




本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。
课程内容:
1、@Autowired注入底层源码解析
2、@Value底层源码解析
3、@Qulifier底层源码解析
4、@Lazy底层源码解析
5、泛型注入底层源码解析
6、@Resource底层源码解析
上一节我们讲了寻找注入点,会找每一个属性上面是谁加了注解的,找准注入点,然后进行注入。
在对方法进行依赖注入的时候,一个方法可能有多个参数。

首先把入参的个数找到,然后构造一个数组,然后遍历这个参数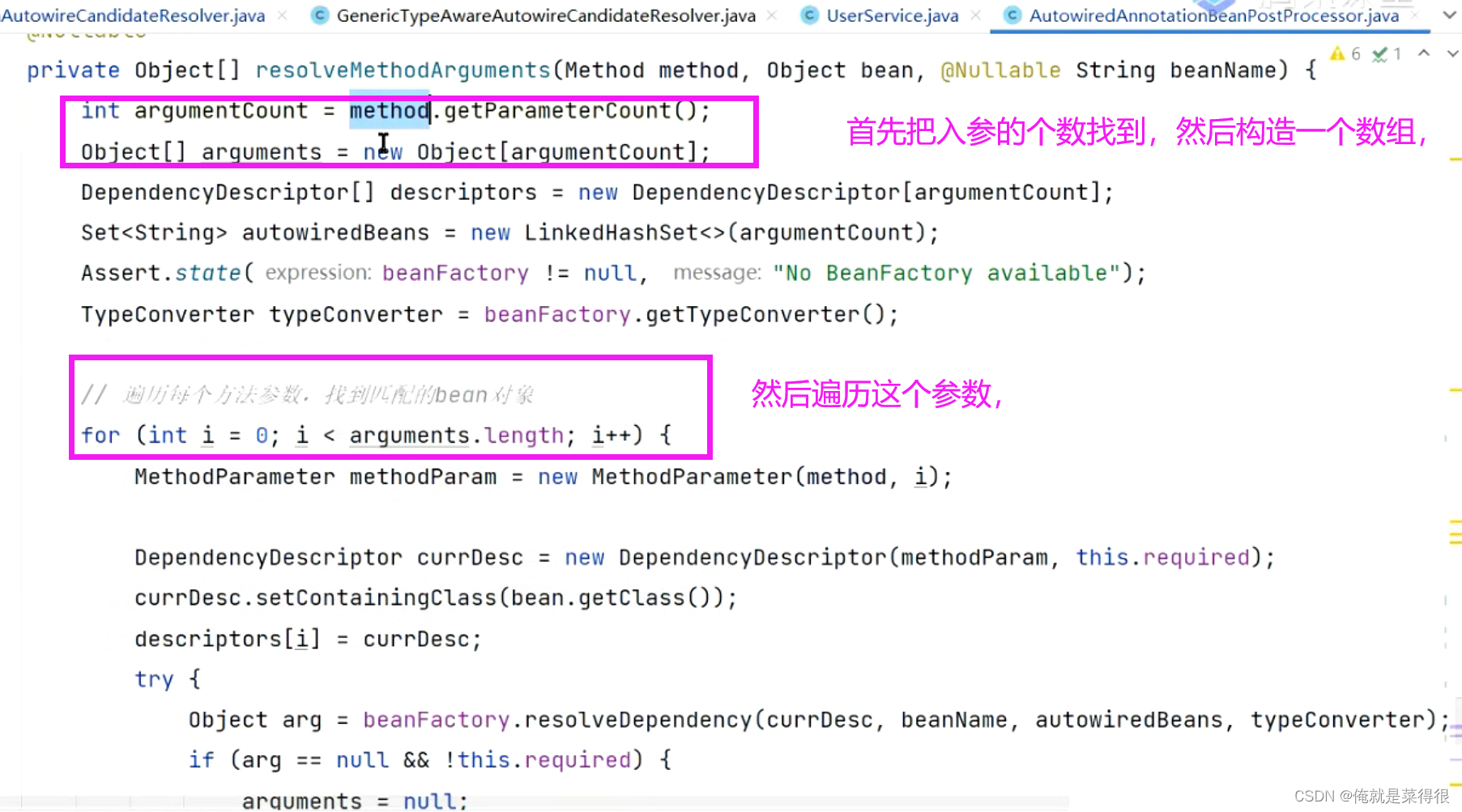
把参数的信息找出来,参数的名字、类型。arguments存的就是bean
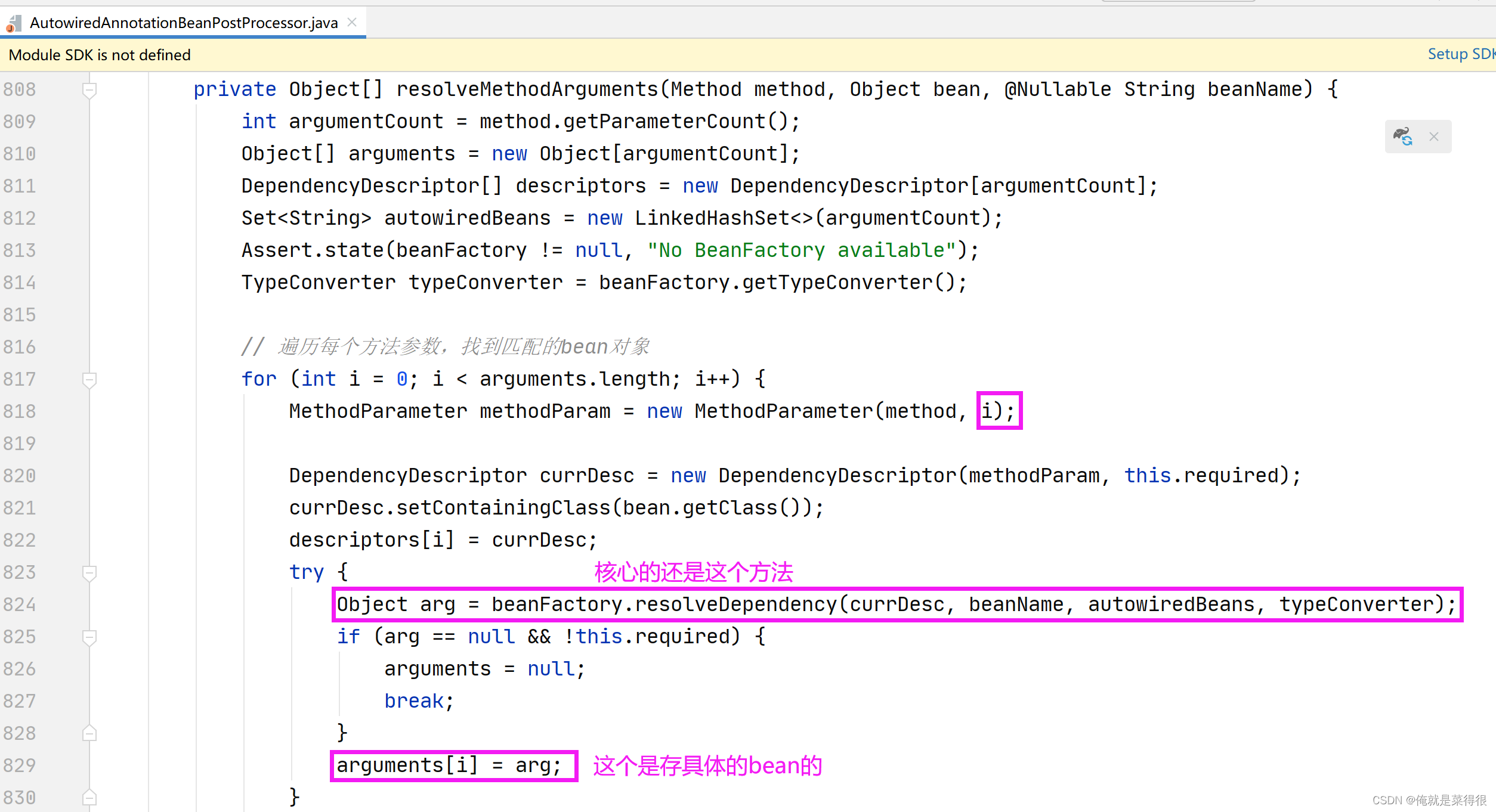
我们进入这个核心的方法
进入这个方法我们无论是方法还是字段我们进来就拿两样:名字和类型。
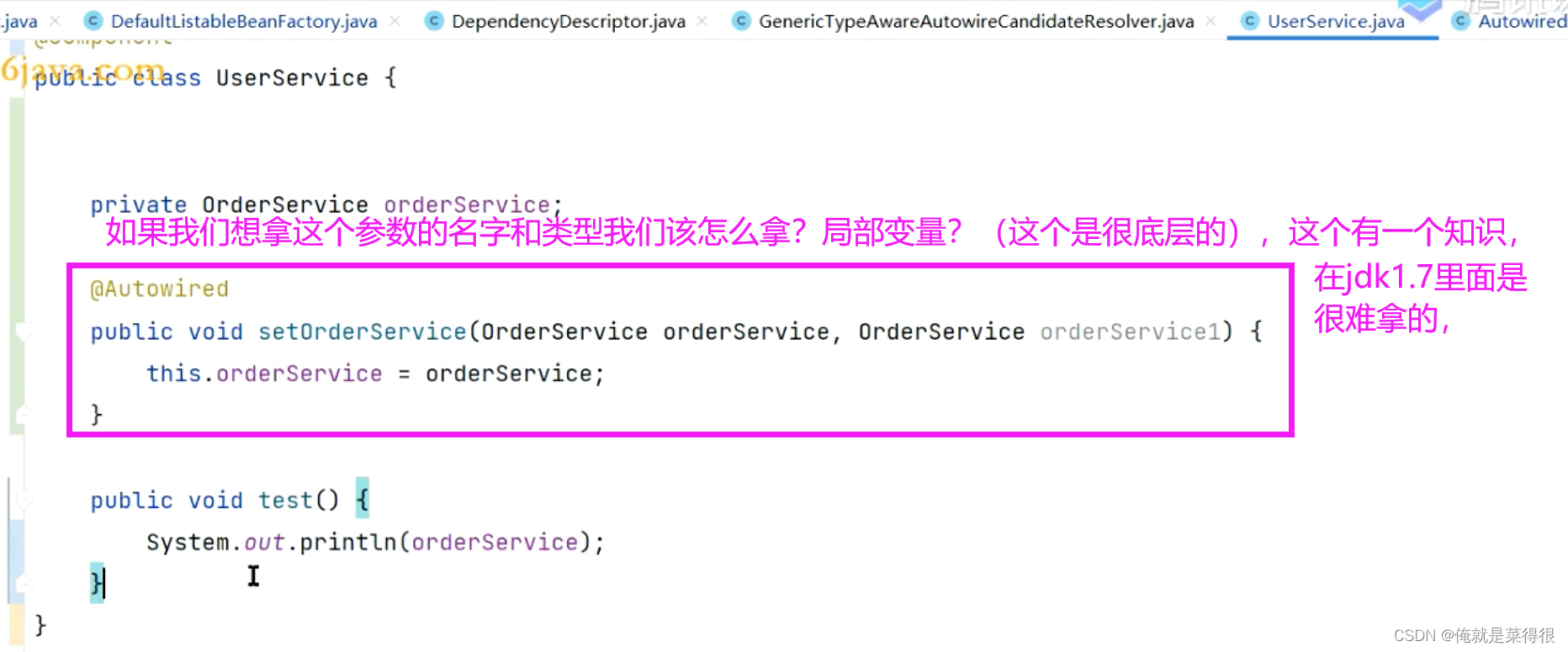
比如我们简简单单写一个demo,我们这有一个a方法,这个a方法里面有一个参数。我们当前把这个a方法所对应的method对象拿到,我们现在把他切换成为jdk1.7,我们拿到这个method对象了,我们想拿到当前这个方法的参数。在这个1.7里面没有这个反射的api拿到方法的参数的,我们可以很容易拿到这个参数的类型,但是我们想拿到这个a方法里面的abc就比较难。我们可能需要通过一些字节码之类的才能拿到。

