它的技术,比如谷歌、腾讯:

它有多端软件,包括手机端,安卓、IOS、鸿蒙系统都能使用,如下图:

收费有月费或年费,如下:
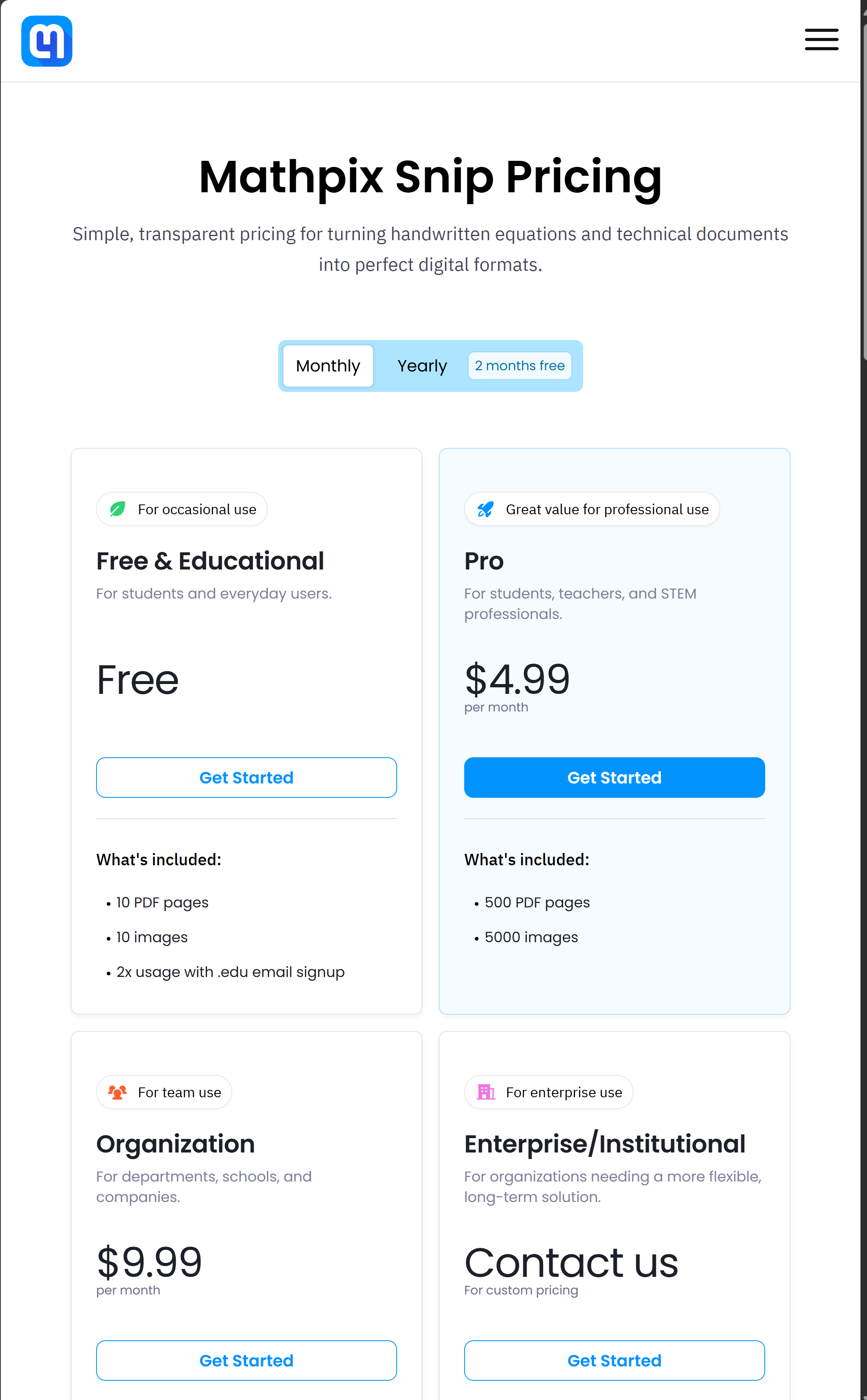
我个人感到它的api更划算一点,需要一次性充值19.99美元开通它的api平台,然后它会返29美金充值到你的api账户,最后它支持支付宝付款。
它可以python调用api,具体使用方法和效果请看:https://mathpix.com/docs/convert/examples
它的sdk如下:https://github.com/Mathpix/mpxpy
我在这介绍mathpix并不是让大家一定去使用它,让人感觉我是打广告,我觉得符合自己需求的才是最好的,不然我不推自己的项目,推它干嘛,那不是吃饱饭没事干-_-!我的本意只是让大家知道除了我这个便宜的项目还有更好的收费商业选择,这也符合我的题目。
简单介绍了我的项目原理后,我要说说一些使用的技巧。
我的程序目录说明如下:
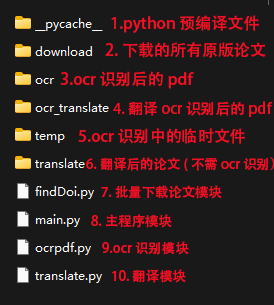
拿到我的程序后,请解压,建议把程序文件夹名称改成"完成版",然后在外面套一层文件夹,名称为"37.自动论文翻译",当然你也可以在main.py的行首,修改main_path(代码第6行),改成你自己的,把你需要下载翻译的论文名,构造成titles数组(第8行开始)传入。
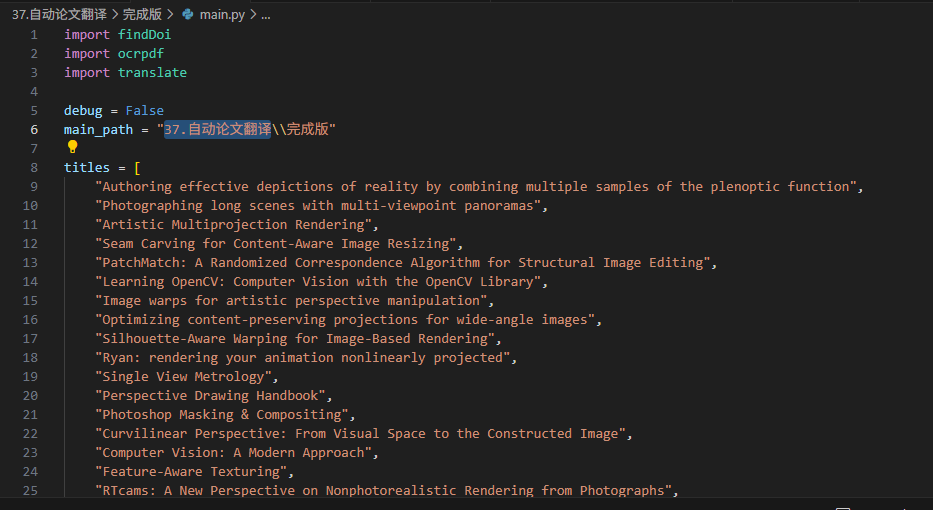
除了之前说的pdf2zh和tesseract外,还需一次性安装如下库:
# 国外或代理
pip install requests beautifulsoup4 selenium webdriver-manager opencv-python pymupdf numpy pytesseract PyPDF2 pix2text pillow reportlab pdf2zh
# 国内源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests beautifulsoup4 selenium webdriver-manager opencv-python pymupdf numpy pytesseract PyPDF2 pix2text pillow reportlab pdf2zh
以上两条命令,请根据你的实际网络情况安装,另请注意python版本请大于等于pythonv3.10,小于等于pythonv3.12。
