




Qwen2-VL 视觉大模型Qwen2-VL-7B-Instruct部署
注:本文完全参考b站博主:小林绿子的怀中猫 讲解内容,文章的图片几乎完全出自其讲解视频,我只是对其进行了注释,此篇博客完全是为了记录操作流程方便后续查看学习,如有侵权联系我删除。
b站视频:1.从零部署qwen2-vl-7b-Instruct模型_哔哩哔哩_bilibili
- 环境(在AutoDL上进行快速部署)
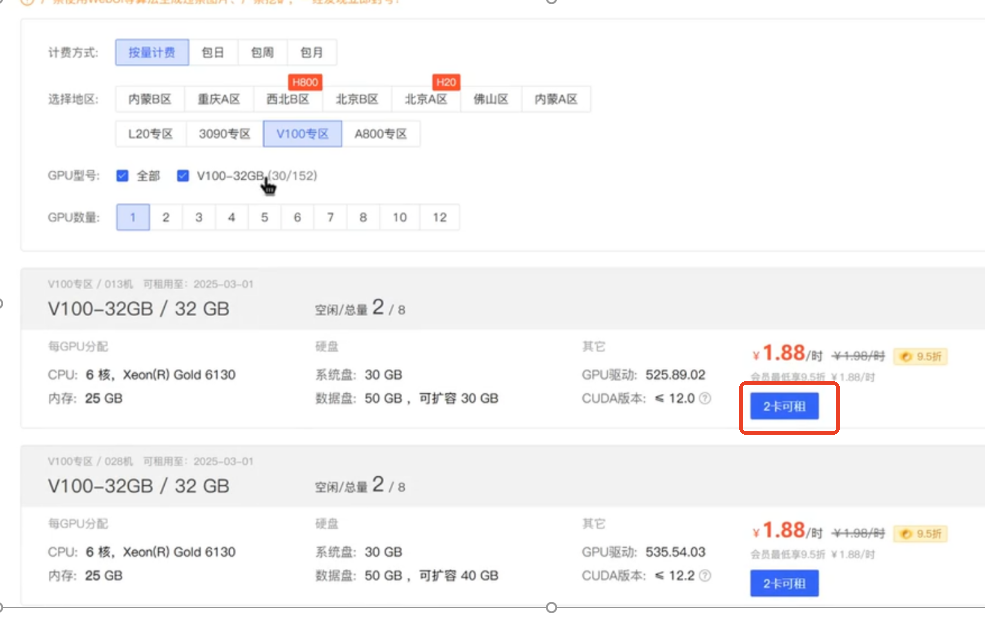
计费方式选择按量计费,地区选择V100专区,GPU型号选择V100-32GB,GPU数量选择1台,如图中红框所示任意点击可租用的服务器。
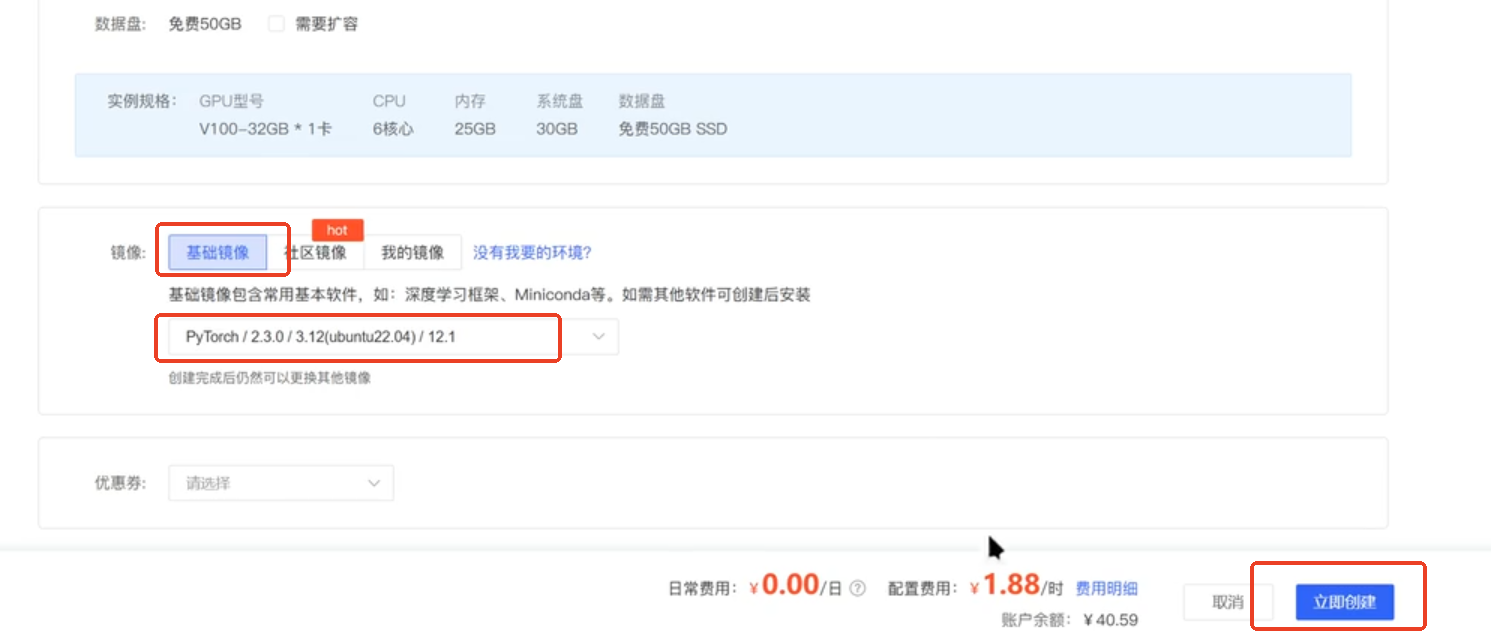
选择基础镜像,pyTorch/2.3.0/3.12(ubuntu22.04)/12.1,然后点击立即创建。
