



 本文详细探讨了HTTP协议中GET和POST方法的区别,包括它们在实际应用中的限制、安全性考量及HTTP规范下的行为差异。同时,分析了GET与POST在速度、缓存和管道化传输方面的表现。
本文详细探讨了HTTP协议中GET和POST方法的区别,包括它们在实际应用中的限制、安全性考量及HTTP规范下的行为差异。同时,分析了GET与POST在速度、缓存和管道化传输方面的表现。
(一)、不完全正确的网红答案
-
GET的URL会有长度上的限制,则POST的数据则能非常大。
-
POST比GET安全,ET请求的数据会附在URL之后,POST把提交的数据则放置在是HTTP包的包体中。
(二)、为什么是不完全正确的答案
-
HTTP协议对GET和POST都没有对长度的限制:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。
而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其余浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系 统的支持。因而对于GET提交时,传输数据就会受到URL长度的 限制。
POST:因为不是通过URL传值,理论上数据不受 限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
-
安全性意义不同:通过GET提交数据,使用户名和密码将明文出现在URL上,由于登录页面有可可以被浏览器缓存,其余人查看浏览器的历史纪录,那么别人即可以拿到你的账号和密码了。post一般来说都不会被缓存,但有很多抓包工具也是能窥探到你的数据,真的要安全那就要把传输的信息加密。但这不是HTTP协议对get和post做的的安全性区别,是浏览器用的具体体现出来的。get在HTPP协议中使用于获取数据,post在在HTTP协议中使用于修改数据。
(三)、在HTTP中get和post的原理区别
Http定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE
URL全称是资源形容符,我们能这样认为:一个URL地址,它使用于形容一个网络上的资源,而HTTP中的GET,POST,PUT,DELETE就对应着对这个资源的查 ,改 ,增 ,删 4个操作。到这里,大家应该有个大概的理解了,GET一般使用于获取/查询资源信息,而POST一般使用于升级资源信息
根据HTTP规范,GET使用于信息获取,而且应该是安全的和幂等的。
-
所谓安全的意味着该操作使用于获取信息而非修改信息。换句话说,GET请求一般不应产生反作用。就是说,它仅仅是获取资源信息,就像数据库查询一样,不会修改,添加数据,不会影响资源的状态。
注意:这里安全的含义仅仅是指是非修改信息。 -
幂等的意味着对同一URL的多个请求应该返回同样的结果。幂等(idempotent、idempotence)是一个数学或者计算机学概念,常见于笼统代数中。
幂等有以下几种定义:
对于单目运算,假如一个运算对于在范围内的所有的一个数屡次进行该运算所得的结果和进行一次该运算所得的结果是一样的,那么我们就称该运算是幂等的。 比方绝对值运算就是一个例子,在实数集中,有abs(a) = abs(abs(a)) 。
对于双目运算,则要求当参加运算的两个值是等值的情况下,假如满足运算结果与参加运算的两个值相等,则称该运算幂等,如求两个数的最大值的函数,有在实数集中幂等,即max(x,x) = x 。看完上述解释后,应该能了解GET幂等的含义了。
-
但在实际应使用中,以上2条规定并没有这么严格。引使用别人文章的例子:比方,新闻站点的头版不断升级。尽管第二次请求会返回不同的一批新闻,该操作依然被认为是安全的和幂等的,由于它总是返回当前的新闻。从根本上说,假如目标是当使用户打开一个链接时,他能确信从自身的角度来看没有改变资源就可。
-
根据HTTP规范,POST表示可可以修改变服务器上的资源的请求。继续引使用上面的例子:还是新闻以网站为例,读者对新闻发表自己的评论应该通过POST实现,由于在评论提交后站点的资源已经不同了,或者者说资源被修改了。
上面大概说了一下HTTP规范中,GET和POST的少量原理性的问题。但在实际的做的时候,很多人却没有按照HTTP规范去做,导致这个问题的起因有很多,比方说:
-
很多人贪方便,升级资源时使用了GET,由于使用POST必需要到FORM(表单),这样会麻烦一点。
-
对资源的增,删,改,查操作,其实都能通过GET/POST完成,不需要使用到PUT和DELETE。
-
另外一个是,早期的但是Web MVC框架设计者们并没有有意识地将URL当作笼统的资源来看待和设计。还有一个较为严重的问题是传统的Web MVC框架基本上都只支持GET和POST两种HTTP方法,而不支持PUT和DELETE方法。
(四)、既然post有这么多优点,那我们为什么要用get?