其实我们改成1.8之后他就提供了一个api,就可以实现很容易拿到名字。
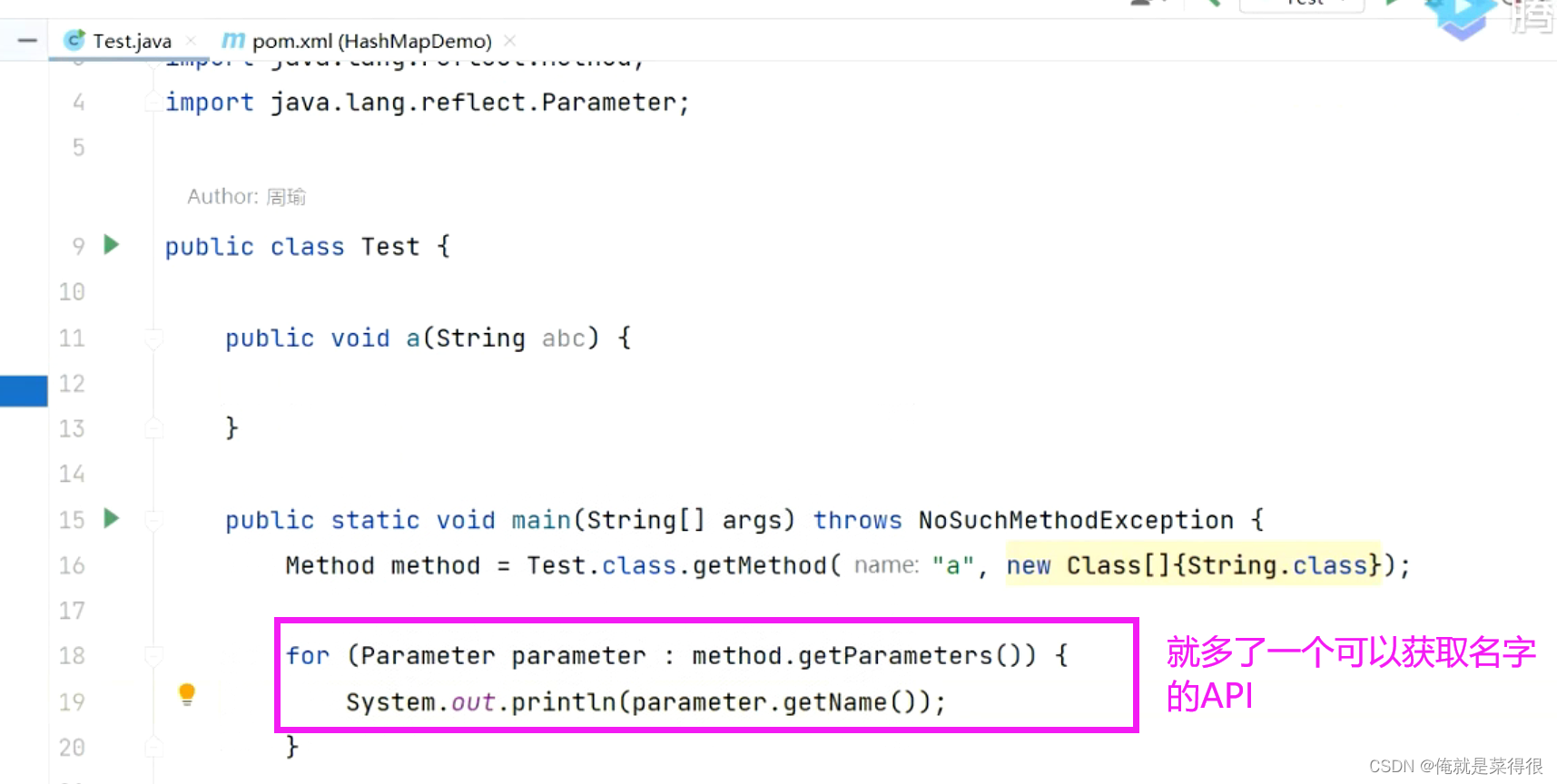
但是现在还拿不到名字,需要两步走,第一步:首先在pom.xml中进行jdk1.8的配置,除此之外还多一项配置。
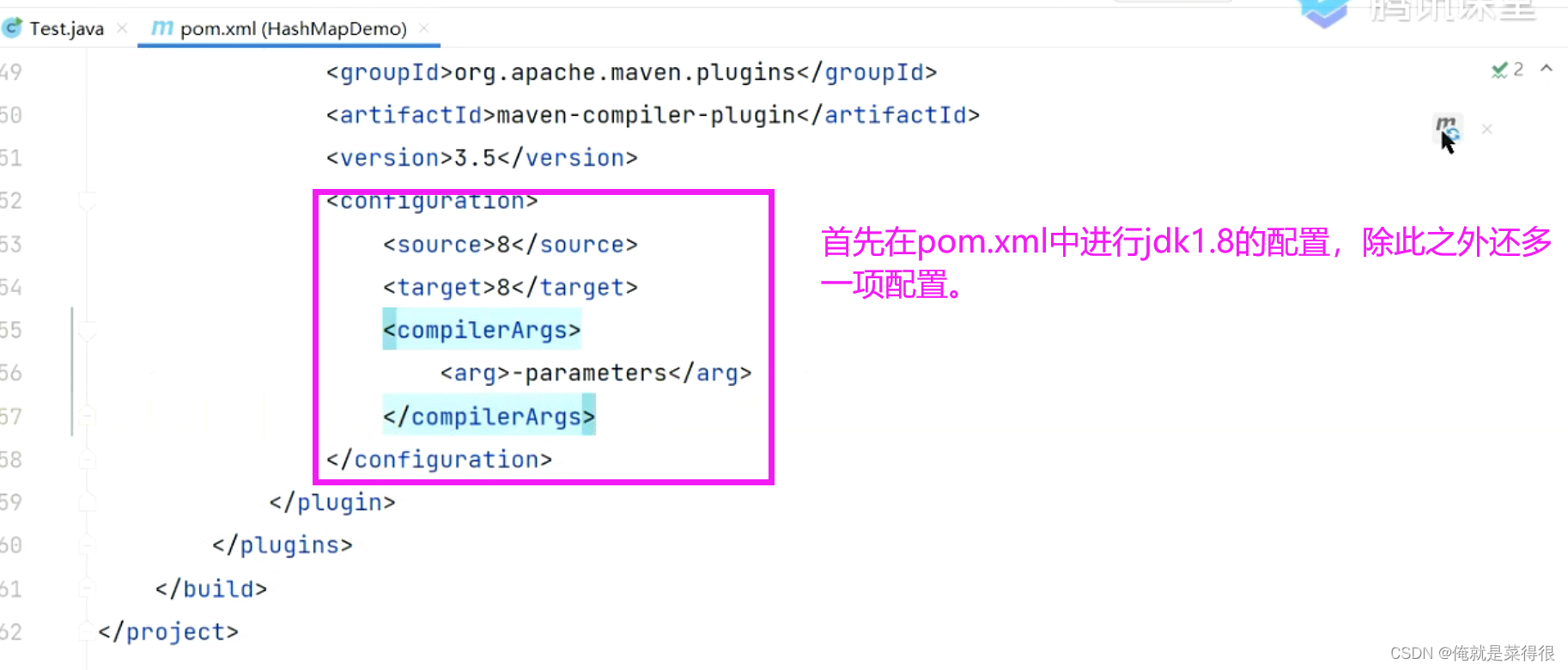
第二步:还要改一下项目的jdk配置:
初始化参数名字的一个发现器。
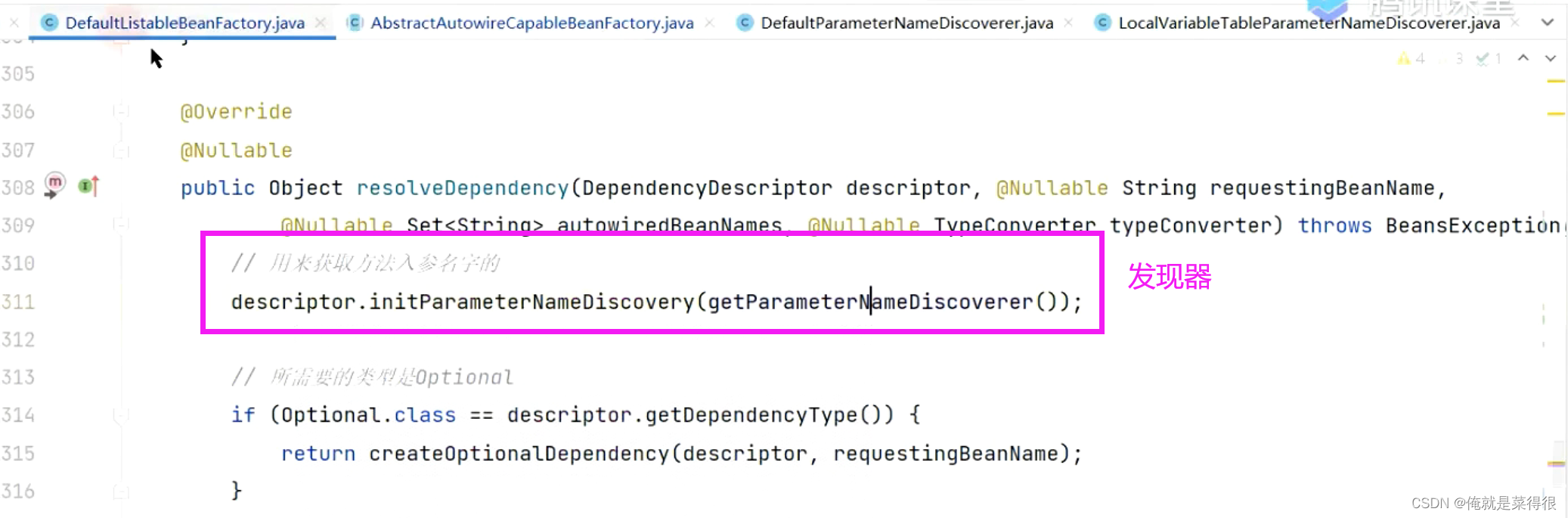
这个发现器里面包含两种方法,一个是基于反射的方法一个是就是基于更底层的字节码层面的方法,还是可以基于更底层的方法拿到的。

继续看这个方法
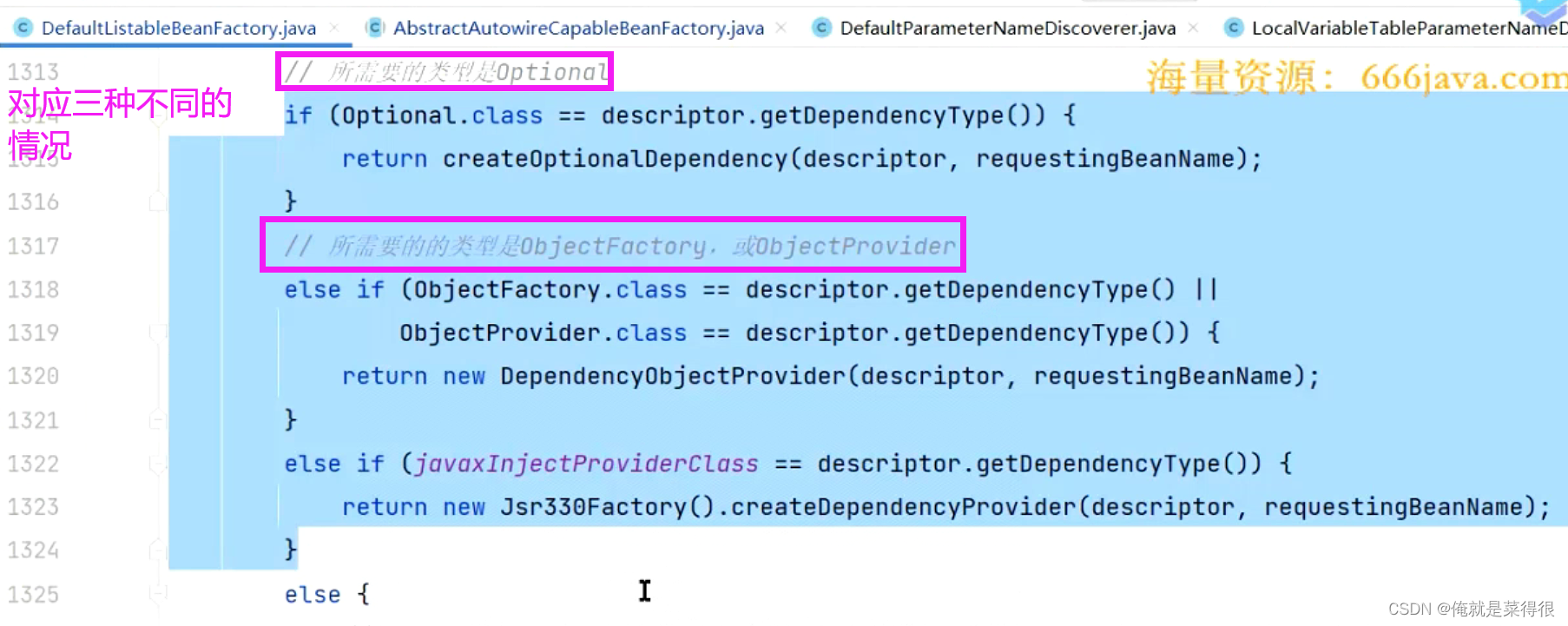
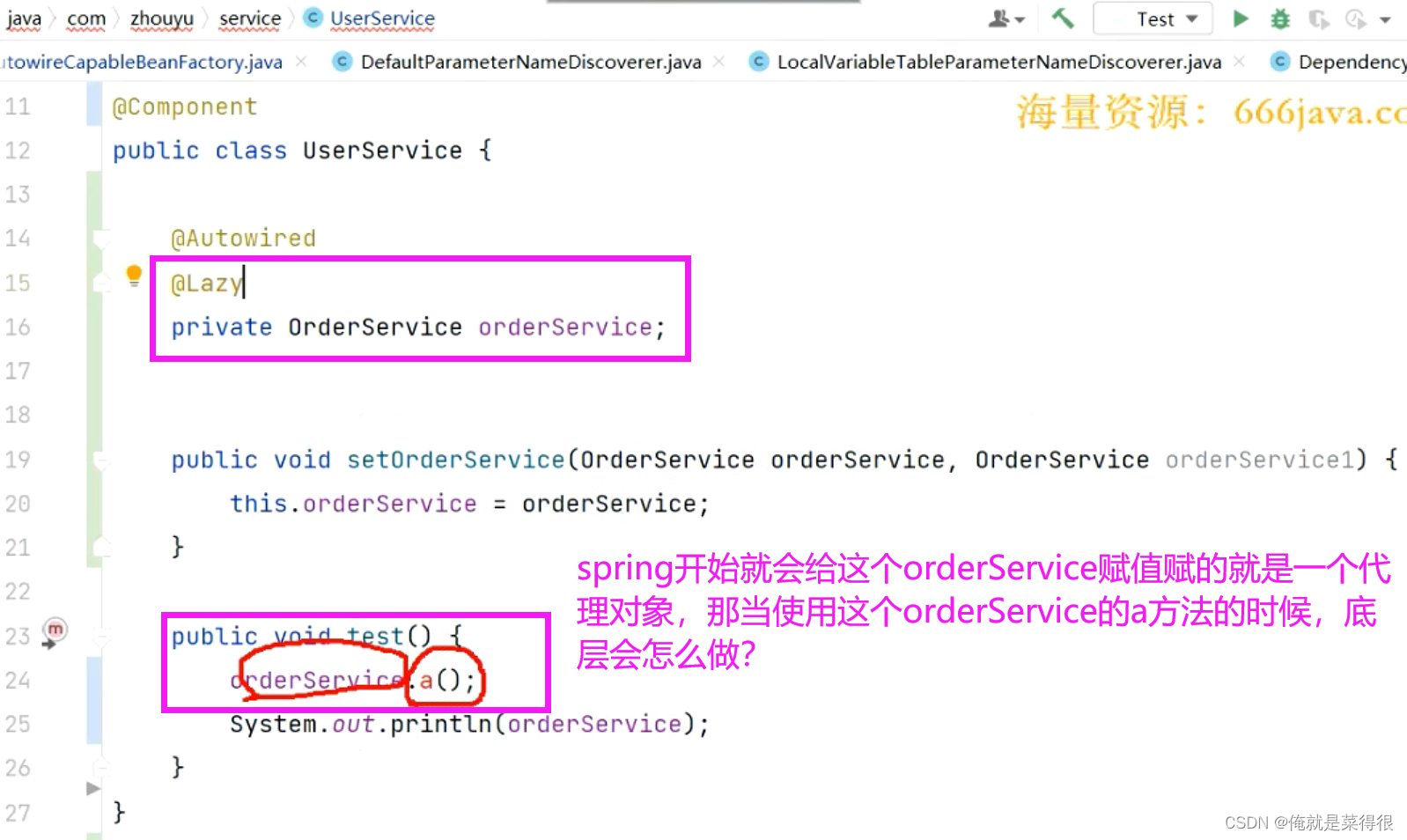
我们先不管这个,先看核心的流程,如果我们的字段就是orderService,那么这个程序是怎么做的呢?