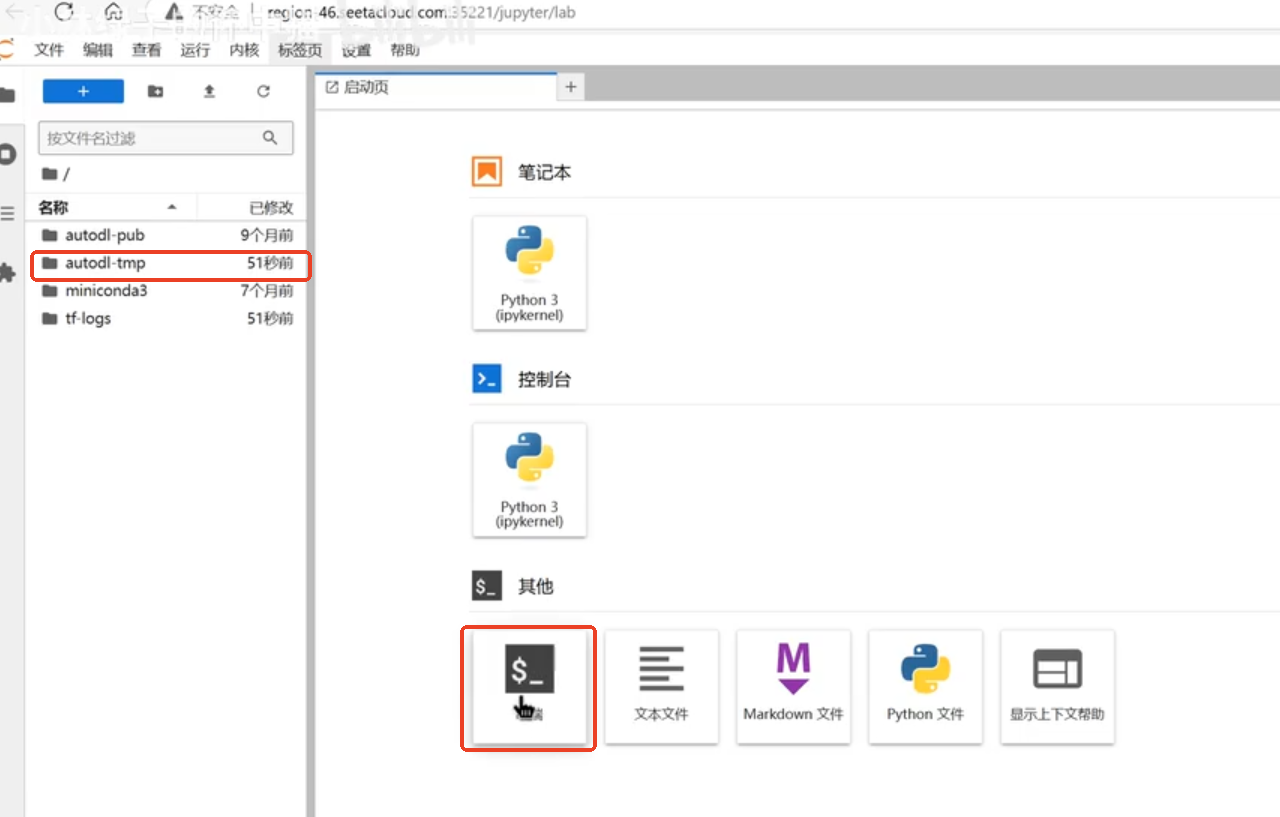
当服务器创建好后,点击JupyterLab

要把下载的内容放到数据盘(autodl-tmp)中,否则万一下错会占用系统盘很多内存。
- 模型下载
点击autodl-tmp文件夹,在其中创建download.py,并在其中编写模型下载代码。
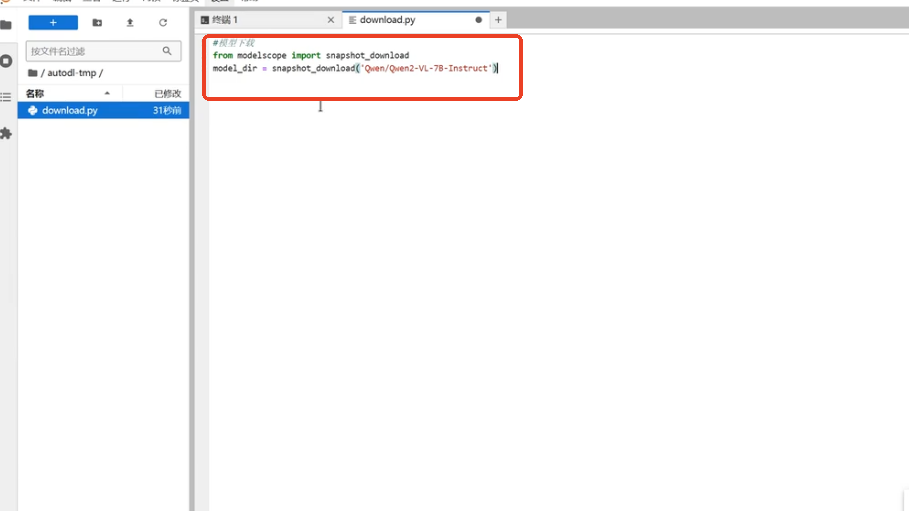
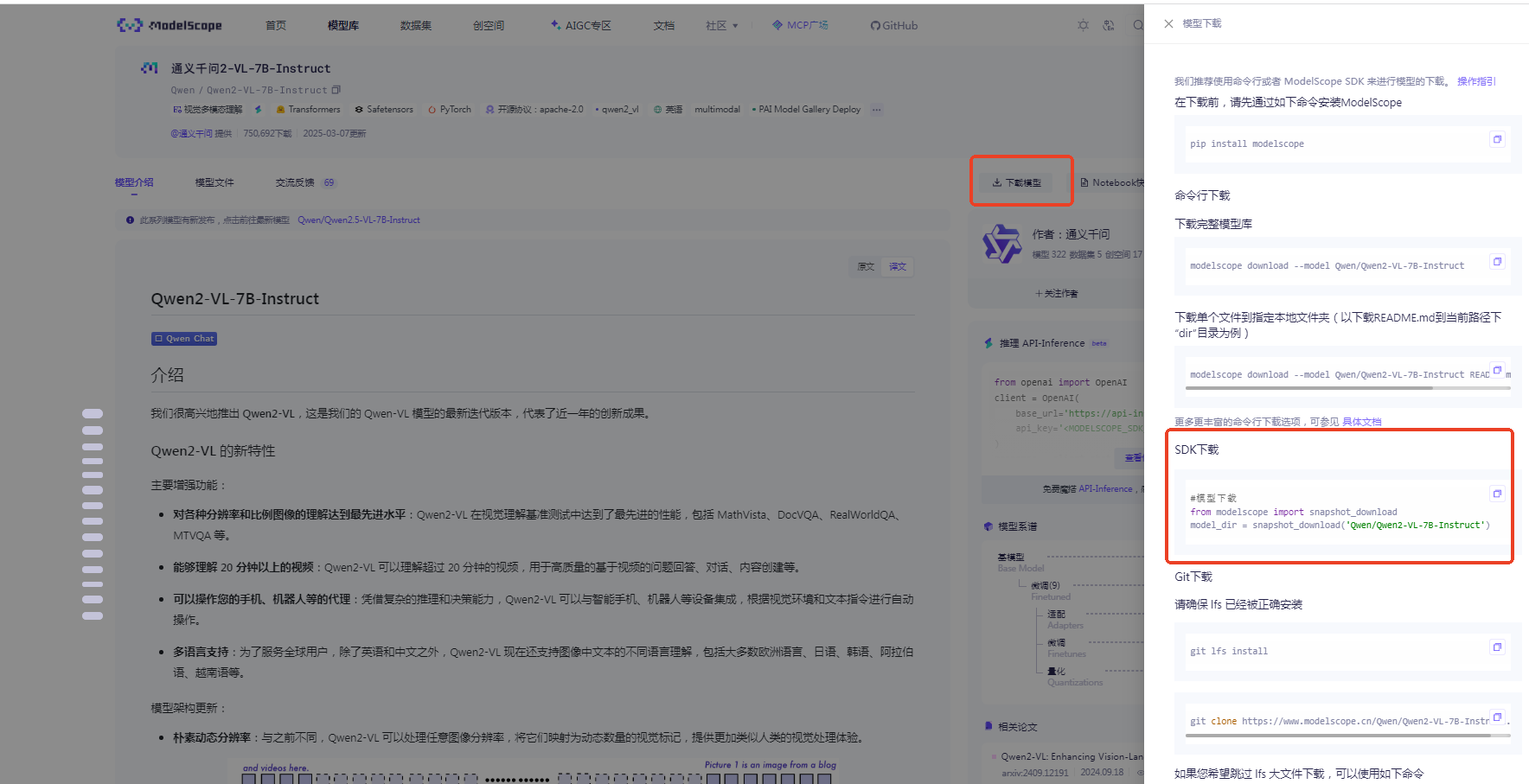
上述红框中代码内容来自ModelScope,其模型下载地址为:ModelScope 魔搭社区,点击该下载地址,进入以下界面,该界面为Qwen2-VL-7B-Instruct相关内容下载界面,点击下载模型,赋值 SDK下载条例中内容复制到download.py文件中即可,然后CTRL+S保存即可。
