




未完待续
前言
BlueStore是什么?
Ceph是一个统一的分布式存储系统。BlueStore是Ceph的存储引擎。
它的作用是什么?
存储引擎的作用还能是什么?把Ceph上层交给他的数据安稳的存储在磁盘上,需要的时候再读出来或者删除。这就是他的作用。
组成
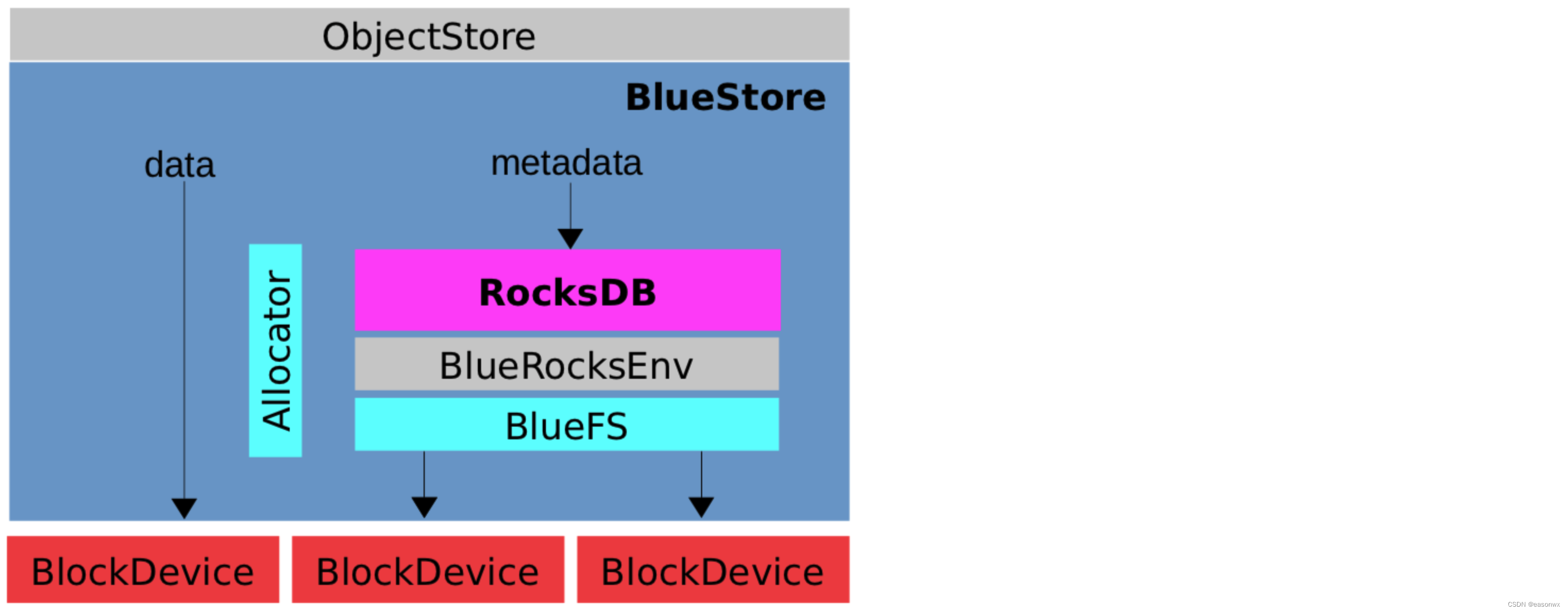
如上图,BlueStore由下面接模块构成:
- RocksDB:为BlueStore提供kv存储。
- BlueFs:RocksDB是一个持久化的kv存储系统,但是Rocksdb本身又不能直接操作磁盘读写数据,在这个情况下,BlueFS就承担了这个职责,作为一个文件系统,为RocksDB提供了磁盘上文件的读写能力。
- BlueRocksEnv:在RocksDB与BlueFS间提供一个桥梁。
- Allocator:磁盘的空间管理器。
- BlockDevice:以HDD或者SSD为代表的裸盘
从上图我们可以看到,对于用户数据本身是由BlueStore直接操作裸盘进行读写,但是对于用户数据的元数据,是通过RocksDB进行读写的。
前期准备工作
在开始研究BlueStore的工作流程前,咱们先了解一下必要的知识。
基础概念
对象
咱们尽量从一个实际的例子进行说明。假定我需要存储《流浪地球2》这个电影,电影本身是20个GB。在Ceph里,会把这个20GB的文件切分成2MB(或者4BM,参数,可配)的一个个文件块,我们把这个文件块就叫做对象。而在BlueStore这一层,是感知不到20GB的《浏览地球2》,它只能感知到2MB的对象块。
Pextent
struct bluestore_pextent_t {
// 磁盘上的物理偏移
uint64_t offset = 0;
// 数据段的长度
uint32_t length = 0;
}
Pextent就是代表真实的物理磁盘上的一个区间。offset就是相对于磁盘上起始位置的偏移量,length的单位就是字节。
extent
struct Extent {
// 对象内逻辑偏移,不需要块对齐。
uint32_t logical_offset = 0;
// 逻辑段长度,不需要块对齐。
uint32_t length = 0;
// 当logical_offset是块对齐时,blob_offset始终为0;
// 不是块对齐时,将逻辑段内的数据通过Blob映射到磁盘物理段会产生物理段内的偏移称为blob_offset。
uint32_t blob_offset = 0;
// 多个物理块
BlobRef blob;
}
对于那个2MB的对象,在BlueStore里,也会对他进行逻辑切分。假定把2MB的对象切分成3块,第一块512KB,第二块512KB,第二块1024KB,那么
第一个Extent的logical_offset 是0,length是512x1024
第二个Extent的logical_offset是1x512x1024,length是512x1024