那么就会进到下面这个else方法里面来。下面这个方法里面有一个Lazy。就是判断当前这个属性上有没有写Lazy这个注解,或者方法参数里面有没有这个Lazy这个注解。
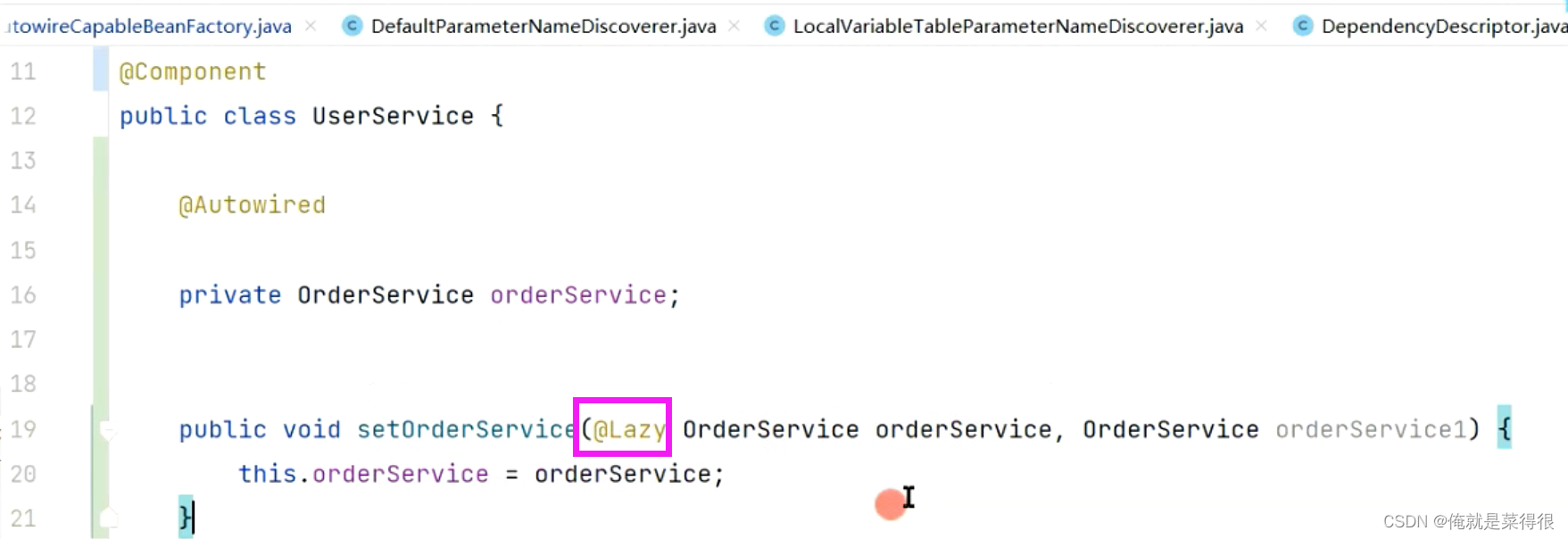
字段上有lazy注解

他是如何判断的呢?其实Lazy疏解可以写在一个类上,也可以写在一个属性上面,还可以写在一个方法的参数前面。如果我们写在一个属性前面的意思是会产生一个代理对象。
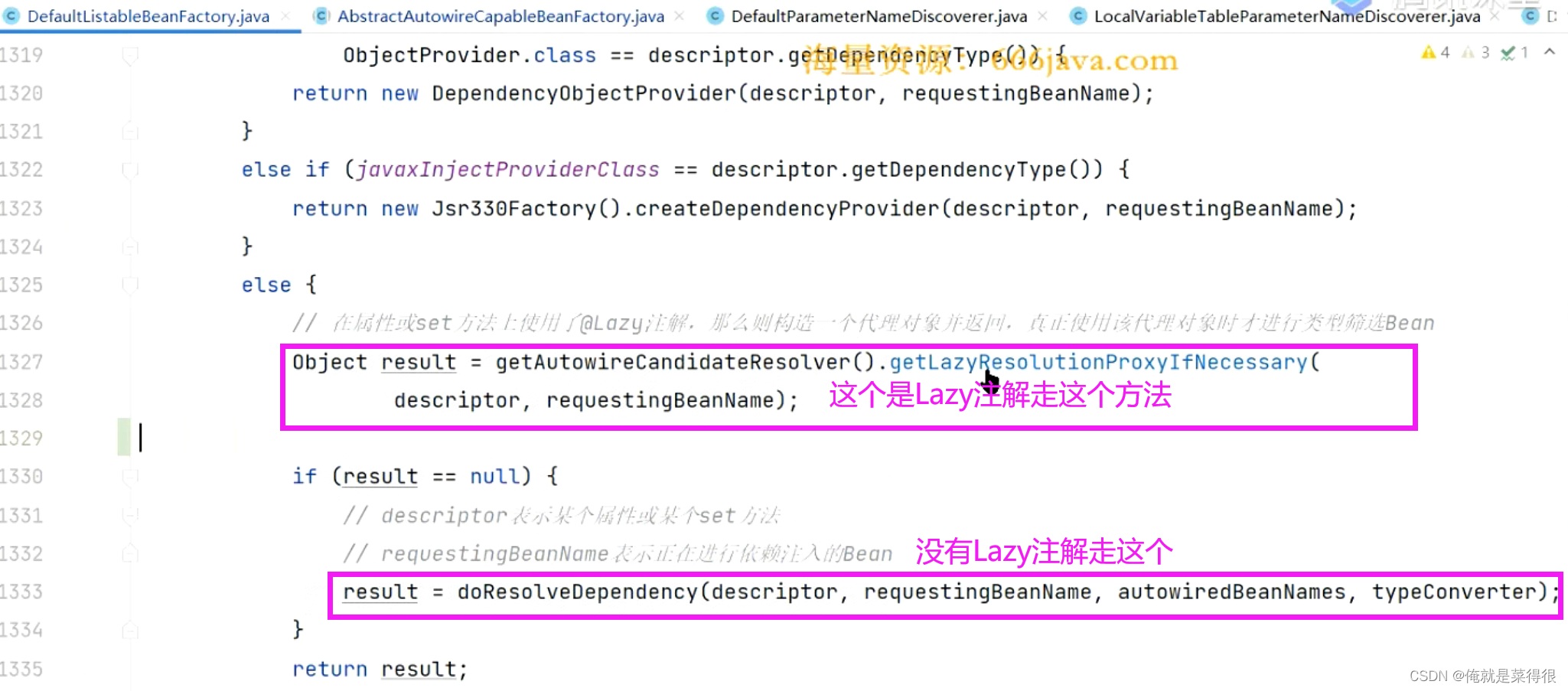
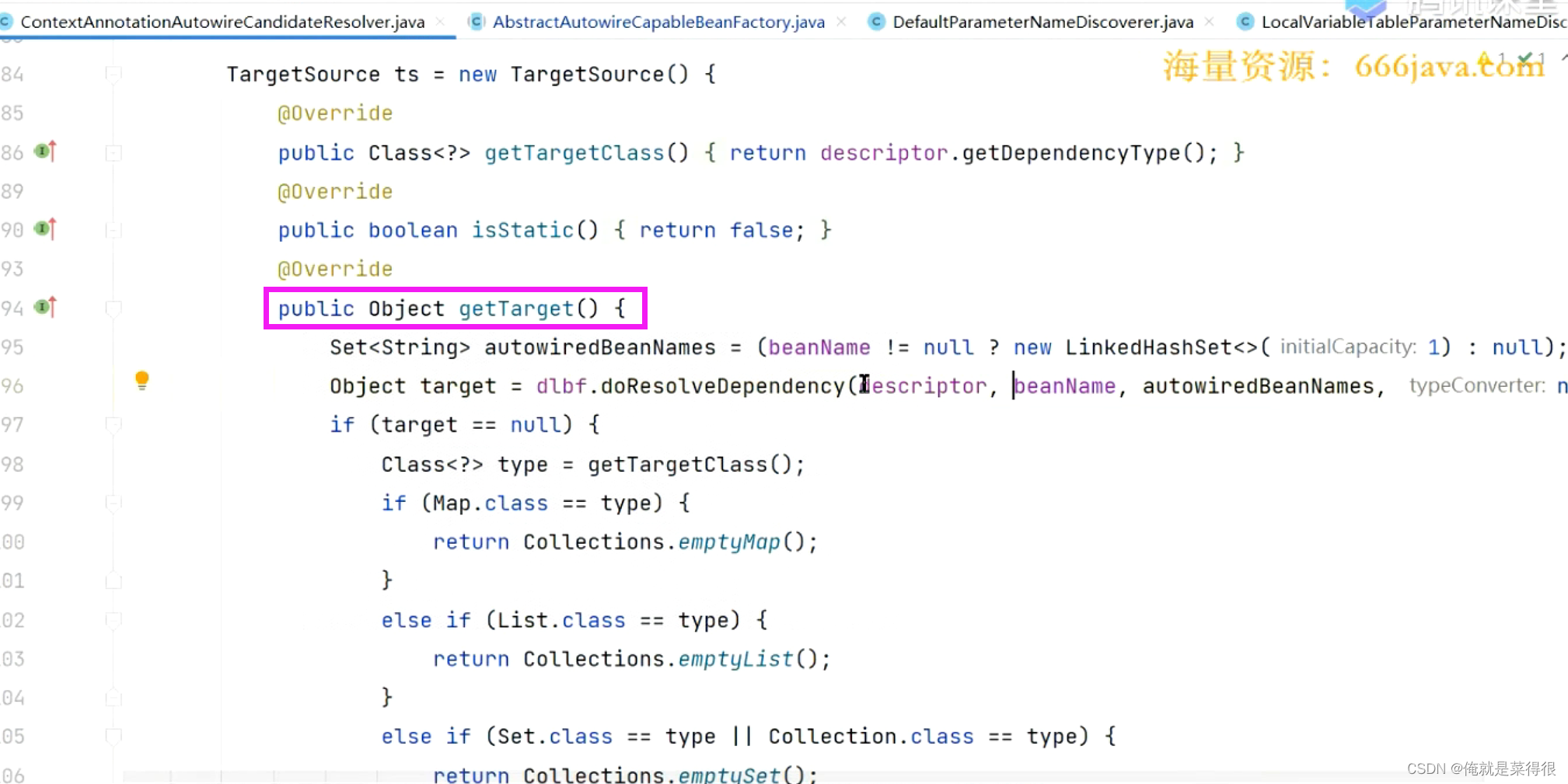
假设判断出来有了,就进入第一个方法