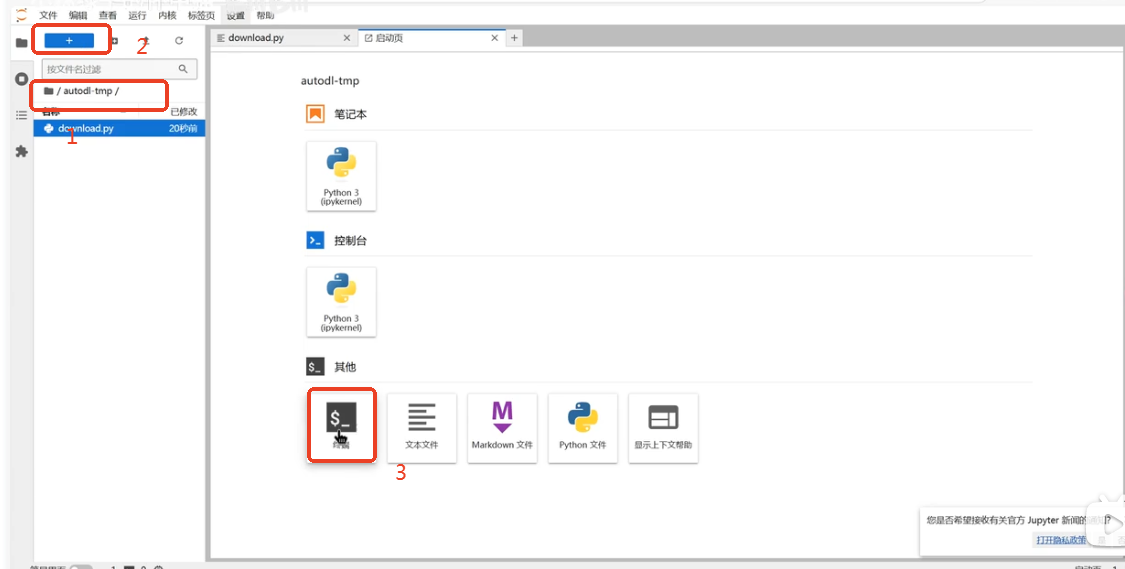
在autodl-tmp文件夹下创建终端,确保在autodl-tmp文件夹下,如图中1所示,点击2出+号,在弹出界面中点击终端(如图中3处所示),终端创建成功。
点击终端后,弹出如下界面:
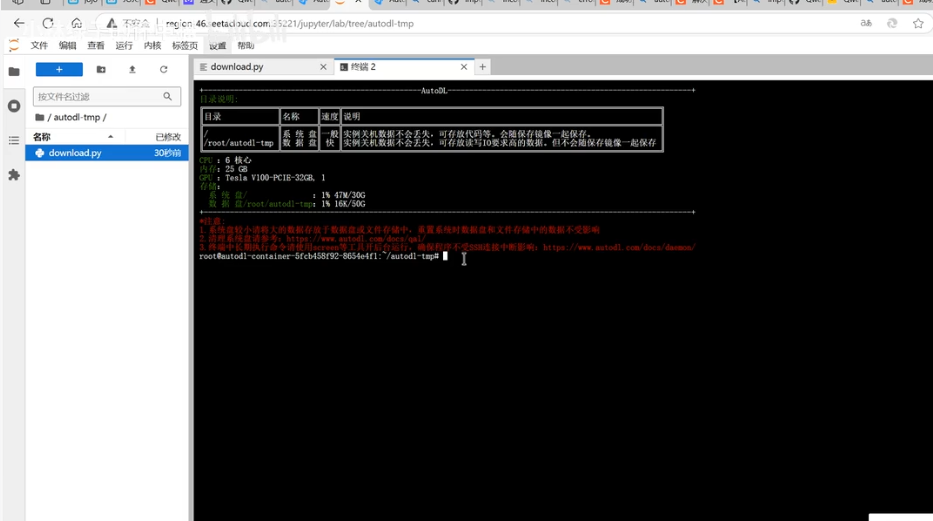
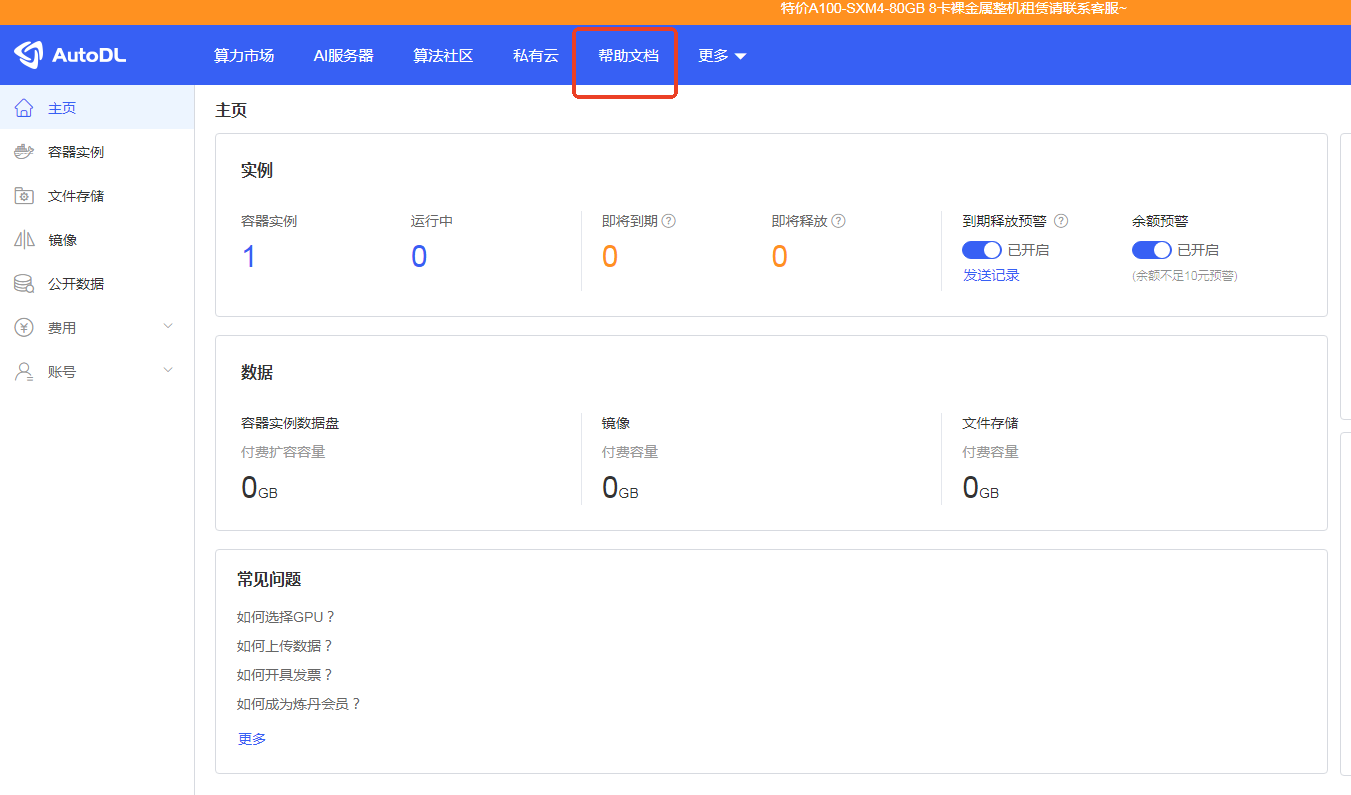
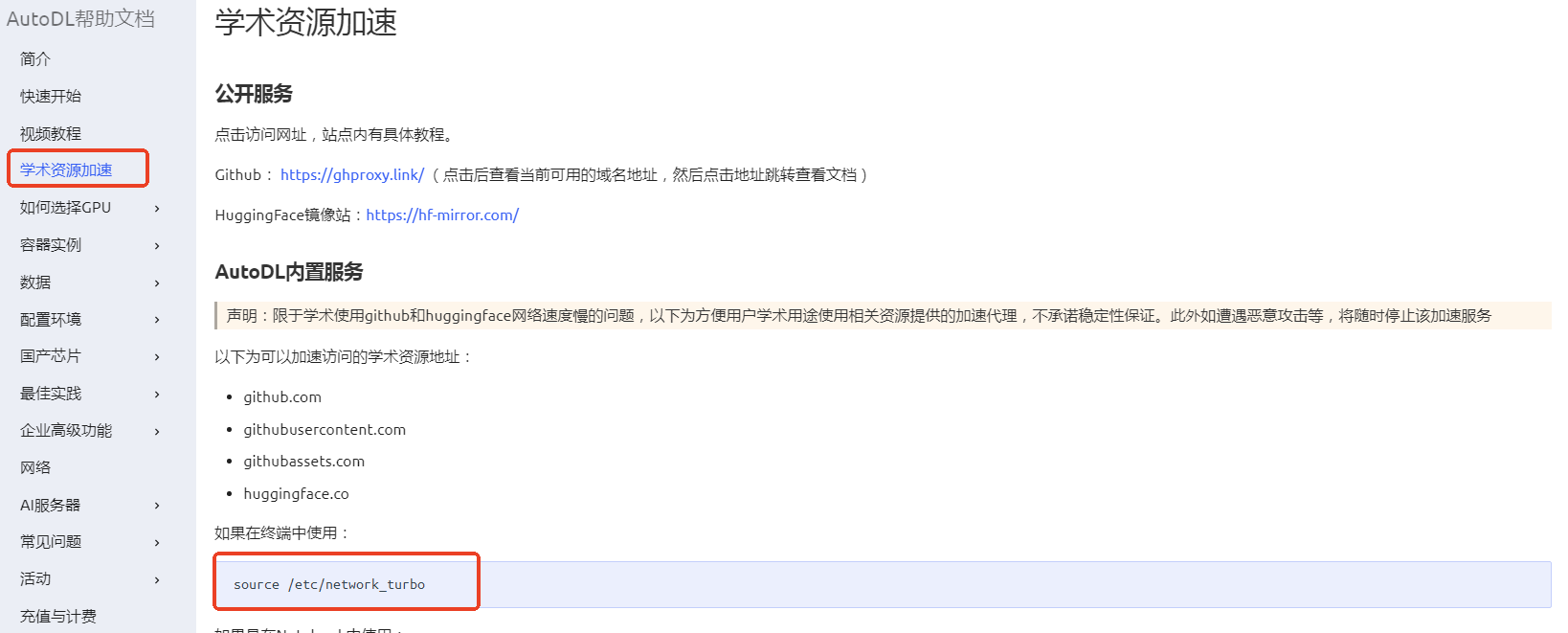
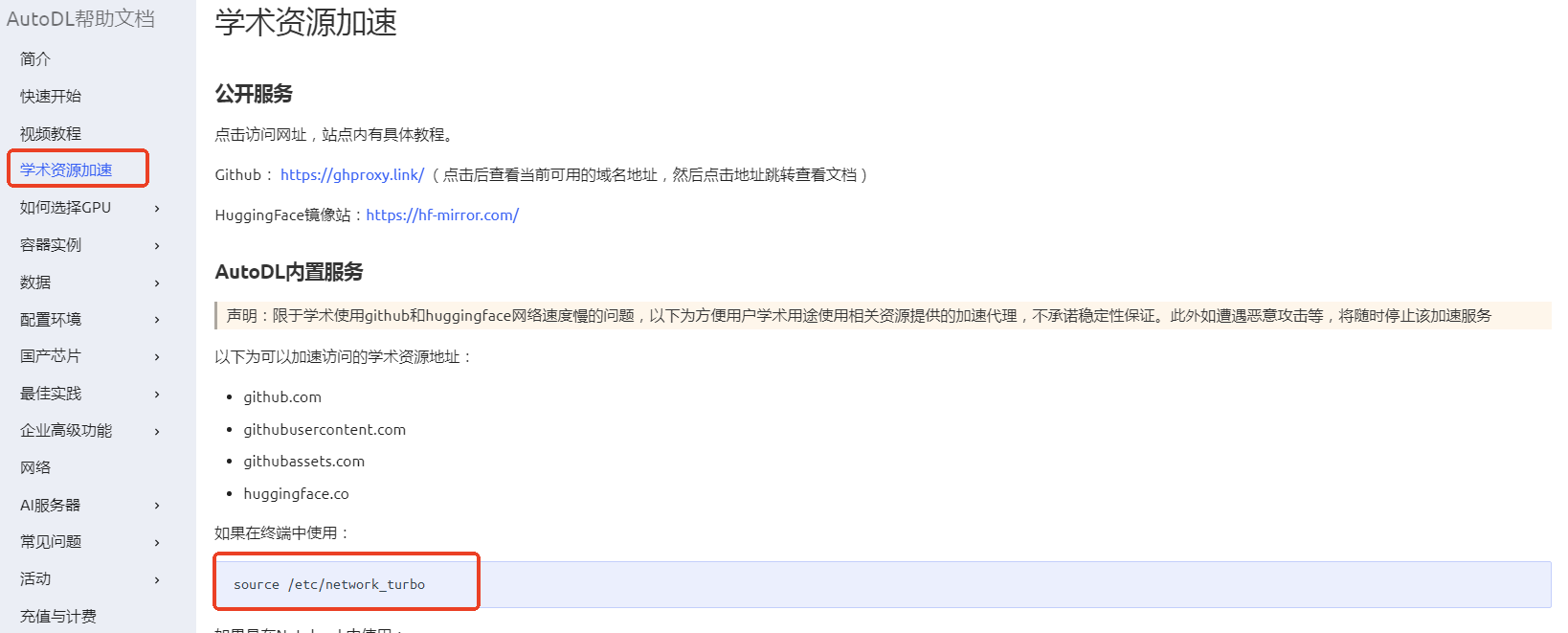
首先下载modelscope,复制:pip install modelscope至终端对话框,后按回车键即可运行。下载模型如果速度太慢可进行学术加速。点击帮助文档。
