



💡
课程:3.1 pandas 基本介绍_哔哩哔哩_bilibili
黑马程序员课程笔记https://docs.hwl.cool/python/数据挖掘/pandas.html#dataframe
基本介绍
series
1.Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关 的数据标签(即索引)组成。Series的字符串表现形式为:索引在左边,值在右边。如果没有为数据指定索引,将自动创建一个0到N-1(N为数据的长度)的整数型索引。

3.对于许多应用而言,Series最重要的一个功能是,它会根据运算的索引标签自动对齐数据
4.Series对象本身及其索引都有一个name属性
5.Series的索引可以通过赋值的方式就地修改
import numpy as np
import pandas as pd
s=pd.Series([1,2,'a','b','c'])
sDataFrame

DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字 符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用 同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维 数据结构)。(利用Python进行数据分析p129)
import pandas as pd
dates = pd.date_range('2024-01-01', periods=6)#生成一个从 2024-01-01 开始的连续6个日期
dates
#dates 是前面定义的日期范围,作为 DataFrame 的行索引。
#columns=['a', 'b', 'c', 'd'] 用来设置 DataFrame 的列标签。
df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d'])
dfPython Pandas中dataframe常用操作(创建、读取写入、切片等)-优快云博客 🛠Python Pandas中dataframe常用操作(创建、读取写入、切片等)-优快云博客
df2=pd.DataFrame({'A':1.,#填充浮动值 1.0
'B':pd.Timestamp('20240102'),#一个时间戳(2024-01-02),在所有行中重复
'C':pd.Series(1,index=list(range(4)),dtype='float32'),#一个 pd.Series,每行填充 1.0,数据类型为 float32
'D':np.array([3]*4,dtype='int32'),#一个 NumPy 数组,包含整数 3,在4行中重复
'E':pd.Categorical(['test','train','test','train']),#数据类别列,交替设置为 "test" 和 "train"
'F':'foo'})#一个字符串 "foo",在所有行中重复
df21.pd.Timestamp(data, freq=None, tz=None)
data: 时间戳的输入,可以是字符串、整数、浮点数或 datetime 对象。例如:"2024-01-02"、1672531200(UNIX 时间戳)。
freq: (可选)频率,用于对生成的时间戳加以约束。
tz: (可选)指定时区信息,例如 "UTC" 或 "Asia/Shanghai"
2.pd.Categorical(values, categories=None, ordered=False)
values: 输入的可迭代对象(如列表、数组或 Series),表示类别数据。可以是字符串、整数等类型的标签。
categories: (可选)定义类别的顺序或种类。如果未指定,Pandas 会根据输入数据的唯一值自动生成类别。
ordered: (可选)布尔值,表示类别是否有顺序(默认是 False)。如果设置为 True,则类别会有大小关系。df2.describe()
