



 本文深入对比了HashMap与HashTable的特性,包括线程安全、null值处理、扩容策略及并发访问机制。详细解析了ConcurrentHashMap如何优化并发访问,提供了一种更高效的多线程解决方案。
本文深入对比了HashMap与HashTable的特性,包括线程安全、null值处理、扩容策略及并发访问机制。详细解析了ConcurrentHashMap如何优化并发访问,提供了一种更高效的多线程解决方案。
注:hashtable:使用一把锁处理并发问题,当有多个线程访问时,需要多个线程竞争一把锁,导致阻塞。
concurrentHashMap则使用分段,相当于把一个hashmap分成多个,然后每个部分分配一把锁,这样就可以支持多线程访问。
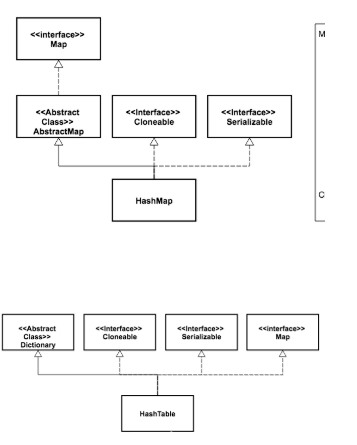
1、HashMap与hashtable继承关系图:
2、hashmap支持:支持null的key和value值,在hashtable源码中有对null的判断,为null,抛出空指针异常。
3、扩容方式不一样
HashTable默认的初始大小为11,之后每次扩充为原来的2n+1。HashMap默认的初始化大小为16,之后每次扩充为原来的2倍。如果在创建时给定了初始化大小,那么HashTable会直接使用你给定的大小,而HashMap会将其扩充为2的幂次方大小。(关于2 的幂次方见第三节)
4、线程安全问题:在hashtable中,对开放接口做了synchronize关键字的同步处理。而hashmap没有,故线程不安全,而concurrentHashmap就是主要解决hashmap的这个问题。
5、hashMap线程不安全所以性能高,hashtable被淘汰可用concurrentHashmap替换

















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









