



关注我的优快云和小红书的各位粉丝,应该都知道前段时间我写的小说爬虫:
Python爬虫系列-爬取小说(解决遇到cookie验证爬取不了的问题) https://blog.youkuaiyun.com/donglxd/article/details/138853222
https://blog.youkuaiyun.com/donglxd/article/details/138853222
上次因为的cookie验证的问题,所以使用了Selenium编写,大家都知道Selenium的效率其实是没有Requests+BeautifulSoup高的,因此,每次编写爬虫我都会先编写Requests看看能不能获取到网页内容,再决定是否使用Selenium,建议大家在编写爬虫时,尽量挑选一些Request可以直接访问的简单网页爬取,当然了Request也是支持Cookie的,以后我可能会出一期爬虫系列博文说一说。
因为上次的爬虫网站,最近更新不太正常,很多新章节都没有内容,所以乘着最近有空,网上搜索了个新小说网,花了半小时更新了代码,网站可能也有一定的反爬虫或是服务器卡顿,有时爬虫会中断,所以加了3秒延时,昨天测试了几次,偶尔会奔溃一下下,其他几次都正常,这种免费网站就是这样的(这个网站算全网同步更新最快的了),效果如下: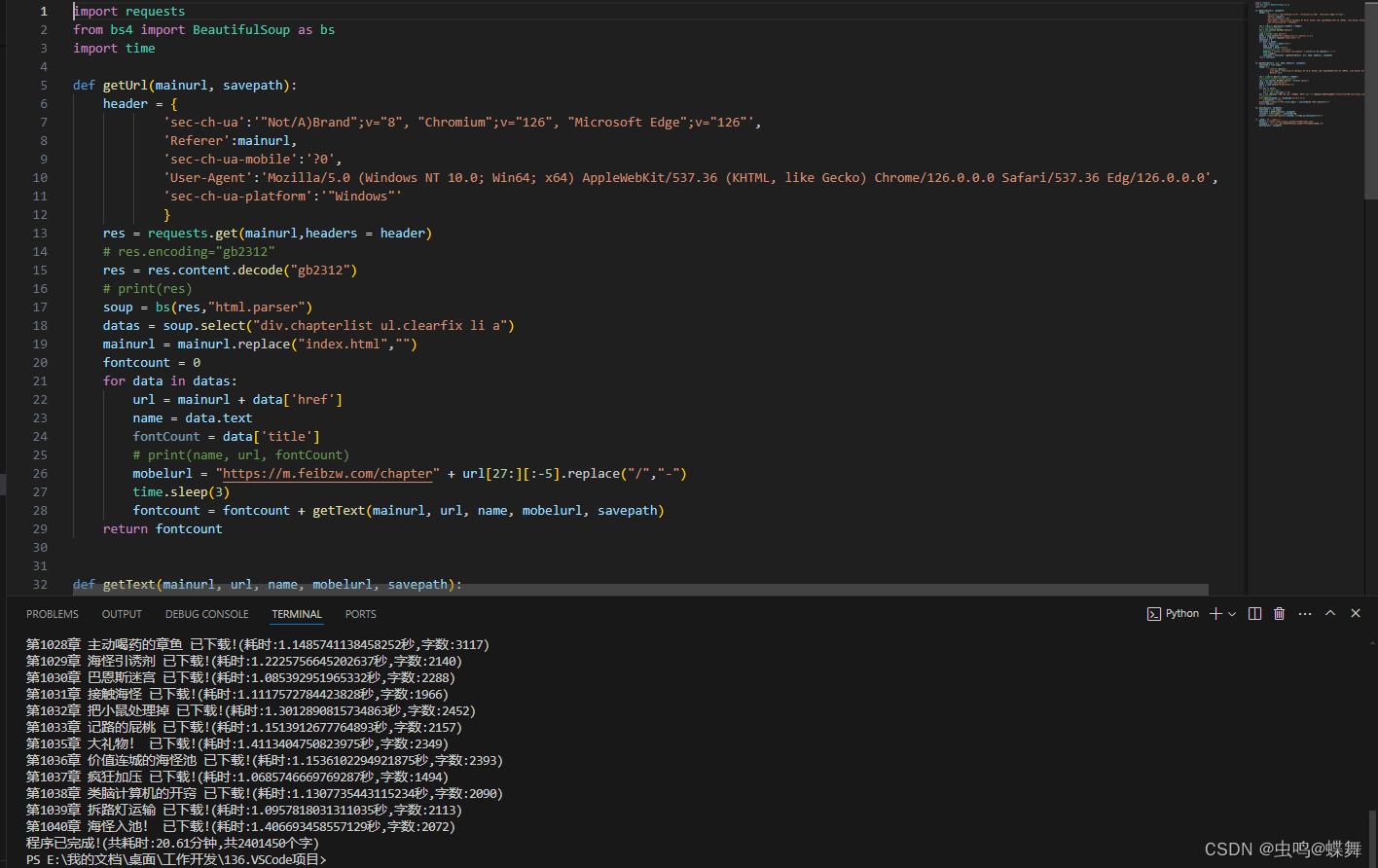
1000多章,爬了15-20分钟左右,这个网站源代码很简单,使用edge或chrome浏览器的F12开发者模式,点击页面元素,就可以查看源码位置,并找到元素标号,可以看到源代码中,小说的内容都是被<p>小说内容</p> 标记着,所以只要用BeautifulSoup提取出来就行了,如下图: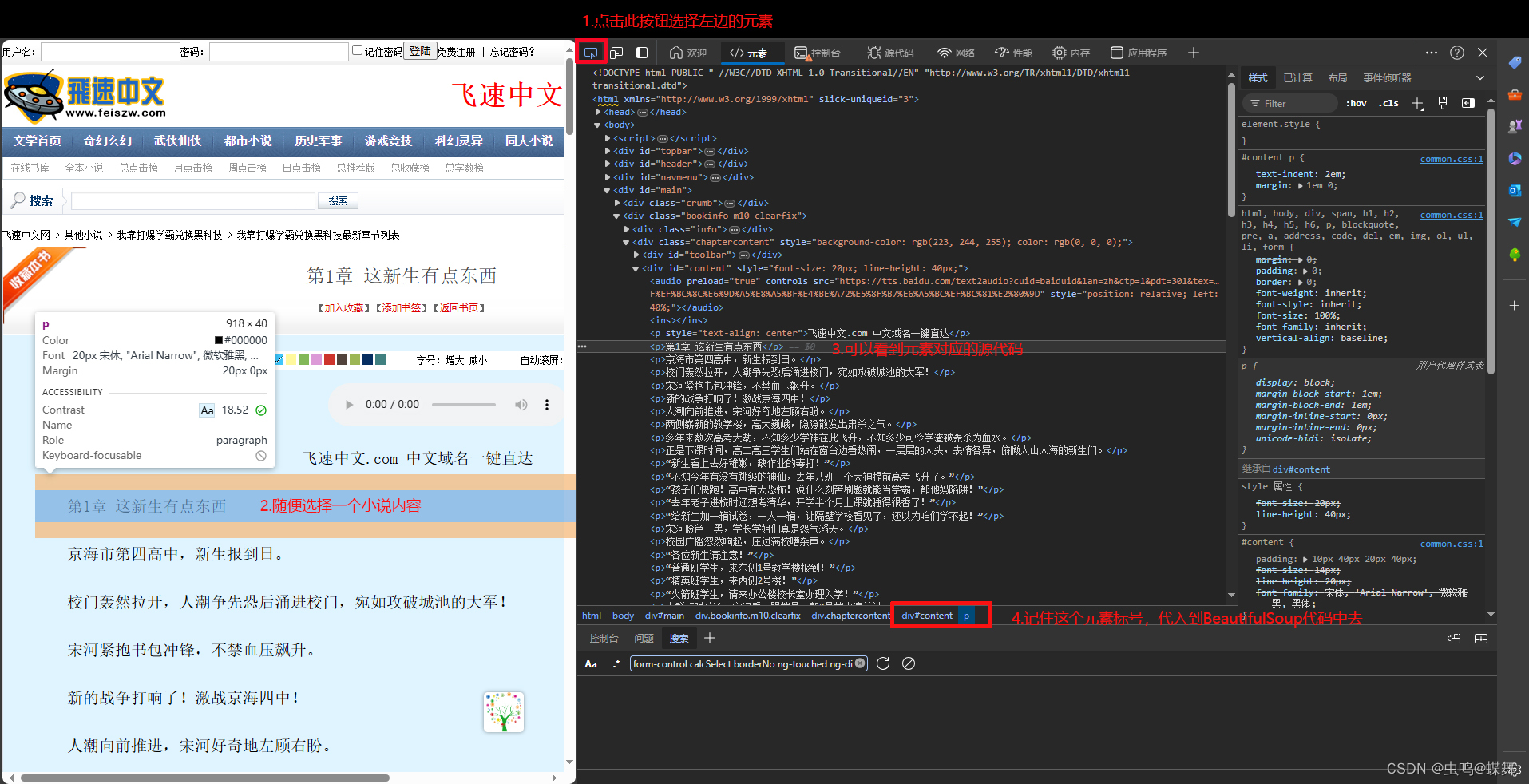
有些初学爬虫的小伙伴,不理解为什么,在调用BeautifulSoup之前还需要requests.get传入网页链接,其实爬虫就是模拟了我们浏览器正常加载网页的步骤,先通过requests.get或requests.post把浏览网页的请求发包给网页服务器,接着,服务器经过与你的客户端握手协议后,把网页内容发送给你,requests在这里就是发送请求包的作用,同时根据服务器的要求,还需要爬虫模拟header请求头、模拟cookie等操作,然后和链接一起发给服务器,等待返回网页内容。在request得到网页内容后,网页内容可能是压缩的,没有解码的,我们需要根据网页源代码里的head元素,判断里面的charset编码方式方便我们解码,使用如下语句:
#网页源代码中的head头,可以看到charset的值是gb2312
# <meta http-equiv="Content-Type" content="text/html; charset=gb2312">
#所以我们使用如下代码通过request发包
#构建请求头
header = {
'sec-ch-ua':'"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'Referer':mainurl,
'sec-ch-ua-mobile':'?0',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
'sec-ch-ua-platform':'"Windows"'
}
#使用request.get方式发送网页链接和上面的请求头
res = requests.get(mainurl,headers = header)
#把返回的网页内容res.content通过decode解码成第一行说明中的charset参数gb2312
res = res.content.decode("gb2312")然后通过BeautifulSoup代入之前查找到的<p>元素即可,需要注意的是<p>有很多行,所以最好把外层的div#content也传入进来,所以有下面的代码:
#刚刚的网页解码成gb2312,并使用errors='ignore'排除一些多余的容易引起错误的解析
res = res.content.decode("gb2312", errors='ignore')
#把上面解码后的res代入BeautifulSoup解析,并设置解析方式为html方法(html.parser)
soup = bs(res,"html.parser")
#把刚刚得到的元素标识符代入BeautifulSoup,让bs来选择所有符合条件的<p>
texts = soup.select("div#content p")最后得到的texts就是所有行的小说内容,只要用一个for循环把它们串联起来就能保存到txt文档中去了。同样的小说主页的爬取也是一样的道理,点找到每一章的元素标号,然后一步步requests.get和BeautifulSoup解析内容,获得章节名和链接。