第三个Extent的logical_offset是2x512x1024,length是1024x1024
上面还有blob_offset 的概念,牵扯到块对其,大家暂时忽略。
Blob
在上面的Extent里面还有一个Blob是什么意思?
就上面那个例子,在真实的物理磁盘上,不一定有一块连续的空闲的1MB的空间。所以BlueStore会把物理上不在一块的磁盘空间逻辑上放到一块。
struct Blob {
// reference count
std::atomic_int nref = {0};
mutable vector<bluestore_pextent_t> blob;
}
一个512KB的Blob,内部可能是磁盘上3个并不相连的空间段拼起来的。
Node
// 内存数据结构
struct Onode {
// reference count
std::atomic_int nref;
// onode 对应的PG
Collection *c;
// onode磁盘数据结构
bluestore_onode_t onode;
// 有序的Extent逻辑空间集合,持久化在RocksDB。lexetnt--->blob
ExtentMap extent_map;
......
}
// 磁盘数据结构 onode: per-object metadata
struct bluestore_onode_t {
// 逻辑ID,单个BlueStore内部唯一。
uint64_t nid = 0;
// 对象大小
uint64_t size = 0;
// 对象扩展属性
map<mempool::bluestore_cache_other::string, bufferptr> attrs;
std::vector<shard_info> extent_map_shards; ///< extent std::map shards (if any)
......
}
上面的Onode 描述一个对象(就是那个2M的对象)的信息。
上面的ExtentMap,大家猜一下也能知道,假定一个对象被分成了3个Extent,那都是哪3个Extent呢,对象本身得知道,自己的数据逻辑上分成了哪几块么。
线程
事务
磁盘的抽象与分配
位图法
BlueStore面对的一块完完全全的裸盘。那么第一个问题就是,BlueStore怎么知道磁盘上那一块用了,哪一块没有用呢。
首先对磁盘进行分块,假定就按照4KB分块。
其实一个思路就是先把磁盘上的块进行编号,然后对于每个块使用一个比特的0代表已经被使用,1代表没有使用。这样以来我只要使用原始硬盘空间的32768分之1的空间就能描述磁盘里每个区域的使用情况了(410248=32768)
那么一个100GB的磁盘,大概只需要32MB的内存比特流就能描述。
以上,就叫做位图法。
分层位图
以上面的例子来说,假如我需要在1块100GB的磁盘上分配一个4KB的块,最最极端情况下,我就得扫描32MB的数据,才能知道哪个块没有被使用。这个是不可接受的。
大家知道跳表么?
