




 本文探讨了一种特殊情况下,Markdown文本中的'##'符号在SQL解析过程中的误识别问题,导致转换为HTML时出现内容缺失。通过对SQL解析器的token匹配机制深入分析,找到了问题根源,并提出了解决方案——修改解析器源码。
本文探讨了一种特殊情况下,Markdown文本中的'##'符号在SQL解析过程中的误识别问题,导致转换为HTML时出现内容缺失。通过对SQL解析器的token匹配机制深入分析,找到了问题根源,并提出了解决方案——修改解析器源码。
这两天在开发一个平台的模块 很简单的需求 把markdown文本转为html 因为公司自有的ODEP平台,工作原理大致都是把SQL解析成任务,不管是批处理任务也好流处理也罢,都是通过sql进行的,既然用到sql 那肯定需要sql解析成对应的语法树才行,那问题就来了,我的sql中包含了“##” 这样一组字符(因为## 代表markdown的二级标题起始符号) 结果发现 这组字符及其后面的东西都没了! what? 我进行了调试 开始以为是引入第三方依赖的问题 更换了其他依赖还是不行 后来发现是sql解析过程中问题~
大致过程如下 前台编写的代码---后台通过 apache.velocity把这串代码解析成sql(比如 先切割成字符串数组 去掉多余空格 换行等 再匹配token常量 比如 语句中有true 就匹配TRUE代表的常量值33 有minus就匹配36 有plus就匹配37.....) -----然后在处理处理生成对应语法树AST 可类比于JavaCC的过程,Java CC的原理大致如下