#用于生成数据框(DataFrame)中各列的描述性统计信息。它默认只对数值型(数值、浮动等)数据进行分析,但可以通过设置参数来扩展到其他类型的列。
#这将返回一个包含以下统计信息的摘要:
count: 非空值的数量。
mean: 均值。
std: 标准差。
min: 最小值。
25%: 第 25 百分位数(Q1)。
50%: 中位数(第 50 百分位数,Q2)。
75%: 第 75 百分位数(Q3)。
max: 最大值。
df2.sort_index(axis=1,ascending=False)
#按列索引进行降序排序df2.sort_values(by='D')
#按D列进行排序,默认情况下,sort_values() 会按升序对该列的值进行排序。数据的取值与选择
#生成一个6x4数组,行索引为日期。列索引为ABCD
dates=pd.date_range('20240101',periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
df#索引A列(两种方式输出结果相同)
df['A']
df.A

df[0:3]#隐式索引
df['20240101':'20240103']#显式索引#基于行和列标签的索引,
data.loc[row_indexer, column_indexer]
#row_indexer: 行的标签或布尔条件,表示要选择哪些行。
#column_indexer: 列的标签或列的条件,表示要选择哪些列。
df.loc[:,['A','B']]#选择所有行和A,B两列#基于行和列的位置索引(即整数位置)选择数据的索引器,
data.iloc[row_indexer, column_indexer]
df.iloc[2,[0,1]]#第三行,第1,2列
df.iloc[0:3,1:3]#1-3行,2-3列
df.iloc[[1,3,5],0:3]#2,4,6行和1-3列 🚫ix[] 是 Pandas 中旧版本的索引器,支持基于标签和位置的选择。自 Pandas 0.20.0 版本以后已被废弃。
df[df.A<8]
#df.A < 8: 这是一个条件表达式,它会对列 A 中的每个元素进行比较,判断它们是否小于 8。返回的是一个布尔型的 Series(每个元素为 True 或 False)。
#df[df.A < 8]: 通过这个布尔型的 Series 来筛选 DataFrame,返回所有符合条件(A 列小于 8)的行。赋值
df.A[df.A < 10]
#这部分代码会先筛选出 A 列中小于 10 的元素,并返回这些元素的副本。
#然后,你试图将这些值直接赋为 10,但这实际上会在原 DataFrame 上进行修改,
#但这种修改方式可能是对副本的操作而不是对原始 DataFrame 进行操作。因此,Pandas 会发出警告。
推荐方法:df.loc[df.A < 10, 'A'] = 10💡
将列表或数组赋值给某个列时,其长度必须跟DataFrame的长度相匹配。如果赋值的是一个 Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值
df.iloc[2,2]=100#第三行第三列改为100
df.loc['20240101','A']=40#20240101行的A列改为40
df.loc[df.A < 10, 'A'] = 10#将A列所有<10的数值改为10
df['F']=np.nan#新增一个F列,全部为nan(缺失值)
df['E']=pd.Series([1,2,3,4,5,6],index=pd.date_range('20240101',periods=6))#新增一个E列
df缺失值
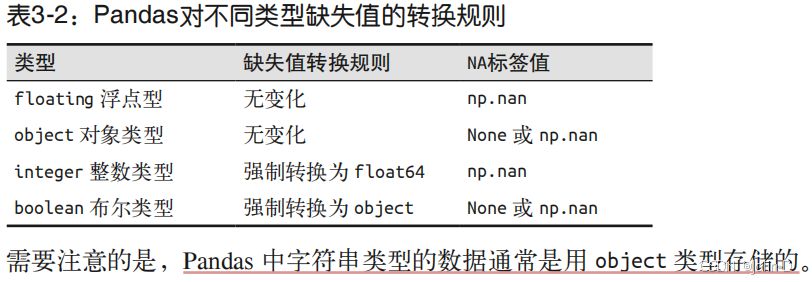
- None:Python对象类型的缺失值 Pandas 可以使用的第一种缺失值标签是 None,它是一个 Python 单体对象,经常在代码中 表示缺失值。由于 None 是一个 Python 对象,所以不能作为任何 NumPy / Pandas 数组类型 的缺失值,只能用于 'object' 数组类型(即由 Python 对象构成的数组)