点击学术自选加速,复制红框中的代码至终端界面执行。
![]()
然后再运行download.py

- 项目代码与安装
https://github.com/QwenLM/Qwen2-VL
在autoal-tmp中创建一个文件夹,命名为Qwen;
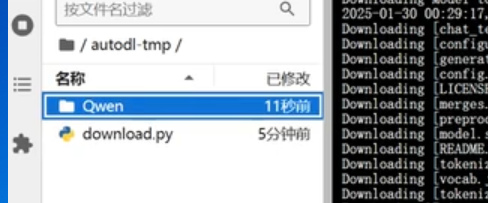
然后跑进入Qwen的文件夹再打开一个终端。
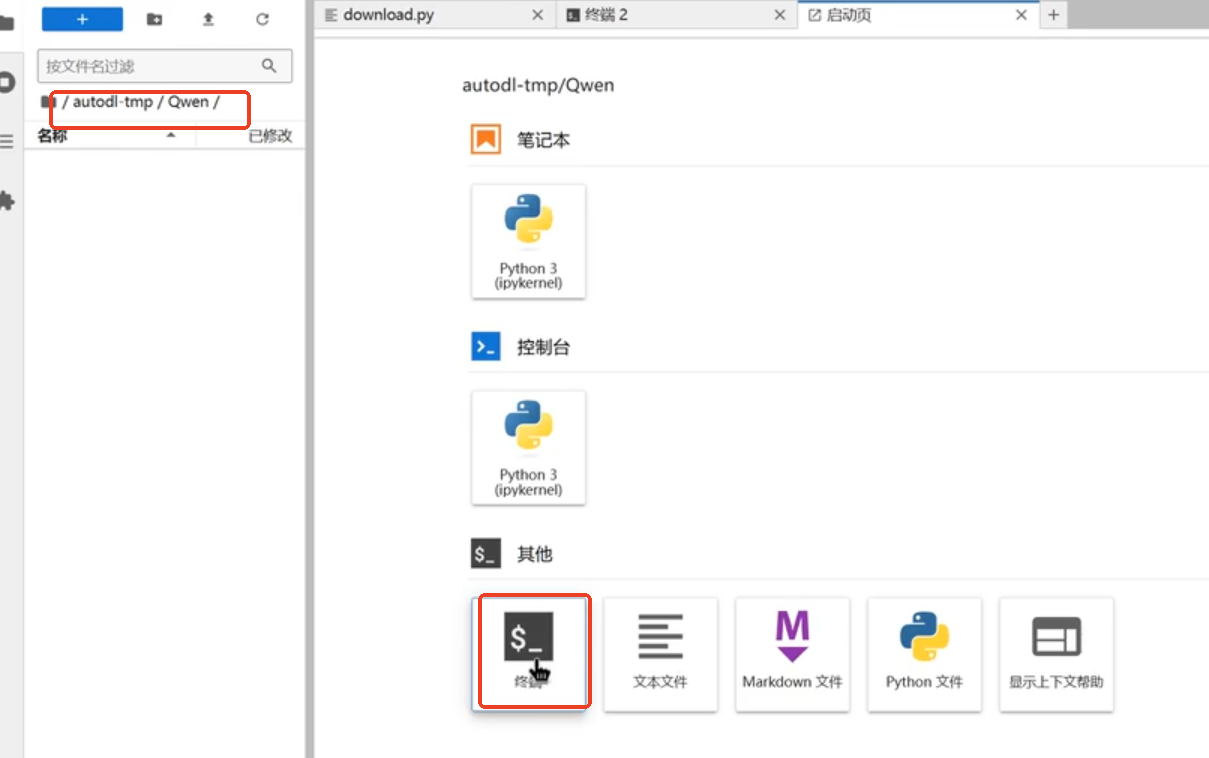
然后将下列代码复制到新建终端运行;
git clone https://github.com/QwenLM/Qwen2-VL
cd Qwen2-VL
pip install qwen-vl-utils[decord]
pip install transformers