还是那个100GB的空间,我假定L0层就是32MB的内存块。
然后L1层有64KB的内存块,L1的一个比特对应L0层的512个比特。
假定L0的前512个比特都是0(代表磁盘上前5124KB的一段区域都已经被分配了)那么我L1上第1个比特就是0。
假定L0的前512个比特不都是0(代表磁盘上5124KB的一段区域还没有被完全分配完)那么我L1上第1个比特就是1。
如果磁盘空间更大了,那么L1上面还可以加一个L2。
这样以来,分配空闲磁盘的时间复杂度就可控了。
上电流程
写流程
这里先说几个概念
BlueStore的写分为两种
1 新写
2 覆盖写
新写很好理解,就是完全新建一个文件,这个文件里每个对象的每个字节数据都是新的,都没有和之前的数据有任何关联。
接着说覆盖写,说白了你可以理解为把一段数据,例如ABCDEF,改写成了ABEF这种。覆盖写也分两种,如下:
1 本地覆盖写(RMW)
2 异地写(COW)
先说本地覆盖写,它也有两个概念,WAL与读惩罚。
先说WAL,本地覆盖写说白了,就是把某个磁盘上的数据完全本地覆盖,那这里就有问题了,如果覆盖的过程中出了问题,那结果老的数据读不了,损坏了,新的数据也读不了,因为还没有完成写。那这不麻烦了?!所以有了WAL,我先把要保存的数据在别的地方先存一下,如果存wal的时候失败了,那就告诉上层逻辑存储失败了,但是别怕,我的老数据还在原来的位置,没有损坏。
第二 读惩罚。即使是写wal,也需要先把原来位置的数据先读到内存,然后与需要写的数据进行合并,再写入。这里面先把数据读出来的逻辑,因为并不是直接和写相关,所以我们把它叫读惩罚。那为什么要先读一下呢?
假定一个对象开头部分的数据是ABCDE,你现在想把第二第三个字符修改成MS,那你是不是得先把ABCDE读到内存,和MS拼接成AMSDE,然后才能写到下层。(你总不能直接把MS写到下层逻辑吧,这样一来ABE跑哪里去了)
本地覆盖写说完了,咱们在说说异地写。
异地写的逻辑说白了就是重新找一个地方,把要更新的数据整个写下去,然后修改内存里文件的指针,把文件内容指向新的地方。(这里就不需要WAL了)
我们很容易看到,本地覆盖写和异地写这两种策略各有优缺点。例如异地写肯定会造成后面的磁盘碎片问题。
在HDD时代,磁盘碎片化,会导致读性能大幅度下降,这个不可接受(HDD下随机读与顺序读的性能相差太大)。
后来进入SSD时代,碎片化的读似乎不那么难以接受了(主要是SSD下,随机读与顺序读的性能相差不是那么大),而且把数据写到新的地方也相当于把随机写改成了顺序写。
这么看来,至少在SSD下COW还不错,但是即使在SSD下,COW还有问题
比如:cow会涉及指定重定向等等,这些都是元数据,元数据太大也会影响系统性能。
所以在覆盖写的情况下,BlueStore是综合运用了两种写策略,即
对象数据中间的部分使用COW模式
对象数据两头使用RMW模式
以上内容大量参考《Ceph设计原理与实现》第二章第一节的内容。
读流程
参考资料
https://zhuanlan.zhihu.com/p/68067068
https://zhuanlan.zhihu.com/p/92397191

















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