看这个接口的实现类。这个就是判断你这个属性有没有Lazy注解。下面这个判断你这个方法的参数前面有没有lazy注解。
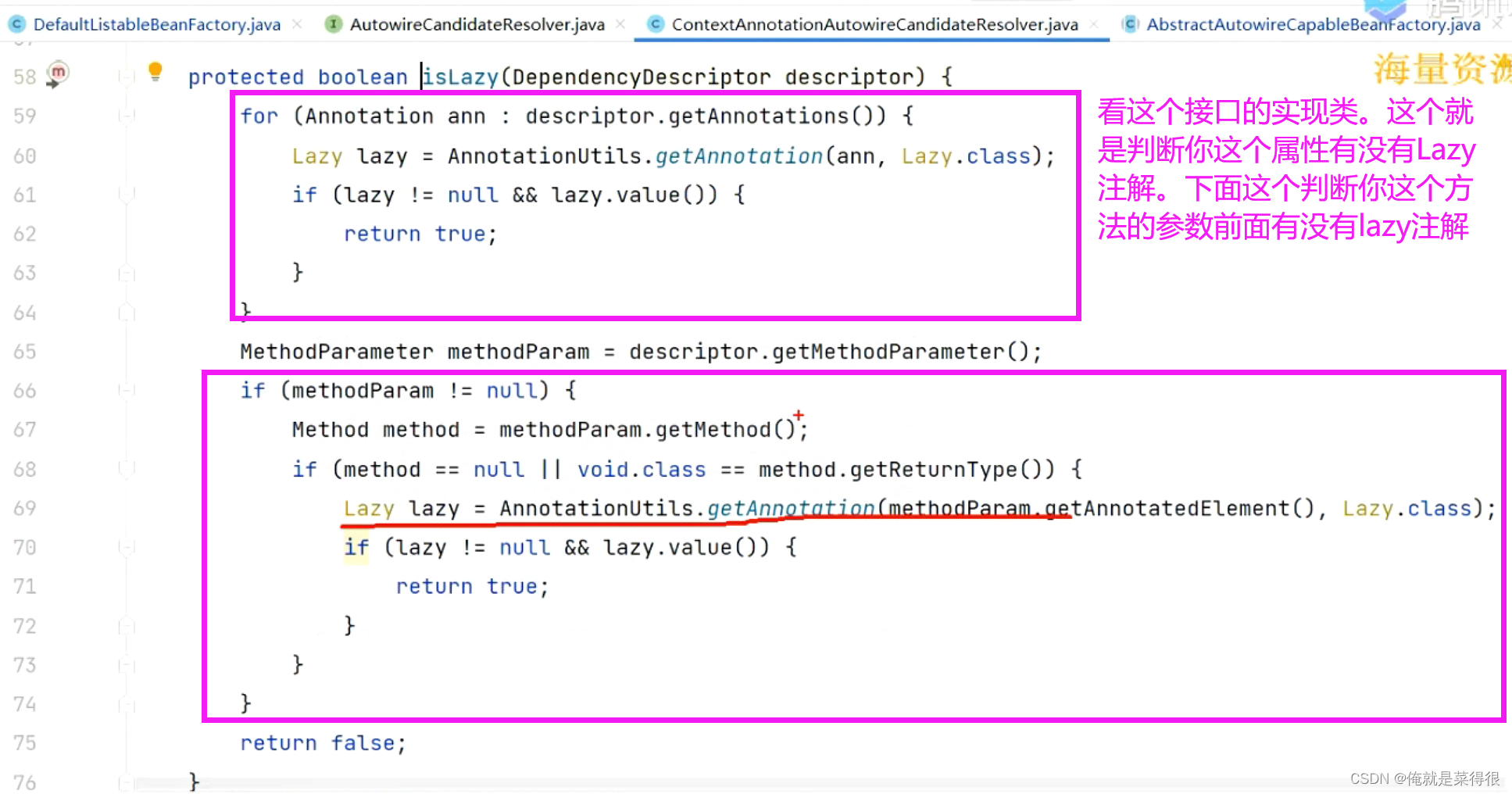
如果有这个注解就返回一个代理对象,没有就返回null。
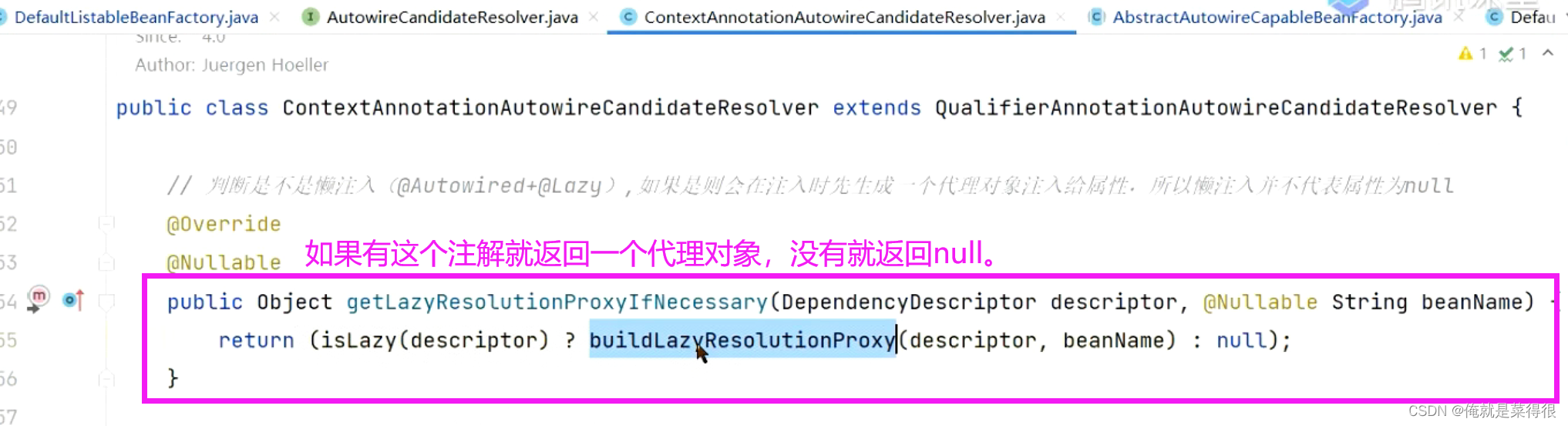
spring开始就会给这个orderService赋值赋的就是一个代理对象,那当使用这个orderService的a方法的时候,底层会怎么做?
首先会来执行这个方法。
我加了Lazy注解,并没有根据orderService的类型、名字去找bean,只是生成一个代理对象赋值给orderService,当我真正去使用他的时候去bean工厂里面根据类型、名字去找bean,再去执行当前正在执行的方法。这就是Lazy的一个效果,延迟嘛。
上面讲的是在字段上加的注解
下面是在一个方法的参数里面加注解
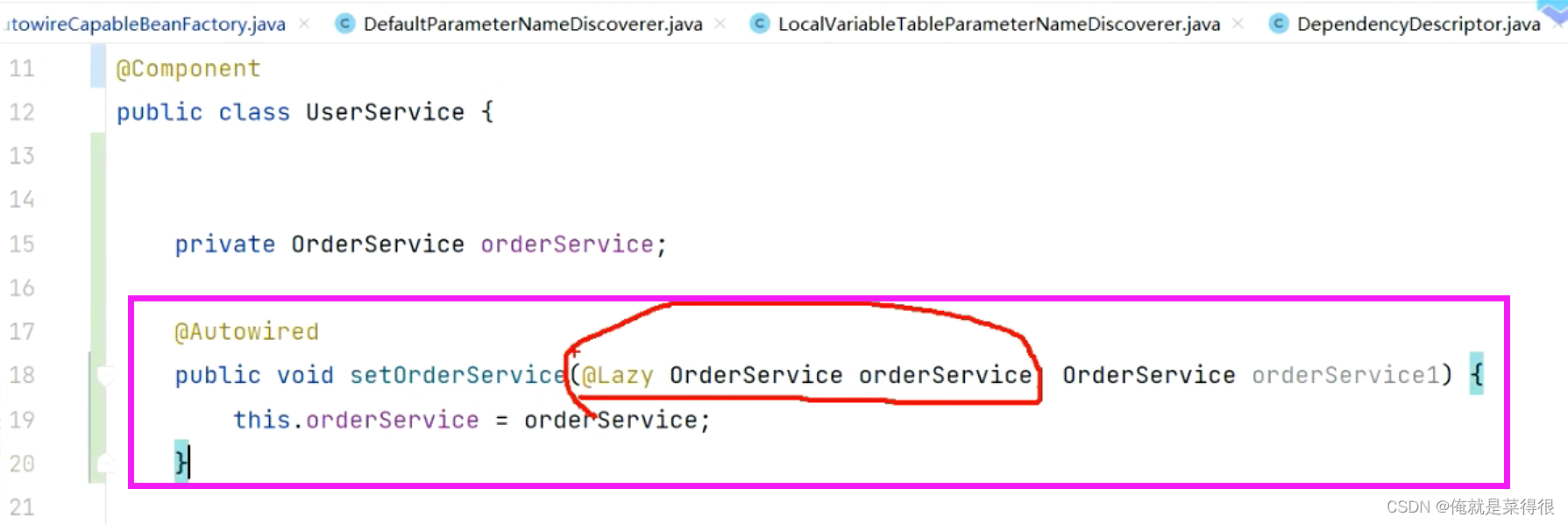
那么这个时候一开始找到的是谁,一开始找到的也是代理对象,也是传给了这个参数。是一样的。