pip install 'accelerate>=0.26.0'
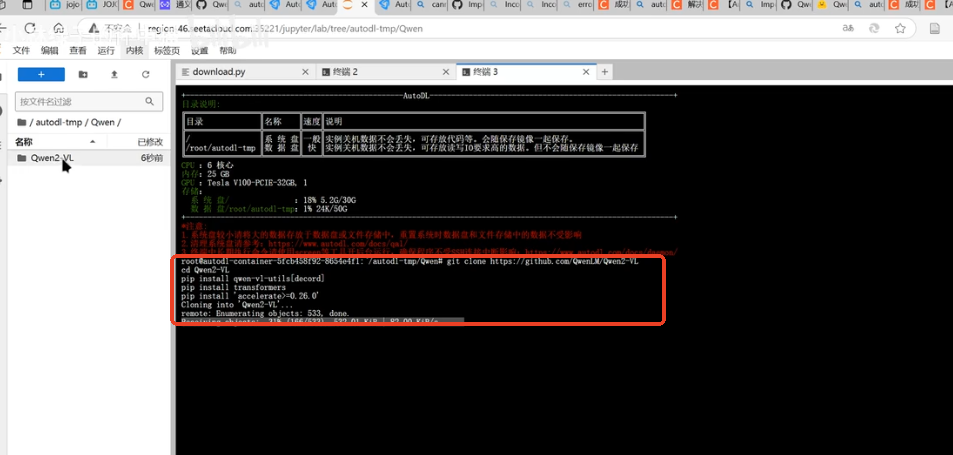
可能会报错,如下:
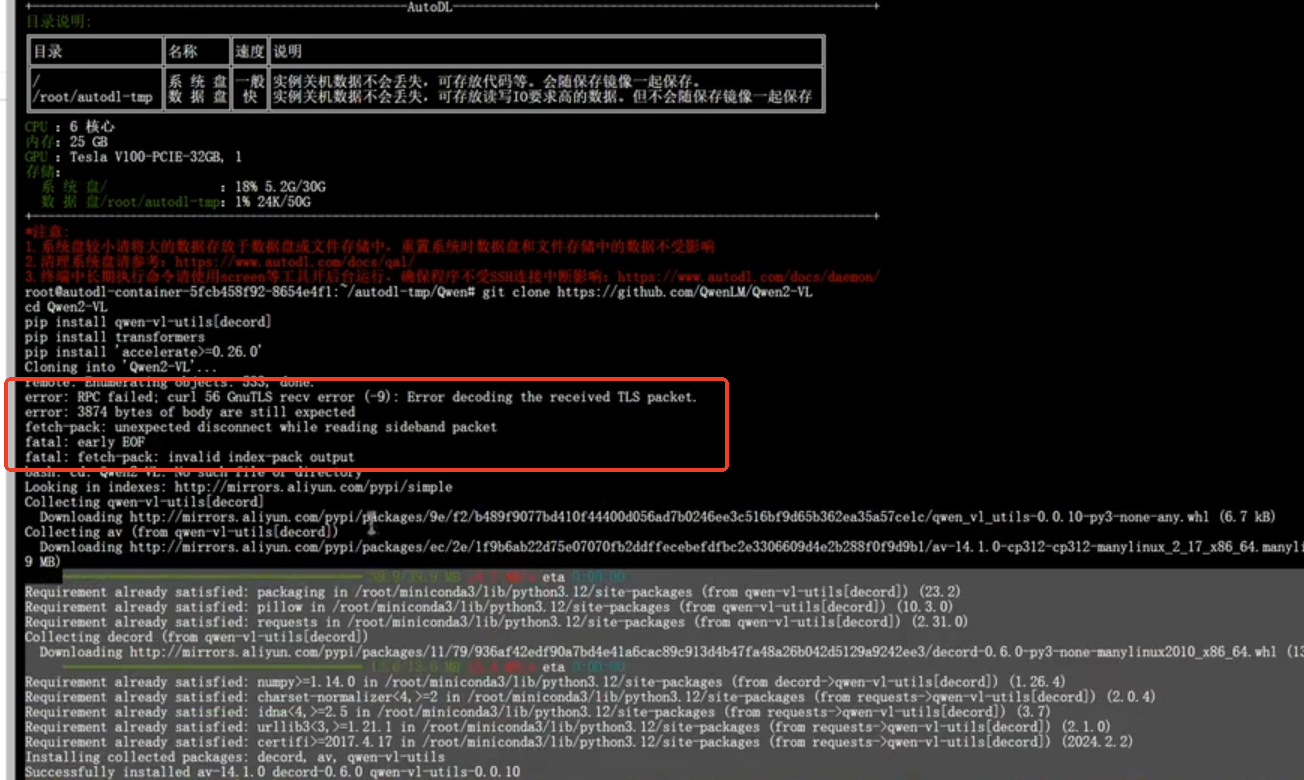
此处报错说明pip三行代码下载成功,项目Qwen2-VL没有安装成功;
可在使用学术加速,即每新开一个终端都要使用学术加速。source /etc/network_turbo
![]()
然后在终端命令行输入:git clone https://github.com/QwenLM/Qwen2-VL进行下载
![]()
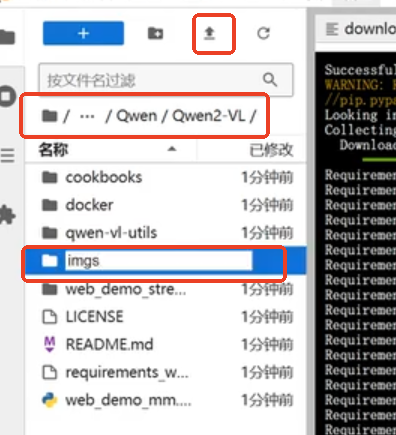
安装完成后在Qwen/Qwen2-VL文件夹中创建imgs,并点击上传图片按钮上传传本地下载图片。