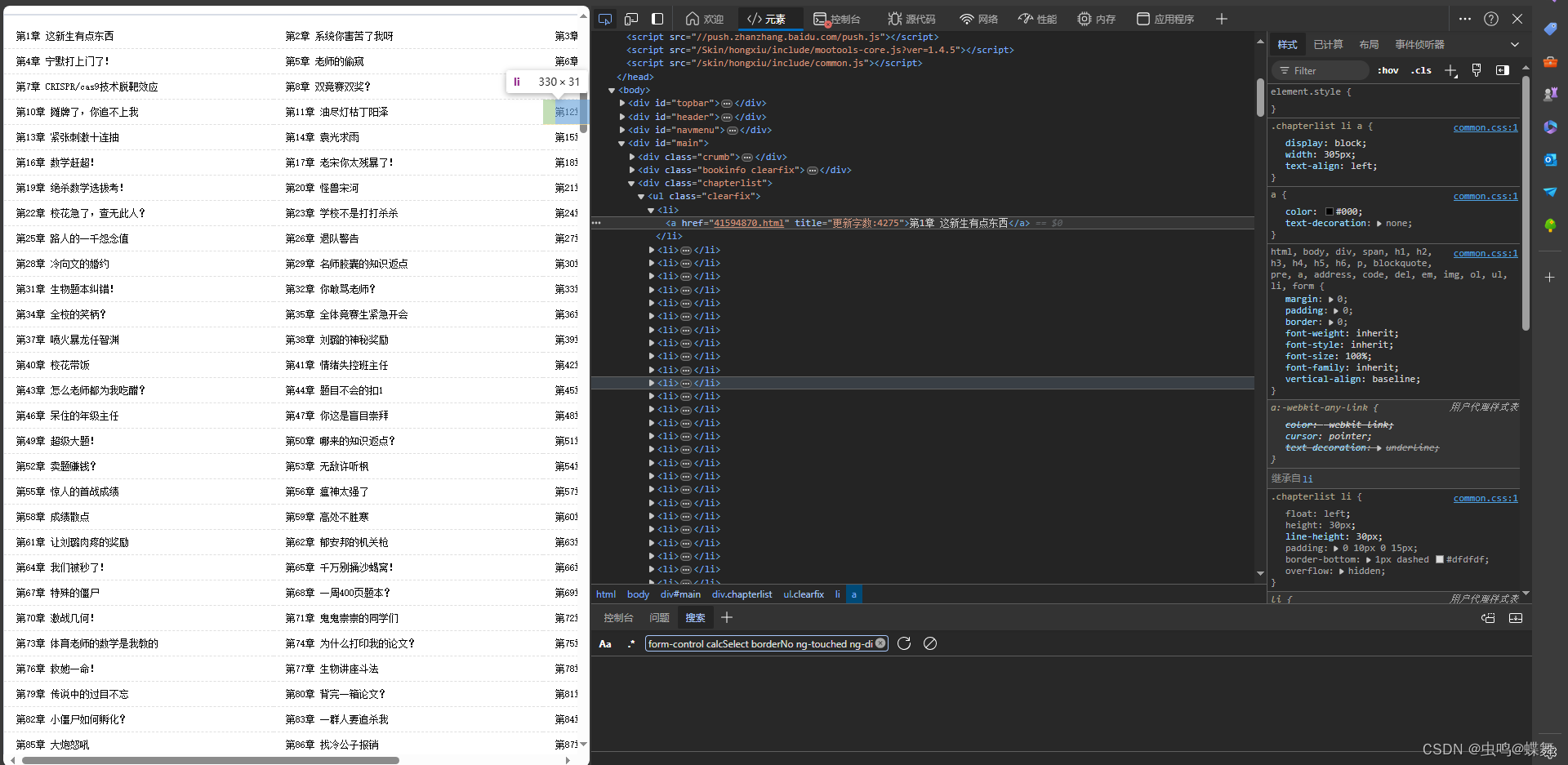 最后把上面的获得单章小说的代码写成一个函数(如下函数getText),放入小说主页的链接循环中(如下函数getUrl),不停调用,就能一章章获取小说。
最后把上面的获得单章小说的代码写成一个函数(如下函数getText),放入小说主页的链接循环中(如下函数getUrl),不停调用,就能一章章获取小说。
所有代码如下:
import requests
from bs4 import BeautifulSoup as bs
import time
def getUrl(mainurl, savepath):
header = {
'sec-ch-ua':'"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'Referer':mainurl,
'sec-ch-ua-mobile':'?0',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
'sec-ch-ua-platform':'"Windows"'
}
res = requests.get(mainurl,headers = header)
res = res.content.decode("gb2312")
soup = bs(res,"html.parser")
datas = soup.select("div.chapterlist ul.clearfix li a")
mainurl = mainurl.replace("index.html","")
fontcount = 0
for data in datas:
url = mainurl + data['href']
name = data.text
fontCount = data['title']
# print(name, url, fontCount)
mobelurl = "https://m.feibzw.com/chapter" + url[27:][:-5].replace("/","-")
time.sleep(3)
fontcount = fontcount + getText(mainurl, url, name, mobelurl, savepath)
return fontcount
def getText(mainurl, url, name, mobelurl, savepath):
starttime = time.time()
header = {
'referer':mainurl,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
'Referer':url
}
res = requests.get(url,headers = header)
res = res.content.decode("gb2312", errors='ignore')
soup = bs(res,"html.parser")
texts = soup.select("div#content p")
str = ""
for txt in texts:
str = str + txt.text + "\n"
str = str.replace("飞速中文.com 中文域名一键直达\n","").replace("最快更新无错小说阅读,请访问 www.feibzw.com\n","").replace("手机请访问:" + mobelurl + "\n","")
with open(savepath,'a+',encoding="utf-8") as f:
f.write(str + "\n")
print(name,f"已下载!(耗时:{time.time() - starttime}秒,字数:{len(str)})")
return len(str)
def main(mainurl, savepath):
starttime = time.time()
fontcount = getUrl(mainurl, savepath)
runtime = (time.time() - starttime)/60
print(f"程序已完成!(共耗时:{runtime:.2f}分钟,共{fontcount}个字)")
if __name__ == "__main__":
mainurl = "https://www.feibzw.com/Html/51366/index.html"
savepath = "11.小说爬取\\20240701更新\\我靠打爆学霸兑换黑科技.txt"
main(mainurl, savepath)
谢谢大家关注,有问题请随时联系我,我看到会回复!




















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