- NaN:数值类型的缺失值 另一种缺失值的标签是 NaN(全称 Not a Number,不是一个数字),是一种按照 IEEE 浮点 数标准设计、在任何系统中都兼容的特殊浮点数。 请注意,NumPy 会为这个数组选择一个原生浮点类型,这意味着和之前的 object 类型数 组不同,这个数组会被编译成 C 代码从而实现快速操作。你可以把 NaN 看作是一个数据类 病毒——它会将与它接触过的数据同化。无论和 NaN 进行何种操作,最终结果都是 NaN
- Pandas中NaN与None的差异 虽然 NaN 与 None 各有各的用处,但是 Pandas 把它们看成是可以等价交换的,在适当的时 候会将两者进行替换。Pandas 会将没有标签值的数据类型自动转换为 NA。
python数据科学手册p107-p109
处理缺失值
dates=pd.date_range('20240101',periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
df.iloc[0,1]=np.nan
df.iloc[1,2]=np.nan
df
print(df.dropna(axis=0,how='any'))
#只要有一个缺失值就去除整行
print(df.dropna(axis=0,how='all'))
#如果全部是缺失值就去除整行
print(df.fillna(value=0))
#缺失值用“0”填充
print(np.any(df.isnull())==True)
#是否有缺失值(返回一个布尔值)
导入和导出文件
导入
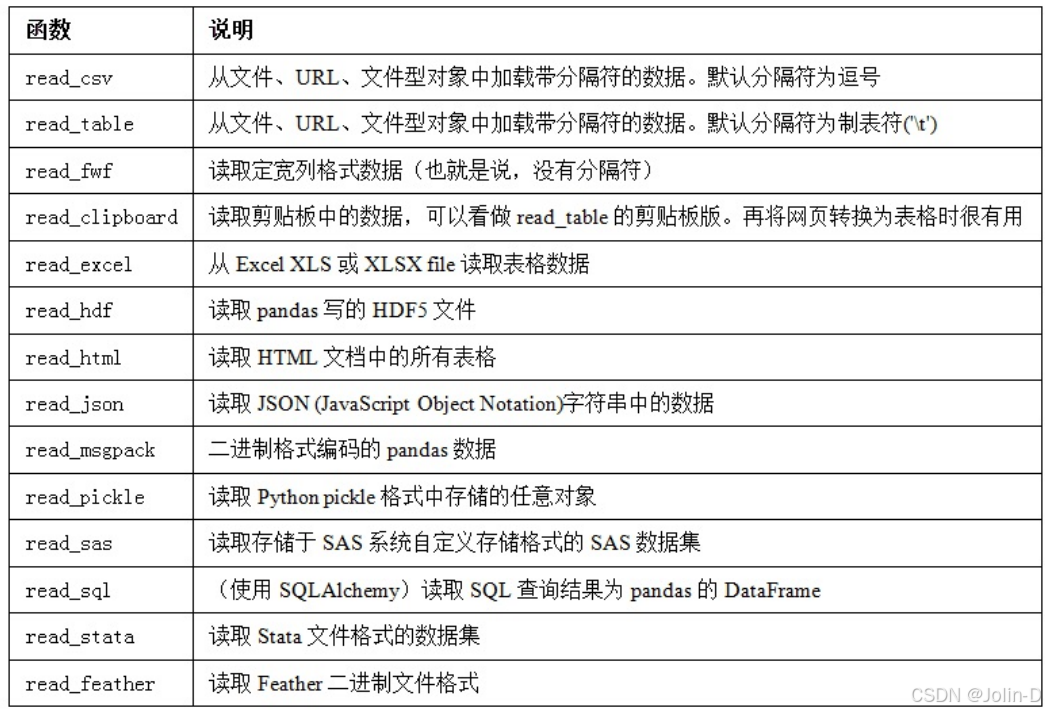
pandas.read_csv,有类型推断功能,因为列数据的类型不属于数据类型。也就是说,你不需要指定列的类型到底是数值、整数、布尔值,还是字符串。
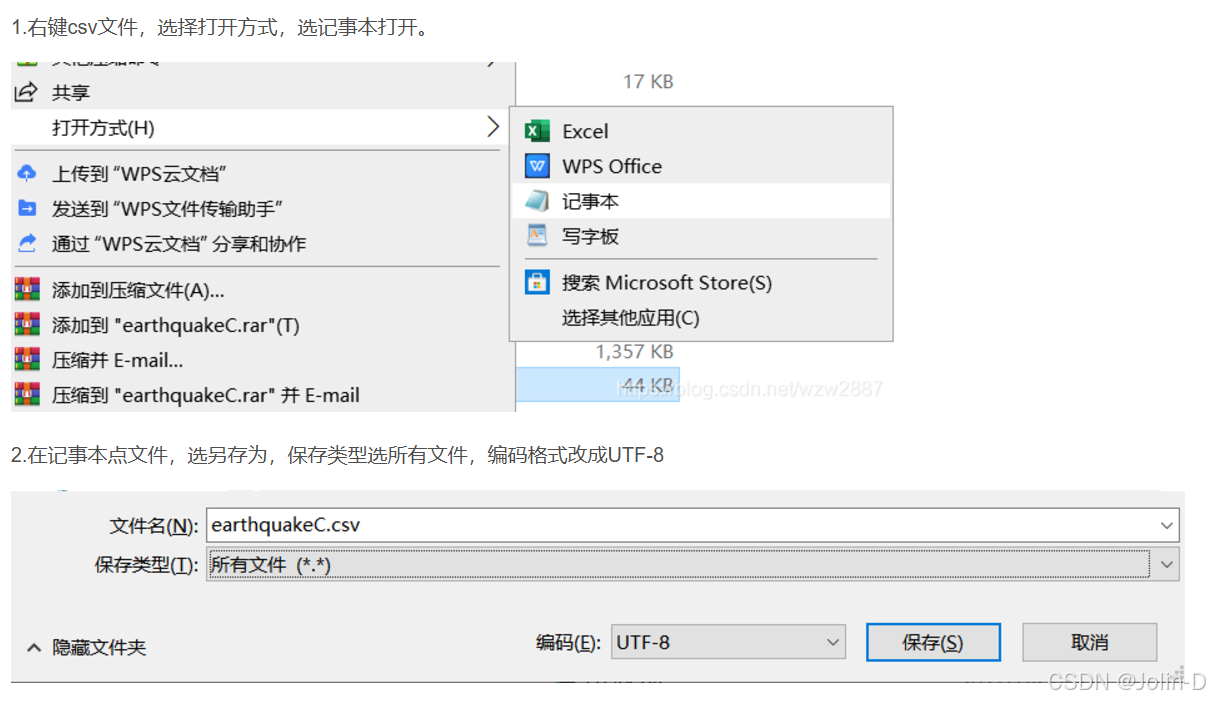
💡文件读取失败:
1.避免在路径中使用特殊字符(如中文字符);保存路径最好不要有中文,可能会导致读取失败。
2.文件或目录权限不足:检查并修改文件权限、以管理员身份运行程序、关闭占用文件的进程。
3.反斜杠(\\)在 Python 字符串中会被当作转义字符使用:
①可以在字符串前加一个 r,使其成为原始字符串pd.read_csv(r’路径’)
②手动将路径中的每个反斜杠替换成双反斜杠(\\\\)
③你还可以直接使用正斜杠(/),它在 Windows 系统中也是有效的路径分隔符 4.修改csv文件编码格式为UTF-8
4.修改csv文件编码格式为UTF-8
如何修改csv文件编码格式为UTF-8?_csv utf-8-优快云博客
data = pd.read_csv(r'D:\workplace\student.csv')
print(data)导出
实现数据的高效二进制格式存储最简单的办法之一是使用Python内置的pickle序列化。pandas对象 都有一个用于将数据以pickle格式保存到磁盘上的to_pickle方法:
data.to_pickle('student.pickle')
合并数据集
Numpy数组的合并
x=[[1,2,],
[3,4]]
y=[[5,6],
[7,8]]
np.concatenate([x,y],axis=1)#将X,Y沿竖轴方向合并Pandas数组的合并
pd.concat实现简易合并
#创建三个DataFrame
df1=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2=pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3=pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
#np.ones((3, 4)):使用 NumPy 创建一个形状为 (3, 4) 的数组,所有元素的值都是 1。
#* 0:对这个数组中的每个元素乘以 0,使得所有元素的值变成 0res=pd.concat([df1,df2,df3],axis=0)#沿横轴方向合并
print(res) 