除了直接main.py来完整运行程序外,我们也可以分开运行其他三个模块代码,这样能单独运行某个功能,比如:
1.findDoi.py可以批量下载论文,但是请设置此模块文件的第16-17行的如下代码:
project_path = "37.自动论文翻译\\完成版\\"# 此模块所在目录
delay = 3# 下载论文时的延迟3秒,可任意修改0-n秒,建议加点延迟,给这些免费网站一点活路还有请设置第124-190行的注释代码,如下:
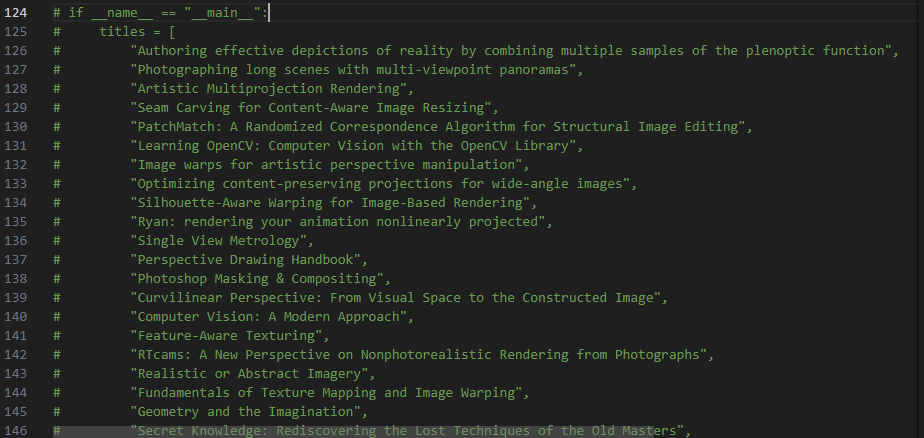
把注释取消后,可以用deepseek等AI,构造一个titles数组,把如图这样的你需要下载的论文名称传入。
2.translate.py是单独的翻译模块,也可以单独运行,但是需要确保上面的download文件夹有相应的pdf论文,如需单独运行,请修改如下:
a.第8行公共变量:
translate_folder = "37.自动论文翻译\\完成版\\"和之前一样,为此模块的目录位置,通俗讲,就是translate.py放哪个目录,就设置 translate_folder在哪,比如"37.自动论文翻译\\完成版\\translate.py",那么就设置translate_folder = "37.自动论文翻译\\完成版\\"
b.第182-184行或第187-189行取消注释:
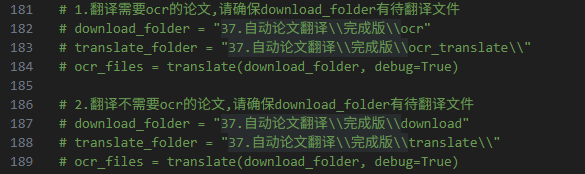
第182-184行是翻译ocr过的论文,ocr文件需放在download_folder变量的目录下;
第187-189行是翻译普通论文(不需ocr,有可复制文字层),同样原始pdf需放在download_folder变量的目录下。
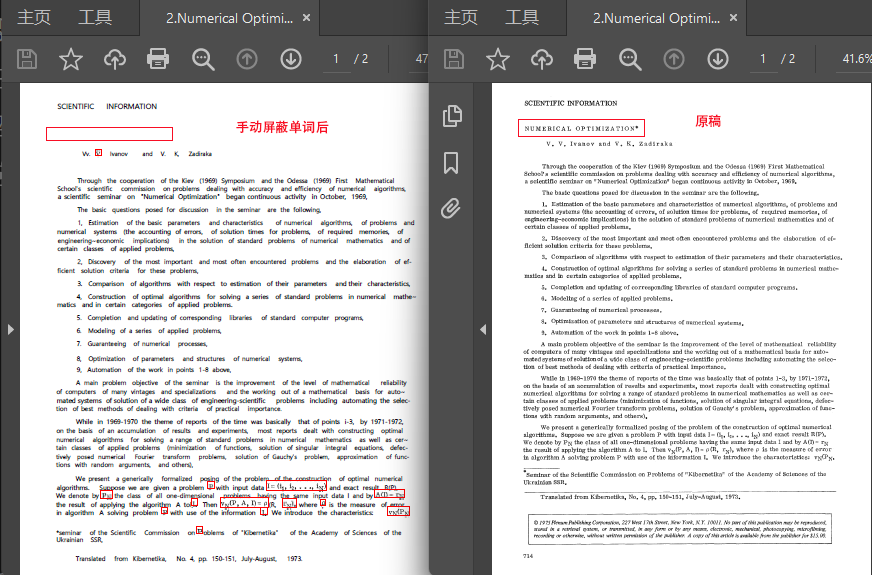
3.ocrpdf.py是单独的ocr模块,也是最复杂的模块,除了上面介绍过的ocr文字、pix2text识别公式,还有自动识别插图、手动屏蔽单个单词替换为原始pdf图像区域功能、手动调整公式在生成pdf的位置偏移。