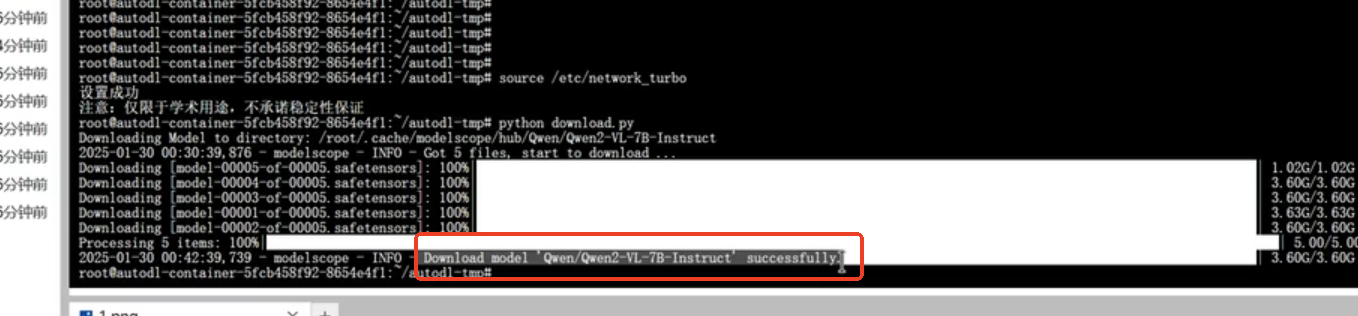
判断模型是否下载成功查看,若出现Download model successfully则表示模型下载成功。否则表示没有下载成功。
- 移动模型
一般建议放在数据盘(因为没有足够把握,若出现错误放到系统盘会爆)
此处要特别注意自己模型所下载的路径,以下为自己模型路径(若界面上没有显示下面图片红框中的路径,可以在执行一下python dowonload.py 会提示已经下载好模型,并显示出下载路径)

然后移动路径:mv /root/.cache/modelscope/hub/Qwen/Qwen2-VL-7B-Instruct /root/autodl-tmp/Qwen/;
上述将模型移动至与Qwen2-VL同级目录

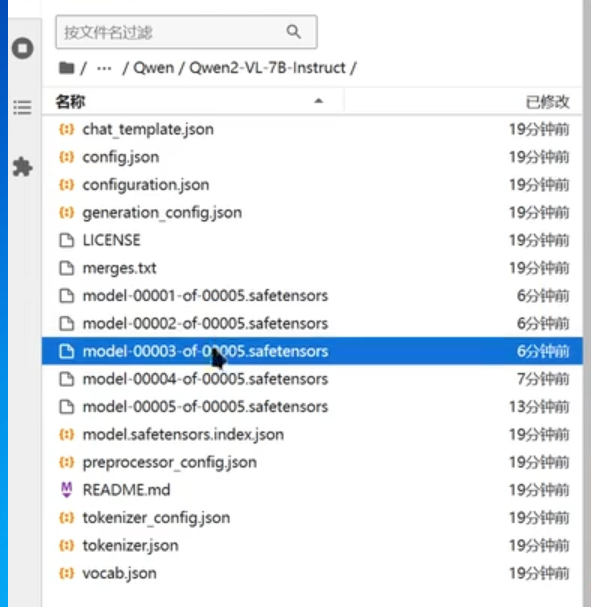