由上图可见,此时合并时保留了索引,即使索引是重复的
#通过ignore_index() 参数忽略索引。如果将参数设置为 True,那么合并时将会创建一个新的整数索引
res=pd.concat([df1,df2,df3],axis=0,ignore_index=True)
print(res)
类似join的合并
df1=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2=pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4])
# join=''默认是 'outer',表示并集;join='inner'表示交集;axis=1表示沿数轴方向合并
#ignore_index=Ture,合并时将会创建一个新的整数索引
res=pd.concat([df1,df2],join='inner',ignore_index=True)
res_2=pd.concat([df1,df2],join='outer',ignore_index=True)
res_3=pd.concat([df1,df2],axis=1,join='inner')
print(df1)
print(df2)
print(res)
print(res_2)
print(res_3)
💡join_axes 参数在 Pandas 1.0.0 之后已经被弃用,如果使用的是较新的版本,可能会遇到错误。由于 df.append() 已被弃用,推荐使用 pd.concat() 来进行类似操作
merge合并(pd.merge() 基于索引进行合并)
df1=pd.DataFrame({'key':['k1','k2','k3','k4'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
df2=pd.DataFrame({'key':['k0','k1','k2','k3'],
'C':['A0','A1','A2','A3'],
'D':['B0','B1','B2','B3']})
print(df1)
print(df2)
res=pd.merge(df1,df2)#如果没有指定key,merge就会将重叠列的列名当做键(默认inner方式合并)
res=pd.merge(df1,df2,on='key')#与上一行命令输出相同(为了说明指定key所用的语句)
print(res)
res=pd.merge(df1,df2,how='outer')#以并集方式合并
res_2=pd.merge(df1,df2,how='left')#使用左边表中所有键合并
res_3=pd.merge(df1,df2,how='right')#使用右边表中所有键合并

df1=pd.DataFrame({'col1':[0,1],'col_left':['a','b']})
df2=pd.DataFrame({'col1':[1,2,2],'col_left':[2,2,2]})
print(df1)
print(df2)
res=pd.merge(df1,df2,on='col1',how='outer',indicator=True)
print(res)
#indicator=True:这个参数会添加一个名为 _merge 的新列,显示每行是来自哪个 DataFrame。
#'left_only':表示该行只在 df1 中存在。
#'right_only':表示该行只在 df2 中存在。
#'both':表示该行在 df1 和 df2 中都存在。

res=pd.merge(df1,df2,on='col1',how='outer',indicator='indicator_column')
#将_merge改名为'indicator_column'
df1=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']},
index=['K0','K1','K2'])
df2=pd.DataFrame({'C':['C0','C2','C3'],