答案就是:由于get比post更快。
(一)、post请求的过程,会先将请求头发送给服务器进行确认,而后才真正发送数据;而get请求的过程,会在连接建立后会将请求头和请求数据一起发送。
post请求的过程
-
浏览器请求tcp连接(第一次握手)
-
服务器答应进行tcp连接(第二次握手)
-
浏览器确认,并发送post请求头(第三次握手,这个报文比较小,所以http会在此时进行第一次数据发送)
-
服务器返回100 continue响应
-
浏览器开始发送数据
-
服务器返回200 ok响应
get请求的过程
-
浏览器请求tcp连接(第一次握手)
-
服务器答应进行tcp连接(第二次握手)
-
浏览器确认,并发送get请求头和数据(第三次握手,这个报文比较小,所以http会在此时进行第一次数据发送)
-
服务器返回200 ok响应
也就是说,目测get的总耗是post的2/3左右
(二)、get会将数据缓存起来,而post不会
-
能做个简短的测试,用ajax采使用get方式请求静态数据(比方html页面,图片)的时候,假如两次传输的数据相同,第二次以后消耗的时间将在10ms以内(chrome测试),而post每次消耗的时间都差不多。经测试,chrome下和firefox下假如检测到get请求的是静态资源,则会缓存,假如是数据,则不缓存,但是IE这个傻X啥都会缓存起来
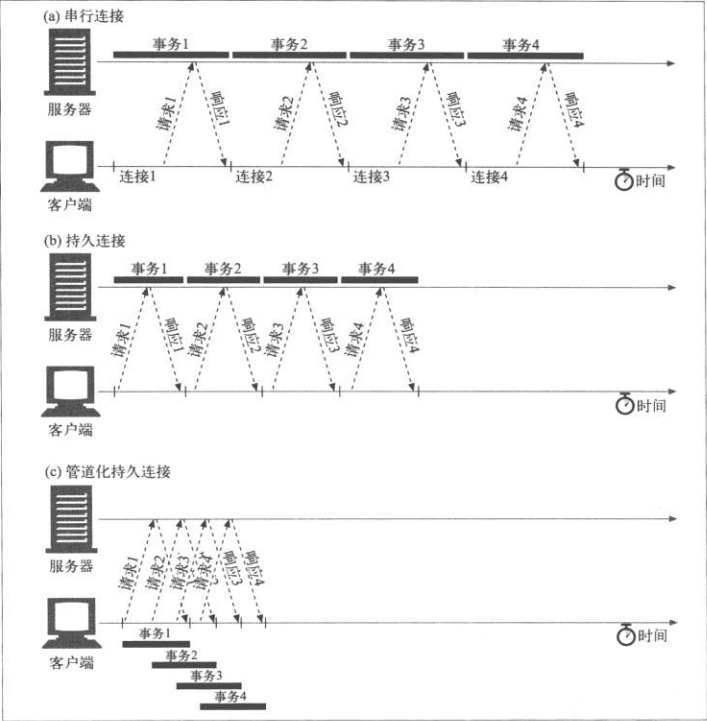
(三)、post不可以进行管道化传输
-
http在的一次会话需要先建立tcp连接而后才可以通信,假如每次连接都只进行一次http会话,那这个连接过程占的比例太大了!
-
于是出现了持久连接:在http/1.0+中是connection首部中增加keep-alive值,在http/1.1中是在connection首部中增加persistent值,当然两者不仅仅是命名上的差别,http/1.1中,持久连接是默认的,除非显示在connection中增加close,否则持久连接不会关闭,而http/1.0+中则刚好相反,除非显示在connection首部中增加keep-alive,否则在接收数据包后连接就断开了。
-
出现了持久连接还不够,在http/1.1中,还有一种称为管道通信的方式进行速度优化:把需要发送到服务器上的所有请求放到输出队列中,在第一个请求发送出去后,不等到收到服务器的应答,第二个请求紧接着就发送出去,但是这样的方式有一个问题:不安全,假如一个管道中有10个连接,在发送出9个后,忽然服务器告诉你,连接关闭了,此时用户端即便收到了前9个请求的回答,也会将这9个请求的内容清空,也就是说,白忙活了……此时,用户端的这9个请求需要重新发送。这对于幂等请求还好(比方get,多发送几次都没关系,每次都是相同的结果),假如是post这样的非幂等请求(比方支付的时候,多发送几次就惨了),一定是行不通的。所以,post请求不可以通过管道的方式进行通信!
管道化传输在浏览器端的实现还需考证,貌似默认情况下大部分浏览器(除了opera)是不进行管道化传输的,除非手动开启!!
所以,在能用get请求通信的时候,不要用post请求,这样使用户体验会更好,当然,假如有安全性要求的话,post会更好。
注:转载https://yiweifen.com/v-1-393644.html

















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