移动好后该文件下应该包含下述文件
然后在项目文件中新建一个文件test.py
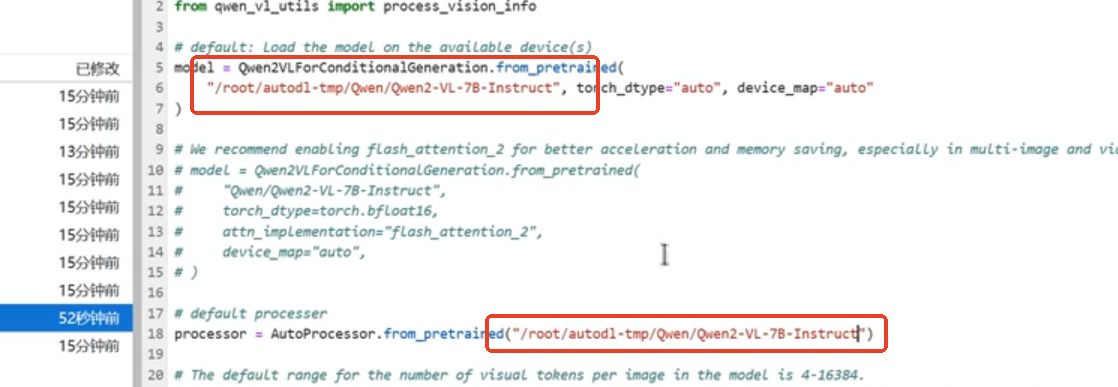
并在test.py中粘贴下列内容,有三处需要修改,分别为模型路径和图片存储路径,用红色框出,其中模型路径一定和上述保持一致(移动后的)。
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"/root/autodl-tmp/Qwen/Qwen2-VL-7B-Instruct", torch_dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2-VL-7B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained("/root/autodl-tmp/Qwen/Qwen2-VL-7B-Instruct ")
# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "imgs/1.png",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
对图片进行提问修改test.py中如下内容,可根据自己的需求提问

点击ctrl+s保存,然后进入终端3(项目文件所创建的终端)输入python test.py运行

运行结果如下:
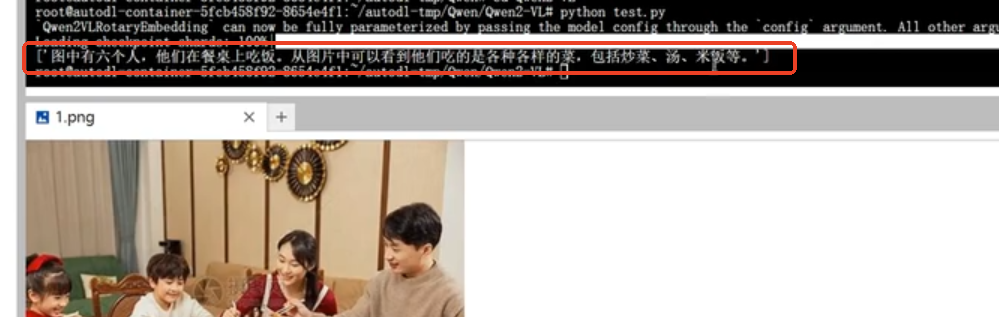
7B模型的推理能力还有待加强;


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