'D':['D0','D2','D3']},
index=['K0','K2','K3'])
print(df1)
print(df2)
res_1=pd.merge(df1,df2,left_index=True,right_index=True,how='outer')
#left_index=True 和 right_index=True:指定在合并时使用两个 DataFrame 的索引作为键。
#how='outer':外连接,将两个 DataFrame 的所有索引保留在结果中,缺失的数据填充为 NaN
print(res_1)
boys=pd.DataFrame({'k':['K0','K1','K2'],'age':[1,2,3]})
girls=pd.DataFrame({'k':['K0','K0','K3'],'age':[4,5,6]})
res=pd.merge(boys,girls,on='k',suffixes=['_boys','_girls'],how='inner')
#suffixes=['_boys', '_girls']:当两个 DataFrame 中有相同的列名(除了连接列外),
#Pandas 会自动为这些列加上后缀避免列名重复(默认为‘_x’,'_y'),此命令所加后缀分别为 '_boys' 和 '_girls'
print(boys)
print(girls)
print(res) 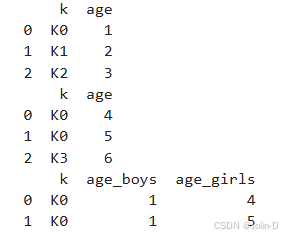
绘图和可视化(简介)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.Series(np.random.randn(1000),index=np.arange(1000))
data=data.cumsum()
data.plot()
plt.show()
生成随机数:
#np.random.randn(1000):生成 1000 个随机数,符合标准正态分布(均值为 0,标准差为 1)。
#np.arange(1000):生成一个从 0 到 999 的索引数组,作为 Series 的索引。
#通过 pd.Series() 将生成的随机数和索引组合成一个 Pandas Series
计算
#data.cumsum():计算累积和(即当前值和前面所有值的和),每个点的值是前面所有随机值的和。
绘图
#data.plot():利用 Pandas 内建的绘图功能生成一个线性图(默认情况下是折线图)
#图形的横轴表示数据的索引(从 0 到 999),纵轴表示随机数的累积和。
data=pd.DataFrame(np.random.randn(1000,4),
index=np.arange(1000),
columns=list('ABCD'))
data=data.cumsum()
data.plot()
plt.show()
#调用 DataFrame 内建的绘图方法,这里会默认生成一个折线图,其中每一列的数据将被绘制成一条线。
data=pd.DataFrame(np.random.randn(1000,4),
index=np.arange(1000),
columns=list('ABCD'))
data=data.cumsum()
ax=data.plot.scatter(x='A',y='B',color='DarkBlue',label='Class 1')
#绘制了一个散点图,横轴为 A 列,纵轴为 B 列,点的颜色为 DarkBlue,该数据集命名为 Class 1
data.plot.scatter(x='A',y='C',color='DarkGreen',label='Class 2',ax=ax)
#绘制了另一个散点图,横轴为 A 列,纵轴为 C 列,点的颜色为 DarkGreen,该数据集命名为 Class 2。
#ax=ax 参数表示将第二个散点图绘制在同一个坐标轴 ax 上,这样它会和第一个图的散点图叠加在一起。
plt.show() 


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