如果没有这个Lazy注解就会进入下面这个方法
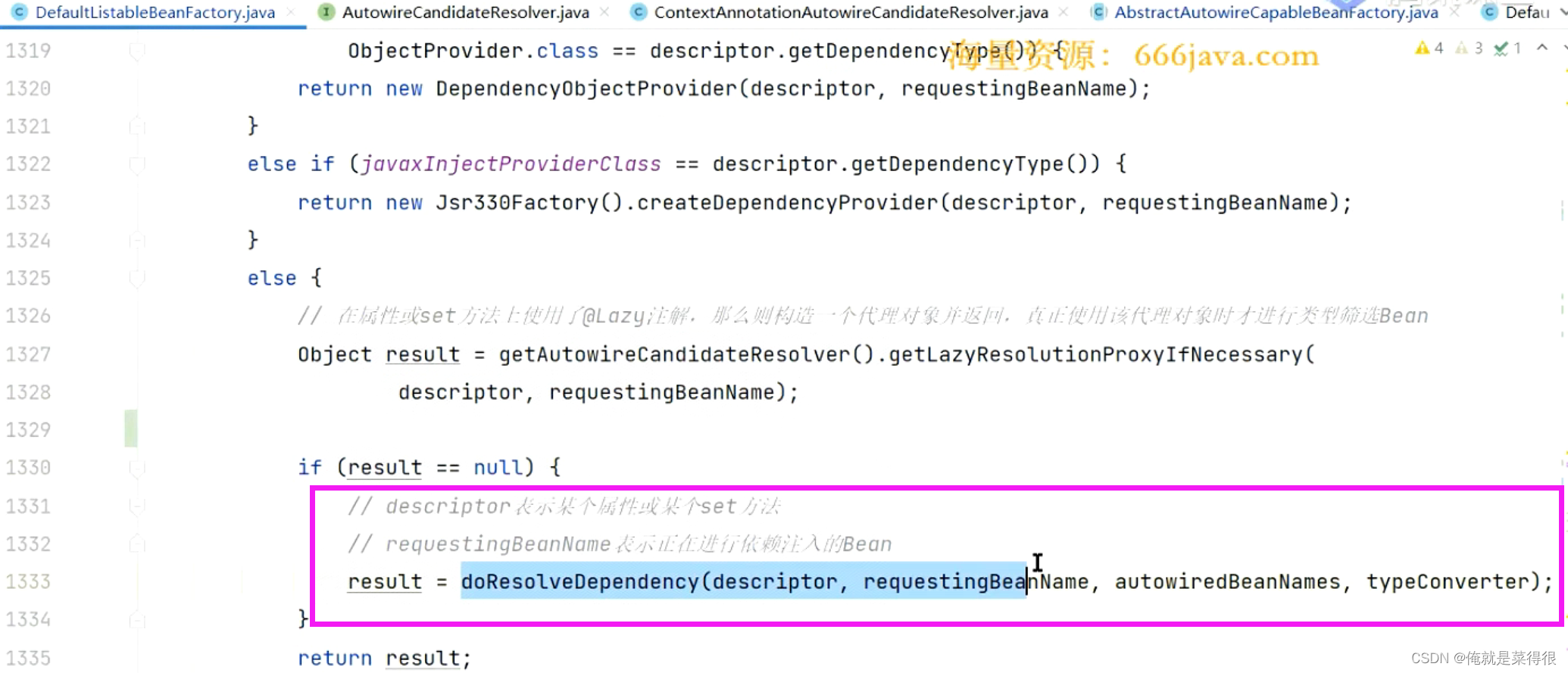
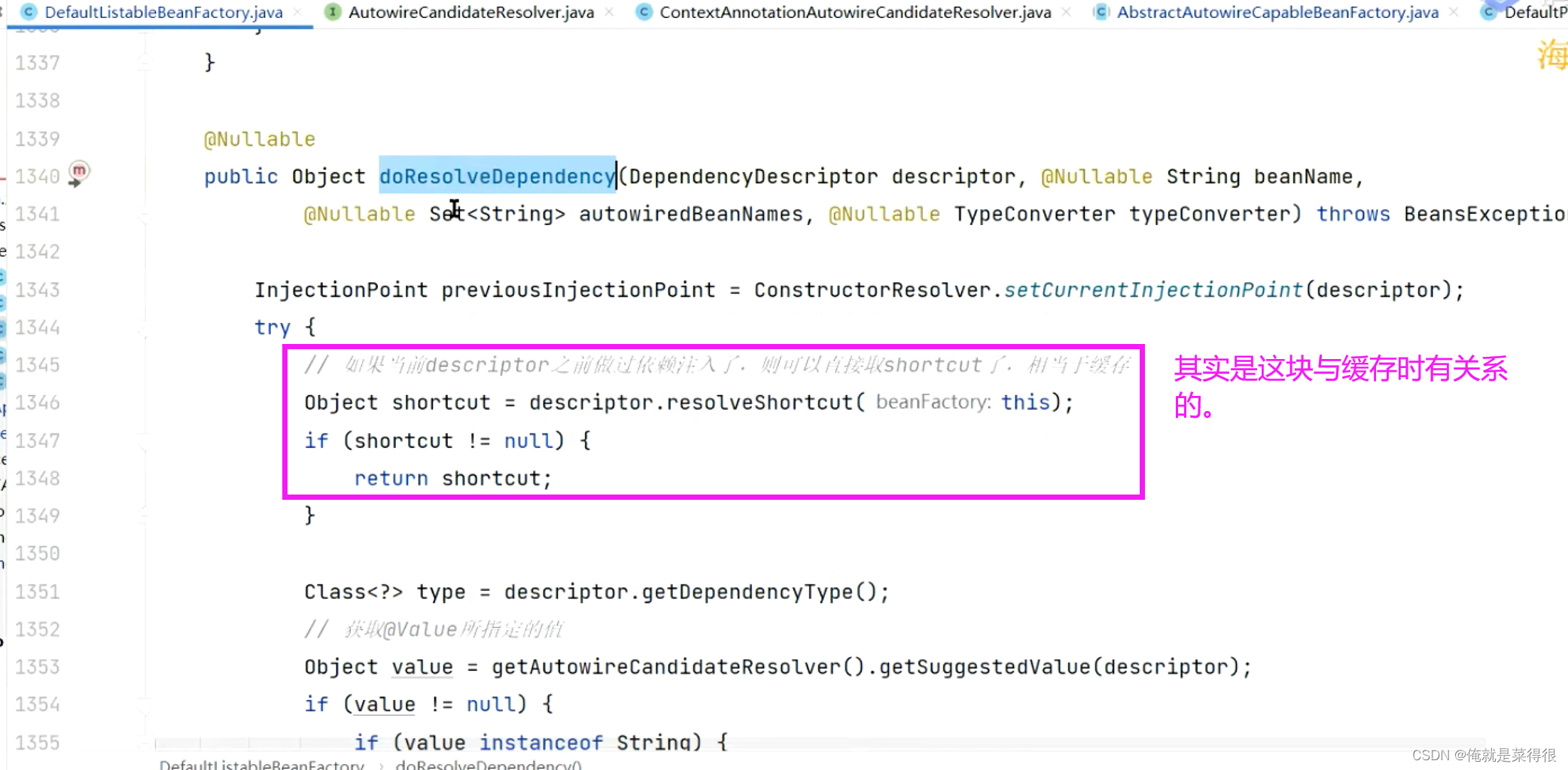
到底是如何找bean的呢?
其实是这块与缓存时有关系的。
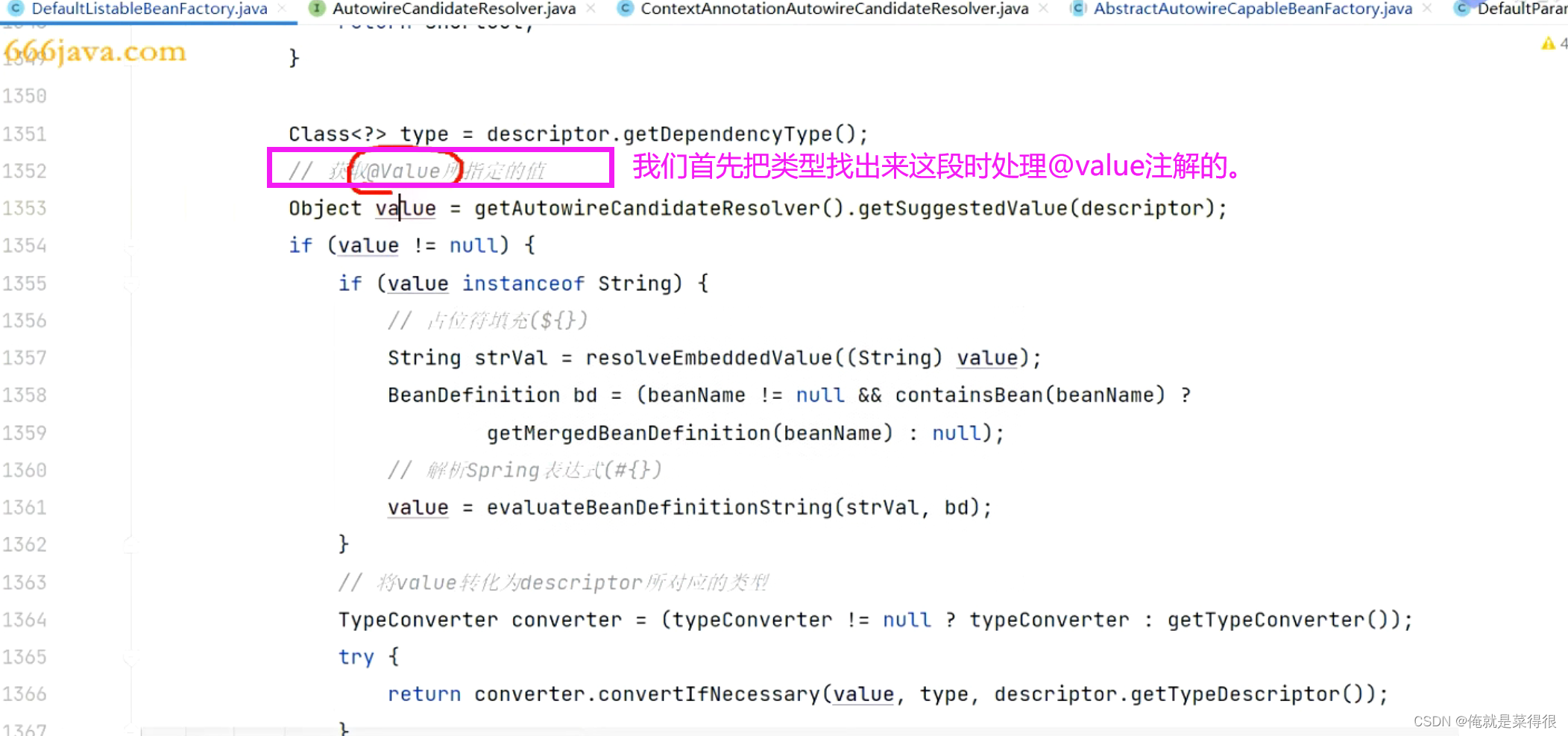
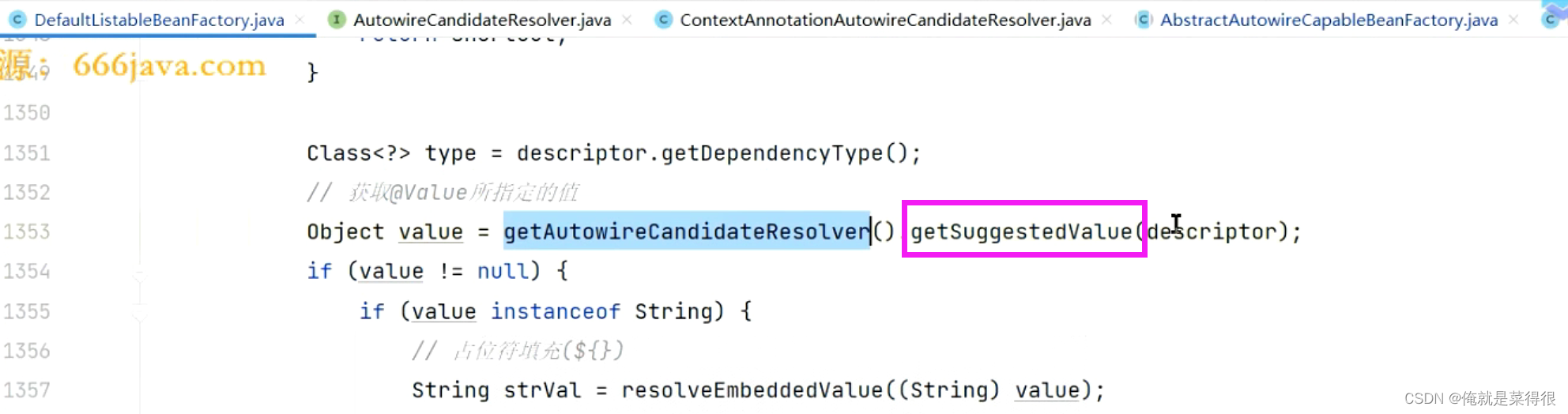
我们首先把类型找出来这段时处理@value注解的。
就是字段前和方法的参数前都可以写@Value注解的
看你当前字段你有没有写@Vaule注解,点进去
看这个接口的实现方法
这个就是为了把@Value中的值给拿到。
按照正常的理解就是把这个值拿到,然后赋值给这个OrderService
============================================================================================
回到最开始看的哪个方法