其他的变量都很简单,我已经注释,解释下手动屏蔽单个单词的功能,如需此功能,需先把debug=True,然后先运行一遍程序,然后可以看到调试信息中,每页识别有如下这样的信息:

请打开上面程序输出信息中显示的每页调试图片,如这个调试图片(37.自动论文翻译\完成版\temp\2.Numerical Optimization\output_pages\debug_blocks_001.png):

可以看到如上图的debug_blocks_001.png,可以看到每个单词都有一个蓝色框,表示识别到的单词坐标范围,每个蓝框左上角,都有如上描述中说的1.1.3这样的标签号,它对应了hocr文件中的标签如下:
<span class='ocrx_word' id='word_1_2' title='bbox 210 1157 459 1188; x_wconf 92'>Curvilinear</span>如上的标签中id="word_1_2",如果我们要屏蔽显示这个单词,只要先确认这是第几页,比如第一页,就在前加1,输出就是1.1.2,上面的debug_blocks_001.png图片中,我们实际举个例子,比如我们要屏蔽1.1.3和1.1.4,也就是NUMBERICAL和OPTIMAIZATION*这两个单词,我们只要把第19-20行改成这样:
blocked_ids = ['1.1.3', '1.1.4']# 构造并添加这行,隐藏1.1.3和1.1.4对应的单词
# blocked_ids = [...]# 注释掉这行,原始的默认配置--不屏蔽,显示所有单词然后第758-762行取消注释: 
请把其中的pdf_path改成你需要ocr识别的论文目录,同时把main_project_path页设置下。
修改后保存代码,并重新运行ocrpdf.py模块即可。注意如果需屏蔽单个文档,那么请单独使用ocrpdf.py这个模块设置blocked_ids,如需重新批量使用,请把blocked_ids设置回默认值。看如下效果:
顺便一提,我的ocrpdf.py可以识别并显示竖排文字,这里我就不发图片了。
最后需要提醒各位,如果需要使用main.py,请把其他三个模块最后的if __name__ == "__main__":里的代码都注释掉,不然会导致main.py不能正常运行,而是执行各个模块的中的这些未注释代码。
我的项目下载链接如下,请大家按需下载,注意:如果你没有代理环境,请不要下载:
大家如果有什么问题或意见,也可以私信或评论区联系我,需要说明的是,scihub这个网站一直在更新中,本人不能保证一直能有效下载论文,所以这也是我开源这部分代码的原因,请大家理解!谢谢大家的观看,再见!




















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