javaCC 是一个能生成语法和词法分析器的生成程序。语法和词法分析器是字符串处理软件的重要组件。编译器和解释器集成了词法和语法分析器来解释那些含有程序的文件,其中词法和语法分析器被广泛用于各种应用,是用以首先定义用户将要使用的语言,然后用该定义解析相应的条目并且对各种后端数据库制定正确的查询的一种方法。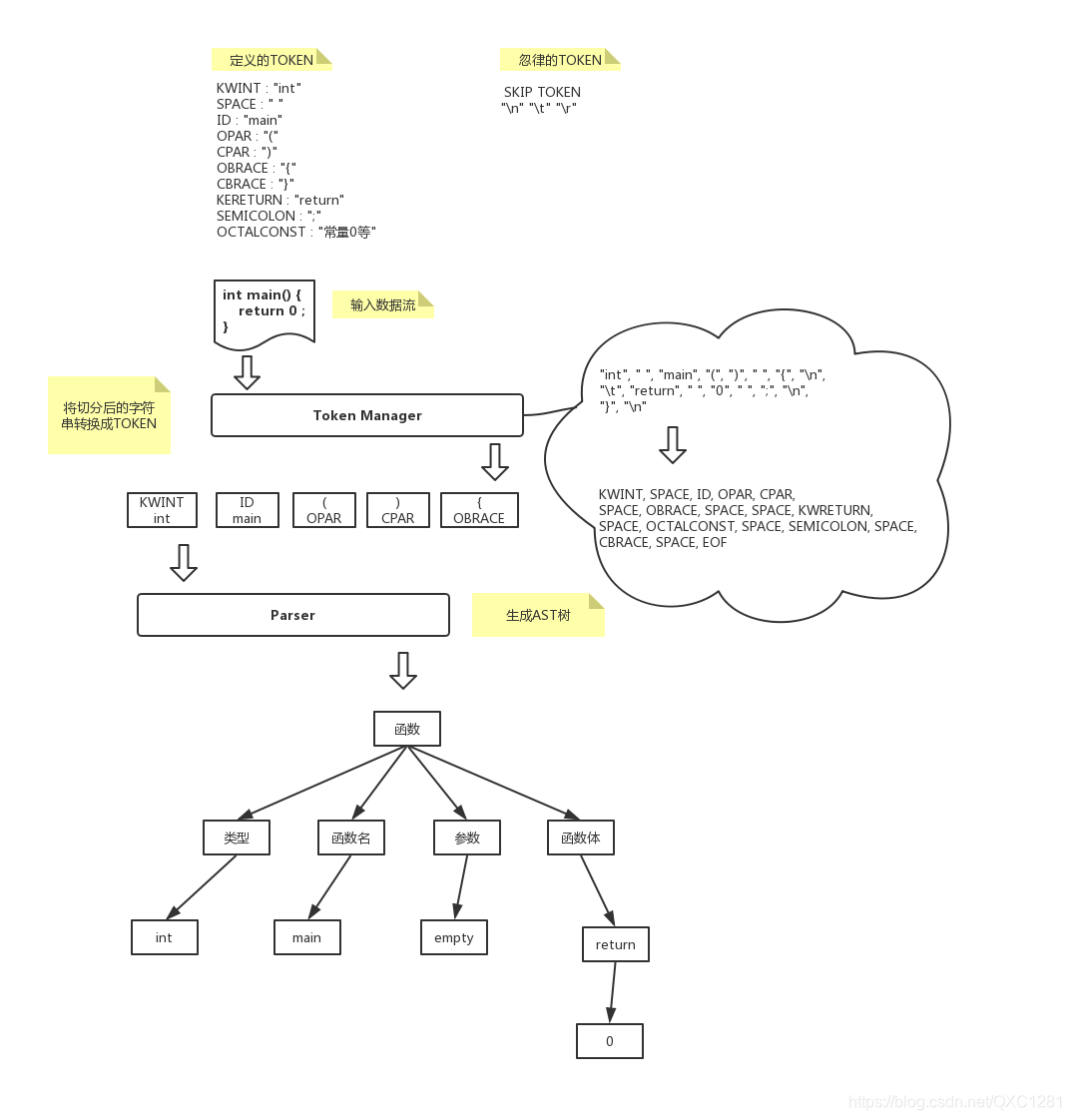
问题就出现在这个token匹配常量中 ## 被示意为单行注释
看图
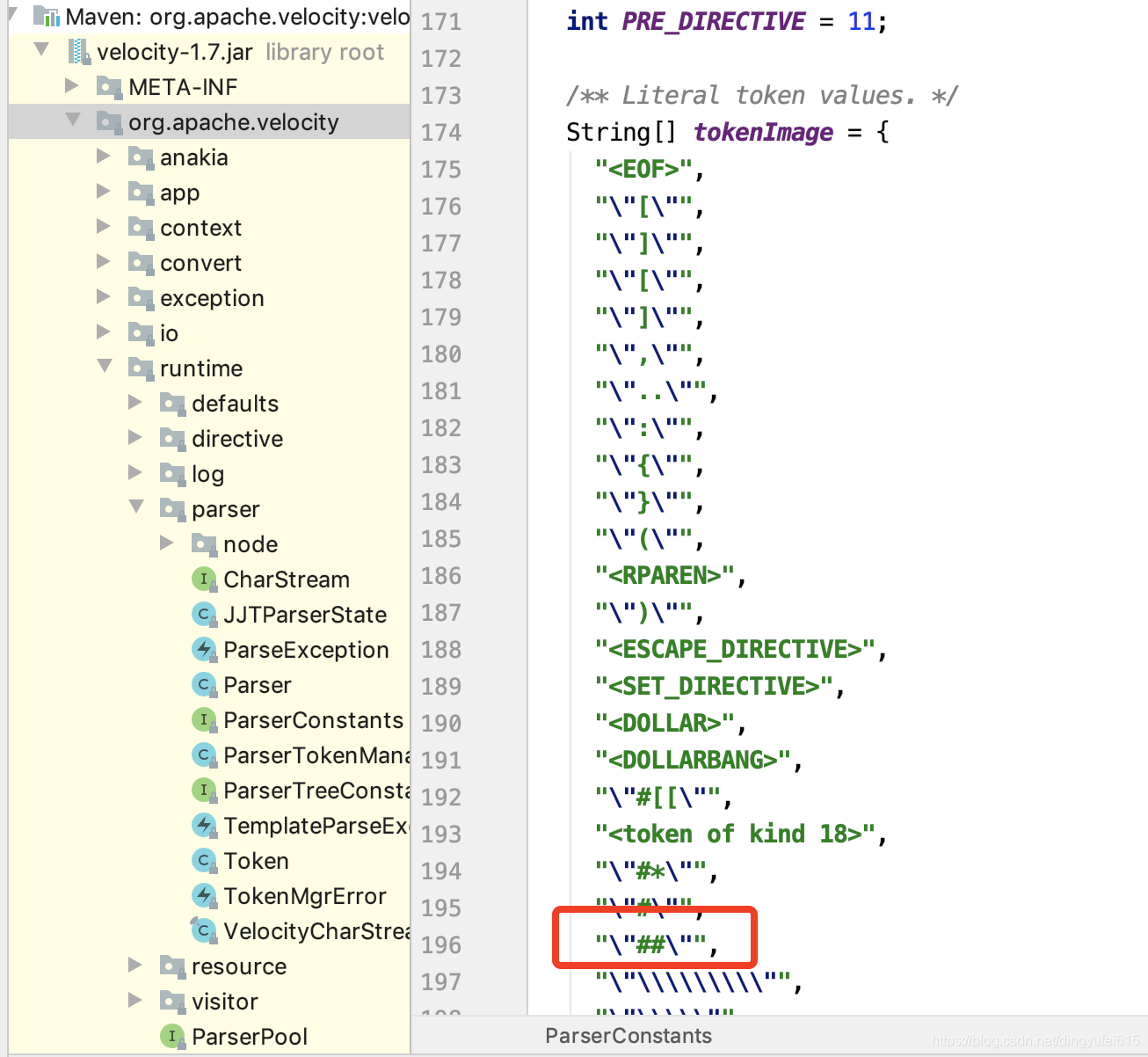
再看看它对应解释:
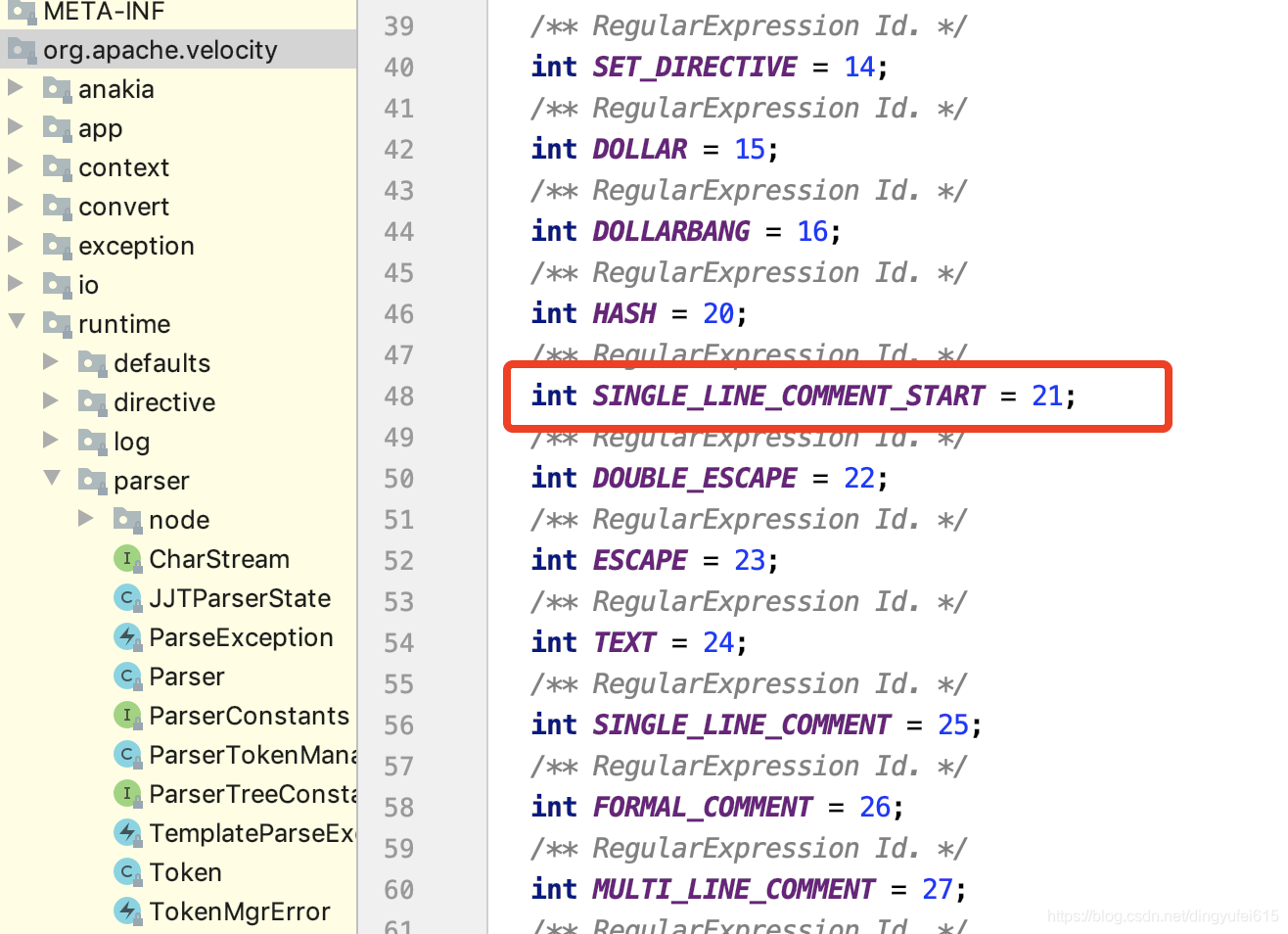
解决办法就是修改这个包的源码 重新打包编译~

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