如果拿到的时String,首先进行占位符的填充,加入写的时@Value(“${ding}”),在spring中有一个Environment,这个包括了properties的内容,首先就要通过注解引进来

其实这个properties里面也就是key、value。Environment还有一些操作系统的环境变量,那里面也是key、value。还有可以通过下面这种方式指定环境变量。
我们所说的占位符的填充就是那你现在拿你指定的@Value(“${ding}”)里面的ding作为key,去Environment找value。
我们现在看一下运行结果,假设我们不写引入spring.properties这个文件。

我们现在注入肯定会报错,因为现在这个@Value(“${zhouyu}”)是一个${zhouyu}的字符串,如果先进行占位符的填充,没有填充到,因为我们现在prperties还没起到作用,我们操作系统里面以及jvm里面都没有zhouyu这个key的value,那么他就要按照字符串的形式赋值给OrderService,但是这个属性的类型是OrderService,是赋值不了的,因为没有类型转化器,会报错,所以先写成String才可以

结果是${zhouyu},是因为他会先去填充,但是有没有东西填充,因为这个properties是没有起作用的。

如果我们把这个properties文件加进去我们就可以看到我们想要的结果。

因为·我们properties这块配置的是XXX

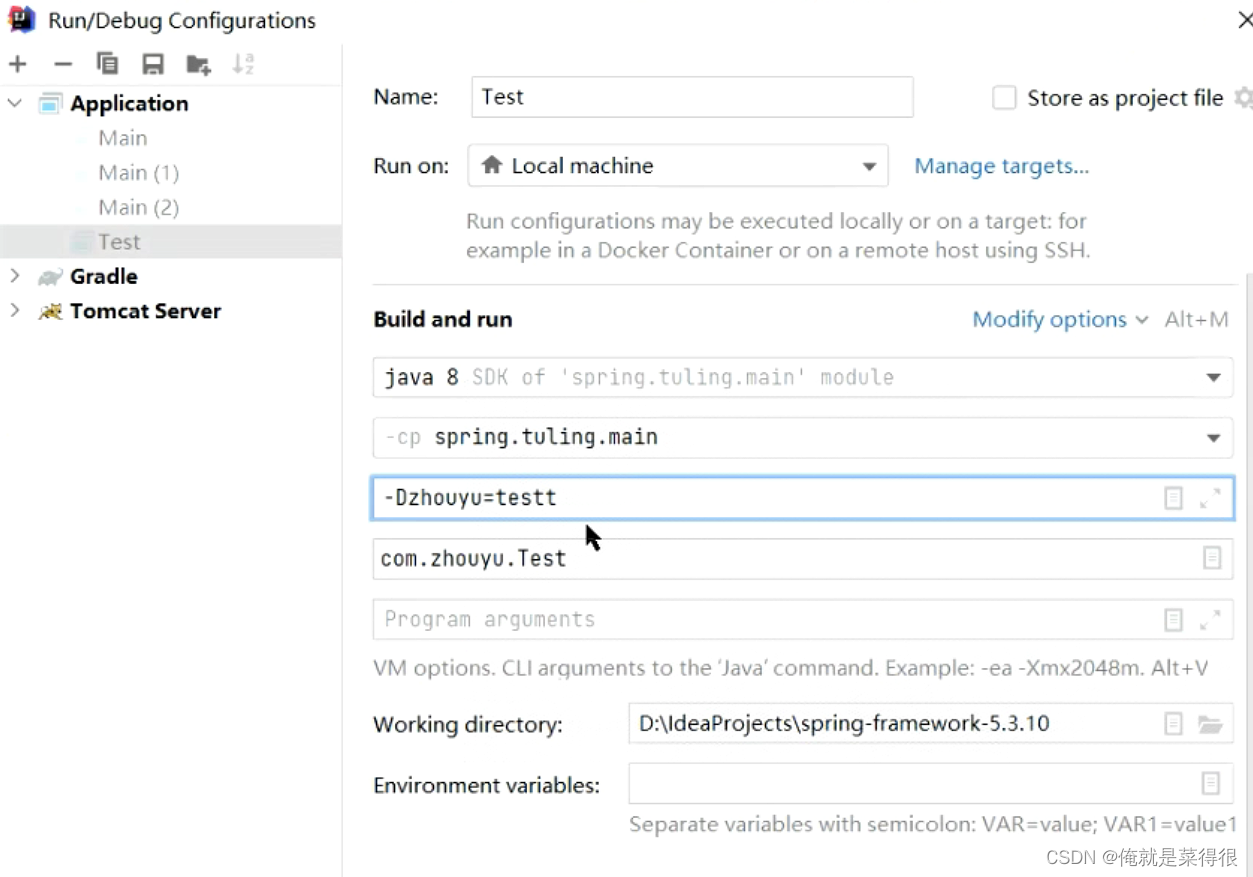
同样我们也可以以这种方式指定一个
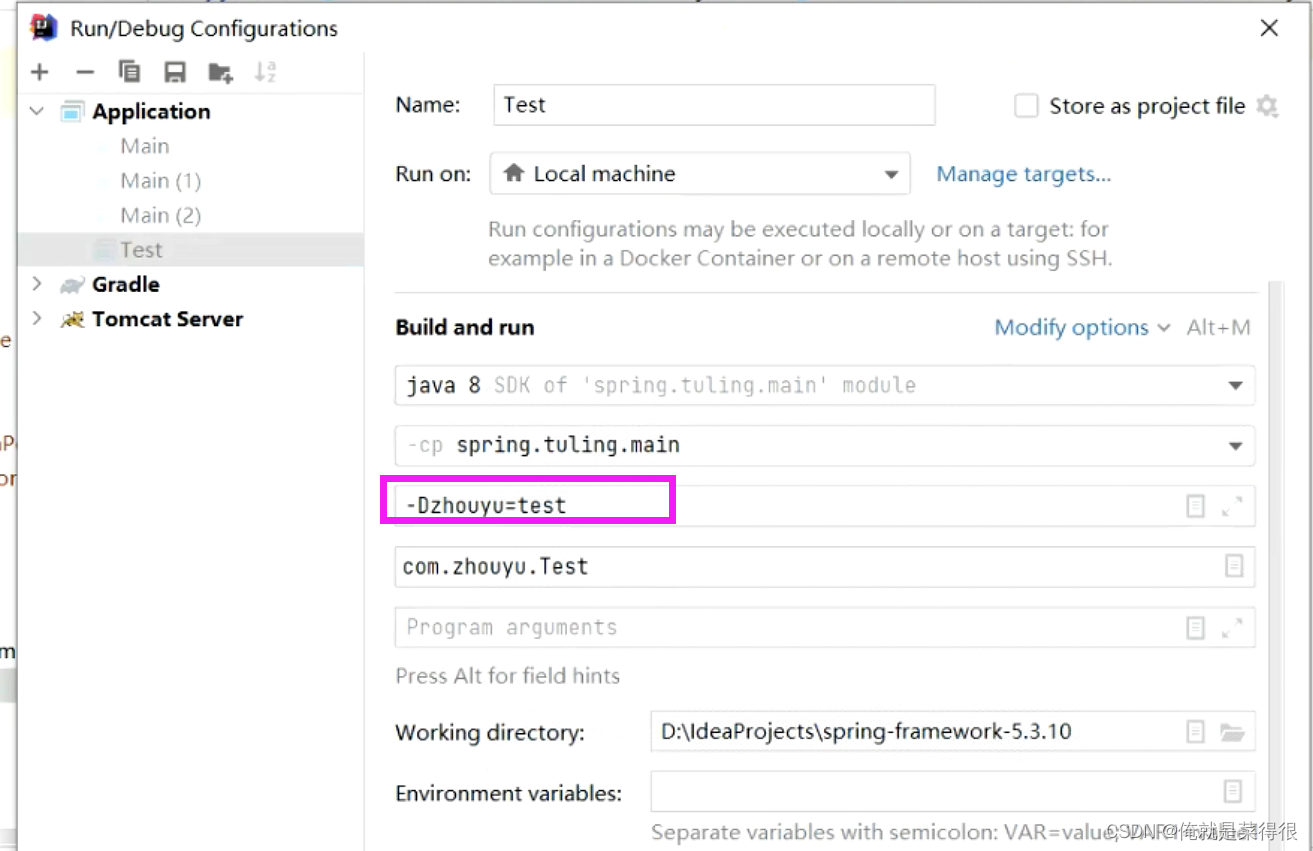
然后这个地方打印出来的结果就是test(前提是那个引入properties的地方先注释掉)

