




1.什么是MapReduce?
MapReduce是一个分布式的计算框架。它由两部分组成Map和Reduce。
2.MapReduce的主要思想
分久必合。
3.MapReduce的核心思想
“相同的key为一组,一组调用一次reduce方法”。
4.MapReduce分布式计算原理
主要流程:
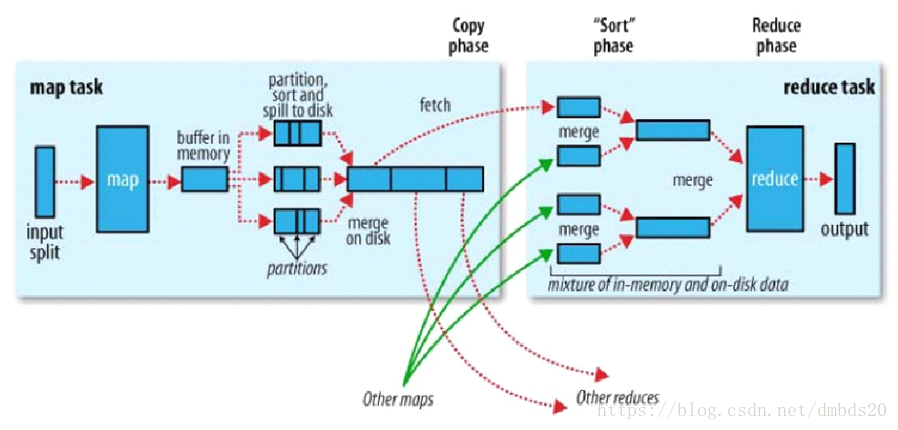
- block中的数据会以<key,value>的形式进入map task,key是偏移量。
- 一个split(切片)大小=block大小。一个split由一个map task处理。但是一条记录可能会存放在两个block中,所以split实际上会比block大几KB或小几KB。也就是说,split只是一个逻辑概念。
- 经过map task处理后的记录的key值会发生改变,变成什么是要根据需求来的。
- map task将处理后的每一条记录打上标签。打标签的目的就是为了知道这一条记录将来会被哪个reduce task处理。打标签也就是分区,分区是由分区器执行的,默认的分区器是HashPartitioner,分区的策略是,根据记录的key的HashCode与reduce task个数取模。
- map task将记录打上标签以后,会将其写入到内存buffer中。进入buffer之后的每一条记录是由三部分组成:分区号,key,value。map task一条一条的往buffer中写,一旦写入到达80M,此时它会将这80M内存封锁,封锁后对内存中的数据进行combiner(小聚合),然后排序。排序的规则是,先按照分区号排序,分区号相同的按照key来排序(就是比较key的ASCII码的大小)。以上的combiner以及排序完成后就开始溢写数据到磁盘上,此时的磁盘文件就是一个根据分区号分好区的,并且内部有序的文件。每进行一次溢写就会产生一个磁盘小文件。
- map task计算完毕后,会将磁盘上的小文件合并成一个大文件,在合并的时候会使用归并排序的算法,将各个小文件合并成一个有序的大文件。(这一步和上面一步统称为shuffle write阶段)。
- 每一个map task都会经历以上的步骤,也就是每一个map task都会产生一个有分区的并且分区内部有序的大文件。
- reduce task去map端读取分区号相同的数据,将分区数据写入到内存中,内存满了就会溢写,溢写之前会进行排序(根据key的ASCII码)。当把所有的数据拉取过来后,会将溢写产生的磁盘小文件合并,并且归并排序成一个有序的大文件。为什么要产生一个有序的大文件,就是为了提高分组的效率。
- 整个过程一共进行了四次排序,这四次排序都是为了提高分组的效率。
- 最后就是把key相同的分为一组,每一组数据调用reduce函数,产生结果。这些结果都放在一个文件中。
- 有几个分区就会产生几个结果文件。不必合并在一起。

















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