如果两种方式都配置的话,-D的优先级更高。
============================================================================================
占位符的填充之后就会进行spring表达式的解析,我们回到原来的分析的方法中。
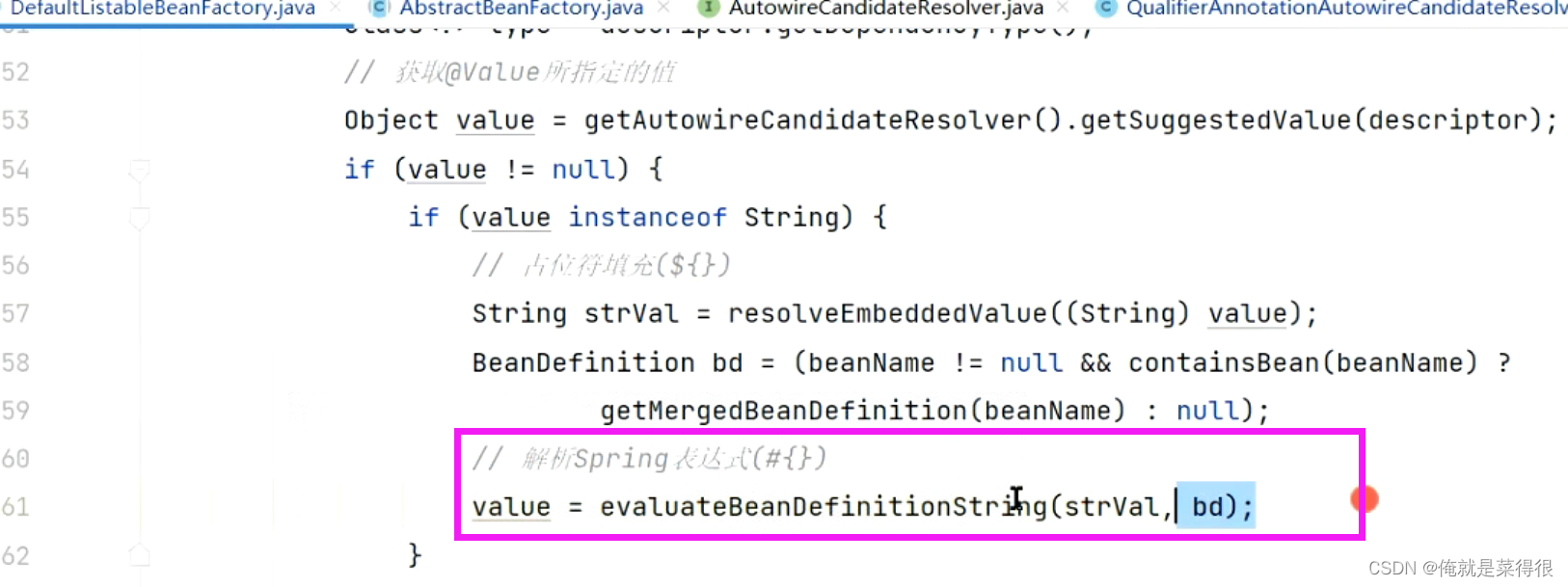
我们可以不写$这个符号,可以写成#这个符号,#这个符号的意思是spring表达式。
这样写的意思是你去spring容器中找叫zhouyu的bean,这里面指的是bean的名字。按照现在这样去运行是会报错的,因为确实没有这个bean
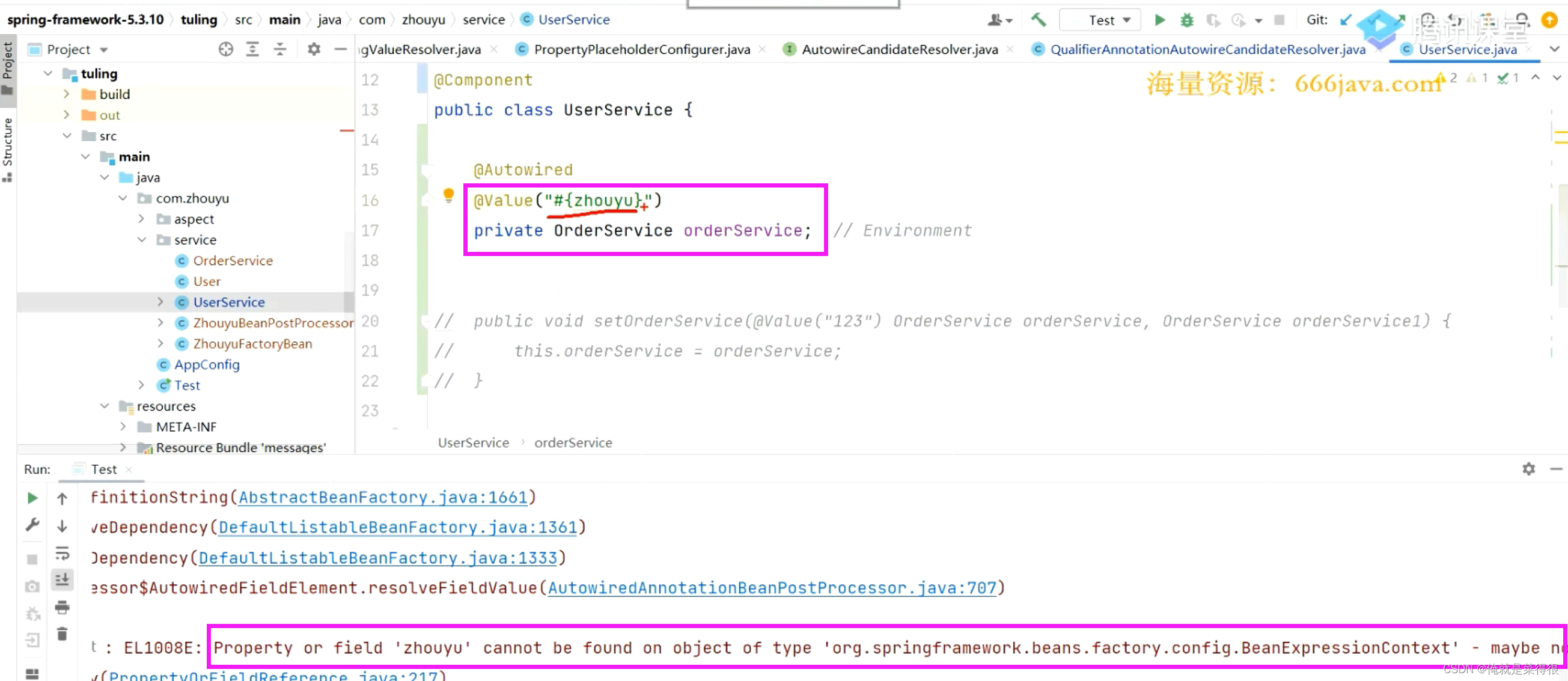
你这样写就不会报错了。
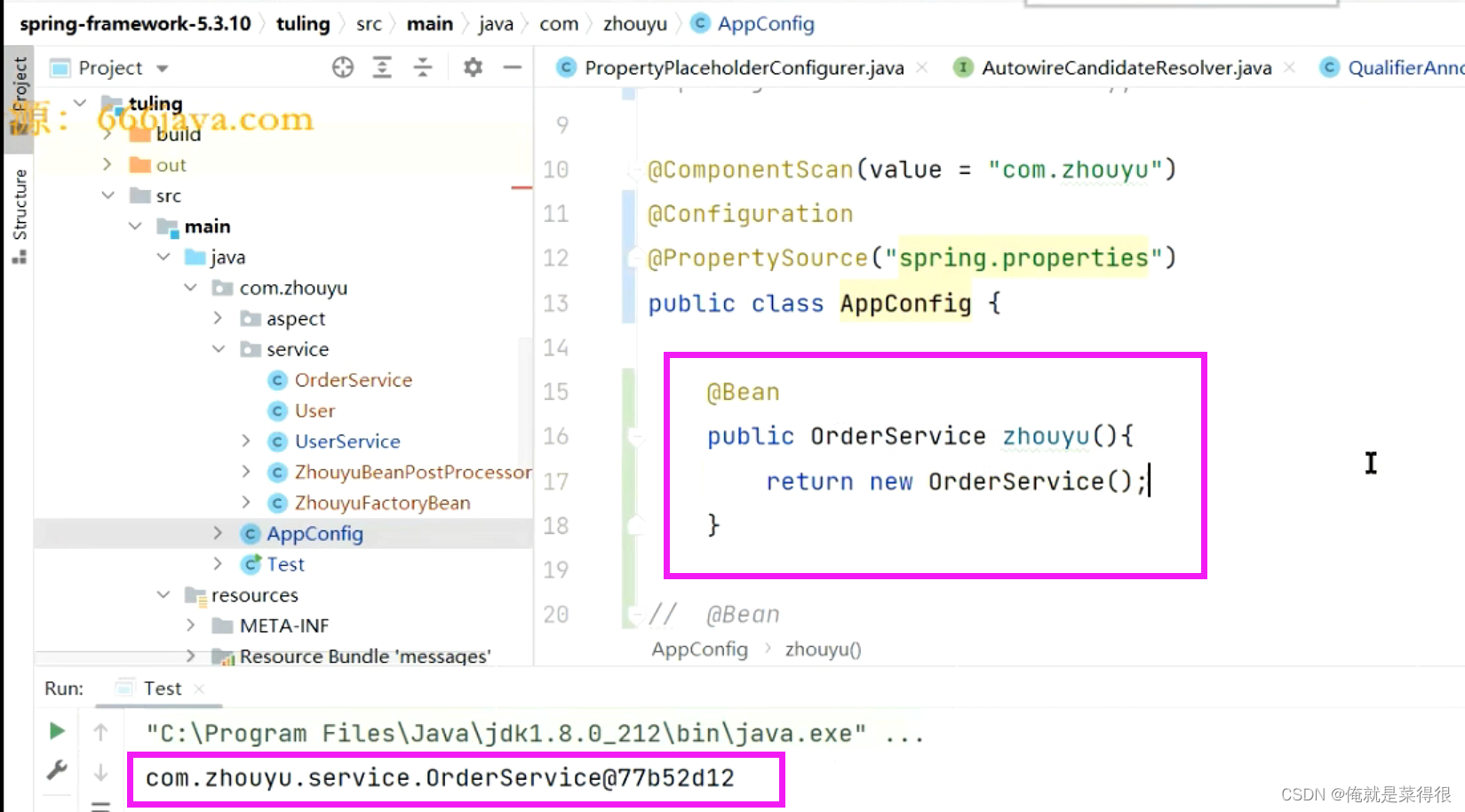
这样就是一个spring表达式了,也是@Value的一个功能。这个地方的源码是很难的,没有必要完全的搞懂。
============================================================================================
类型转换器如果转换成功直接返回,如果没有成功则返回错误。
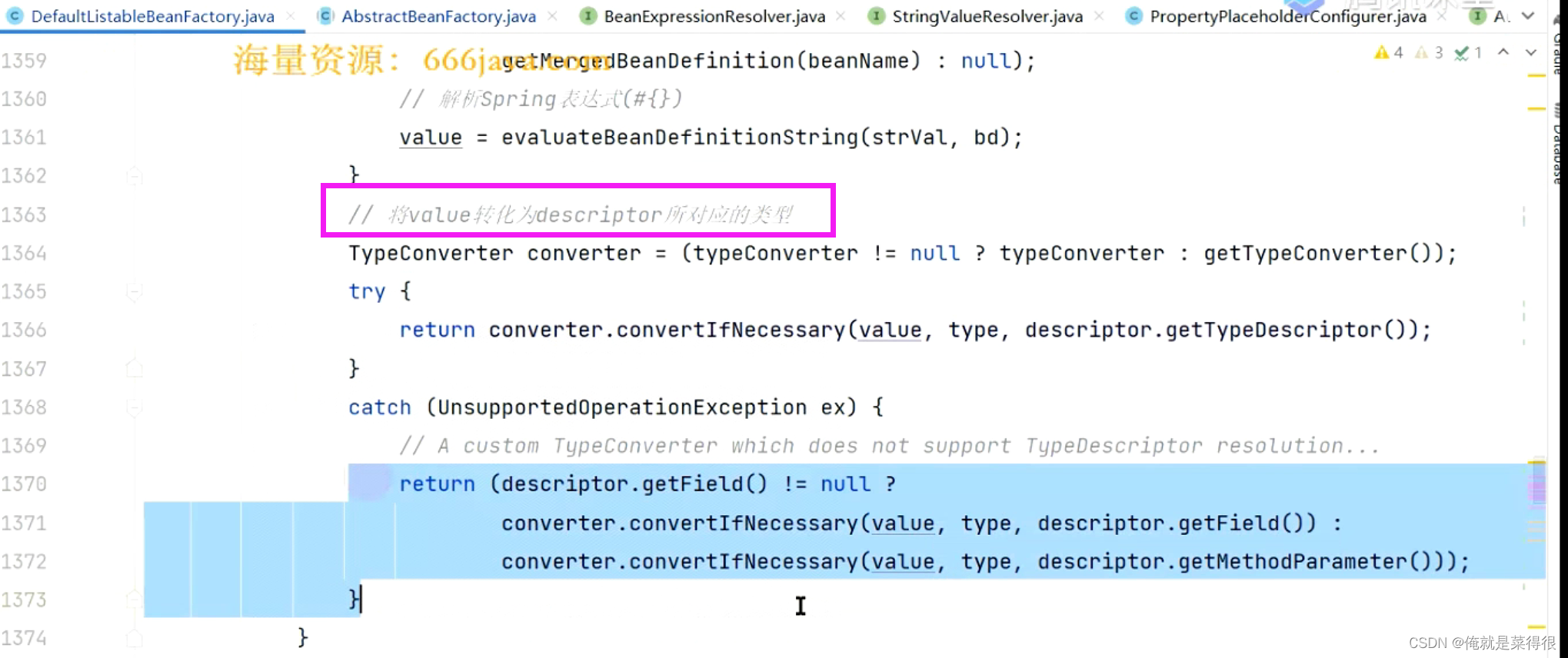
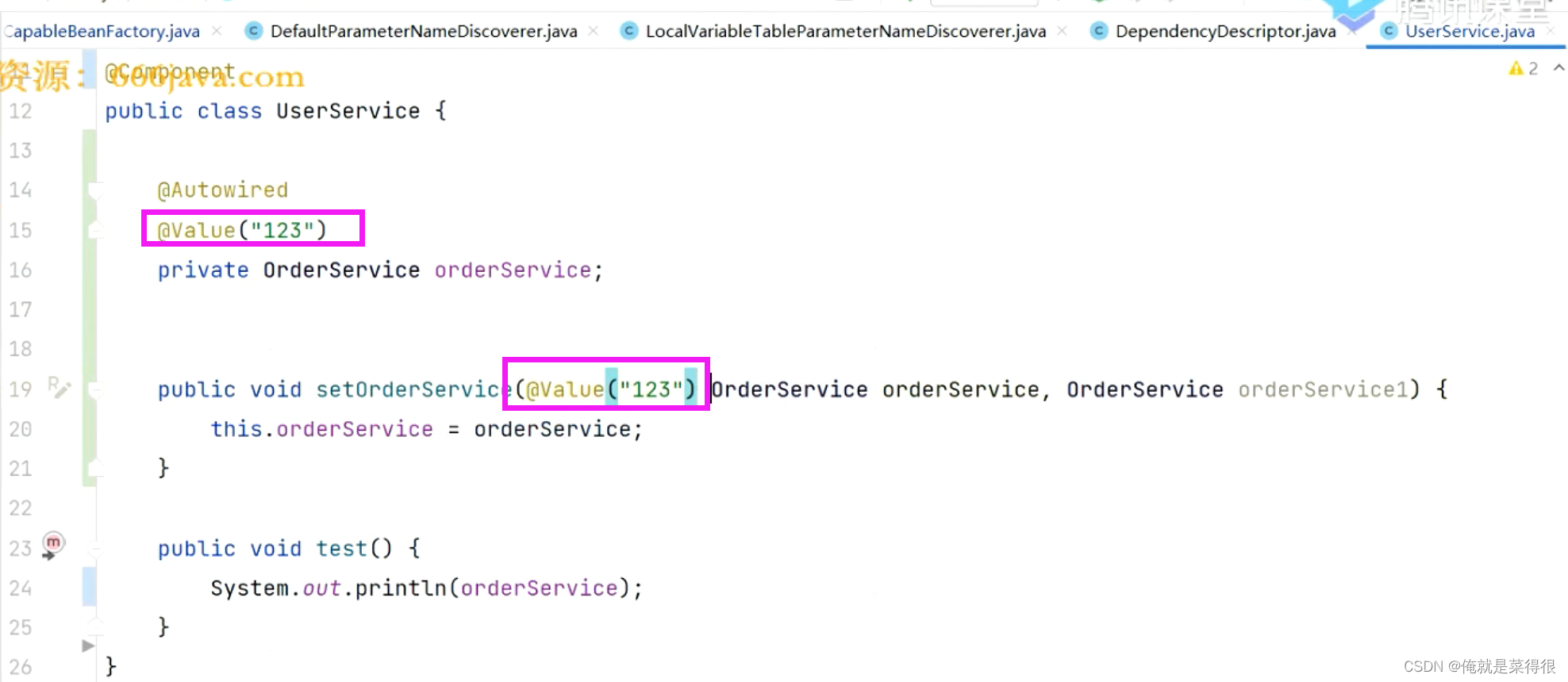
假设我们这什么都没有写,就是一个@Value(“123”)的一个字符串,我们就想把这个123赋值给这个属性,默认情况下肯定是赋值不了的,但是spring有这个类型转换器。只要能有一个类型转换器把123转换成OrderService就可以。

把这个@Autowired注解去掉也是可以的,根据我们上一节课的分析,只要属性上有@Value、@Inject、@Autowired注解中得任一个就会认为是一个注入点。
============================================================================================
接下来我们继续看,如果就是最普通得情况上面什么也没有写。

又是如何去找bean的。现根据类型去找bean,就是这个Orderservice,如果找到多个再根据名字找。假设我们这样写的。

我们看一下有几个Orderservice的bean。
第一个:
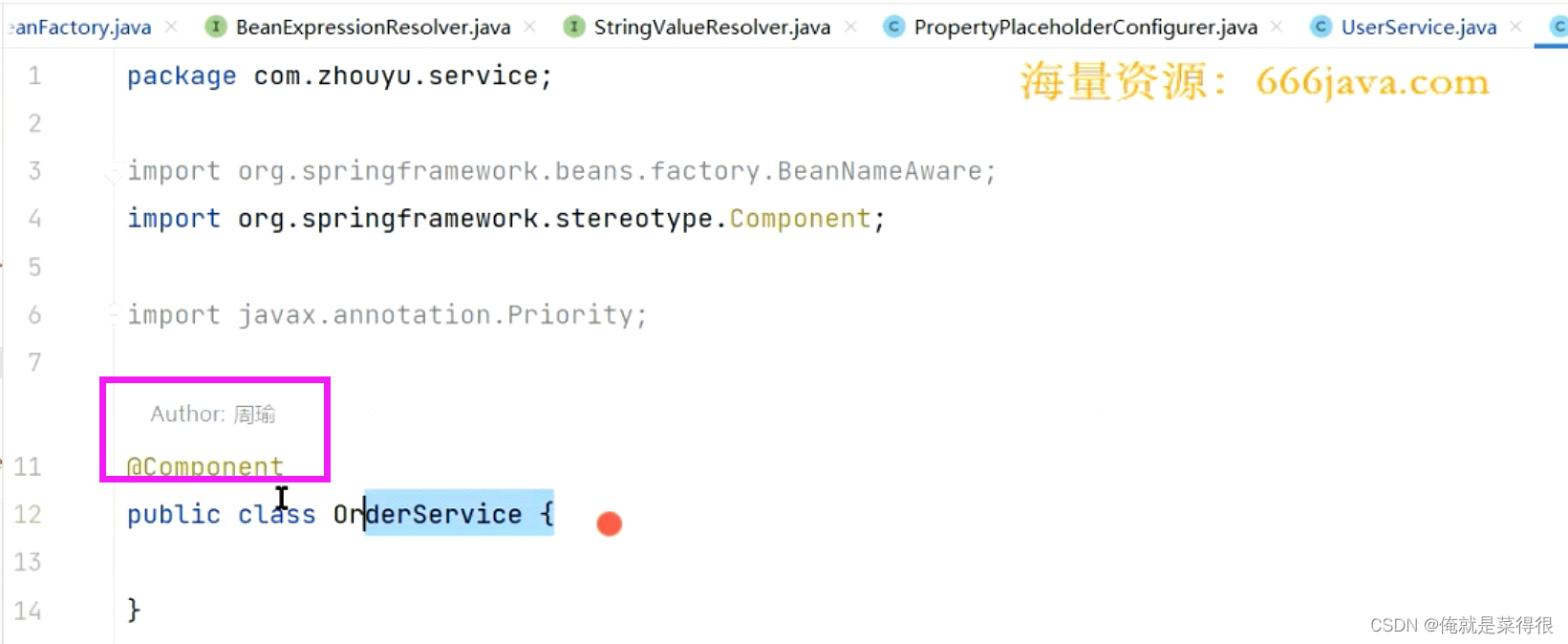
第二个:
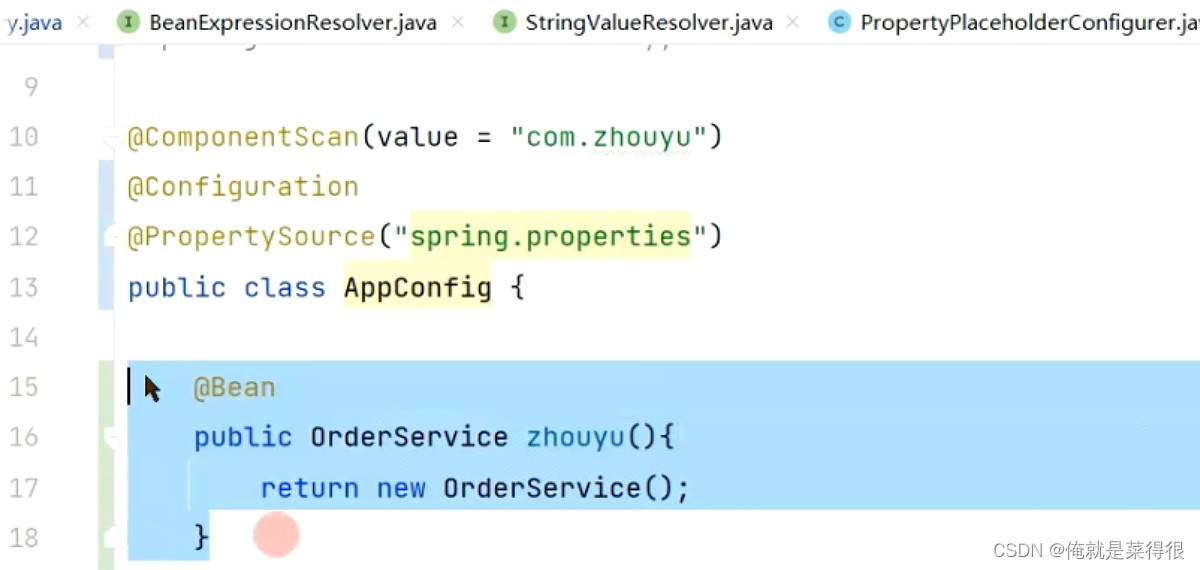
现在spring容器里应该是又两个OrderService的bean的。
我们现在这样写运行代码结果是没有任何问题的。

你这个地方写一个List是一样的效果。

以上两种方式的意思是我把所有的OrderService的bean都找出来。赋值给这个Map,key就是每一个map的bean,value就是对应的bean对象。
我们看一下源码:
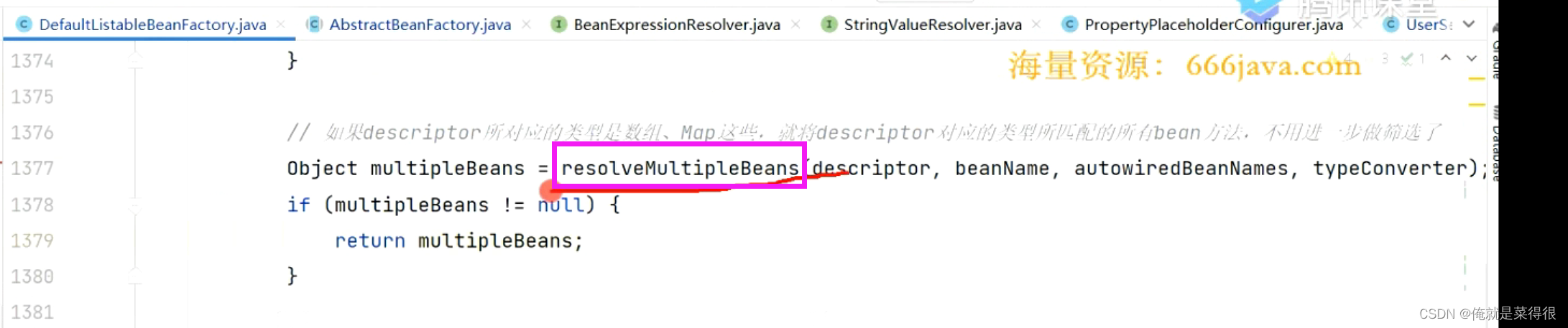
如果是Map,就把Map里的key找出来,如果key的类型不是string就返回null,你的key一定的要是string类型。也会把value的值找出来。
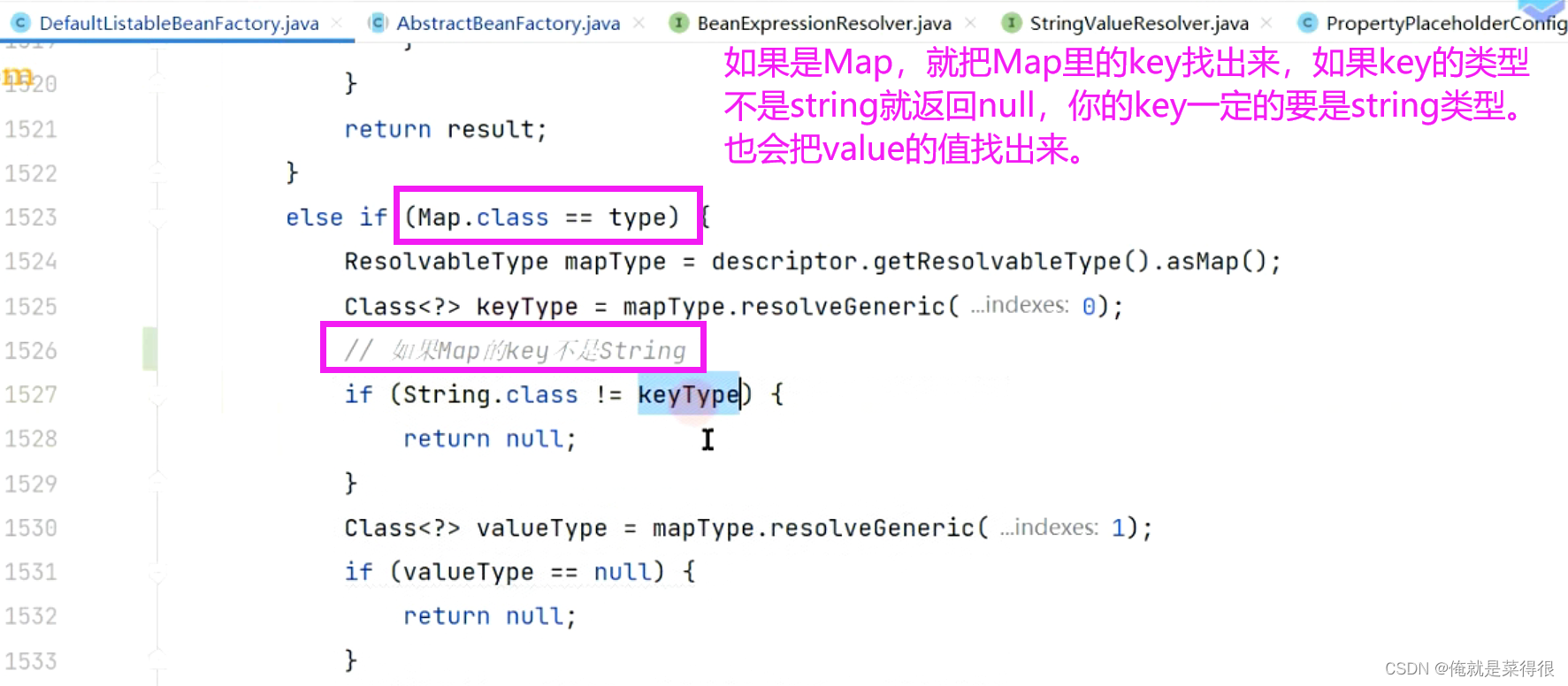
这个方法是真真正正的根据类型去找bean,把bean的名字以及符合这个bean的对象返回出来,然后最终返回。
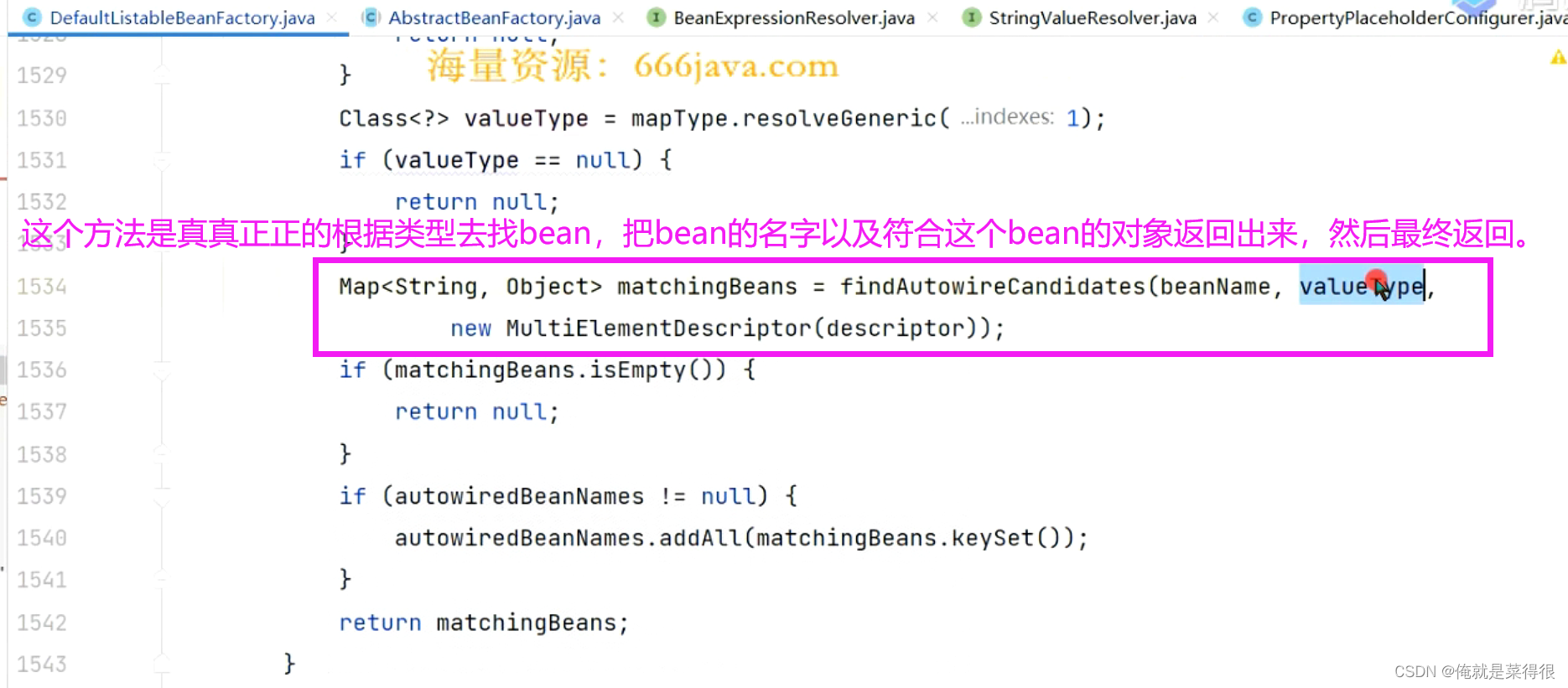
加入是泛型呢?要知道这个泛型最后显示的是Object。其实最后展示的就是所有的bean,
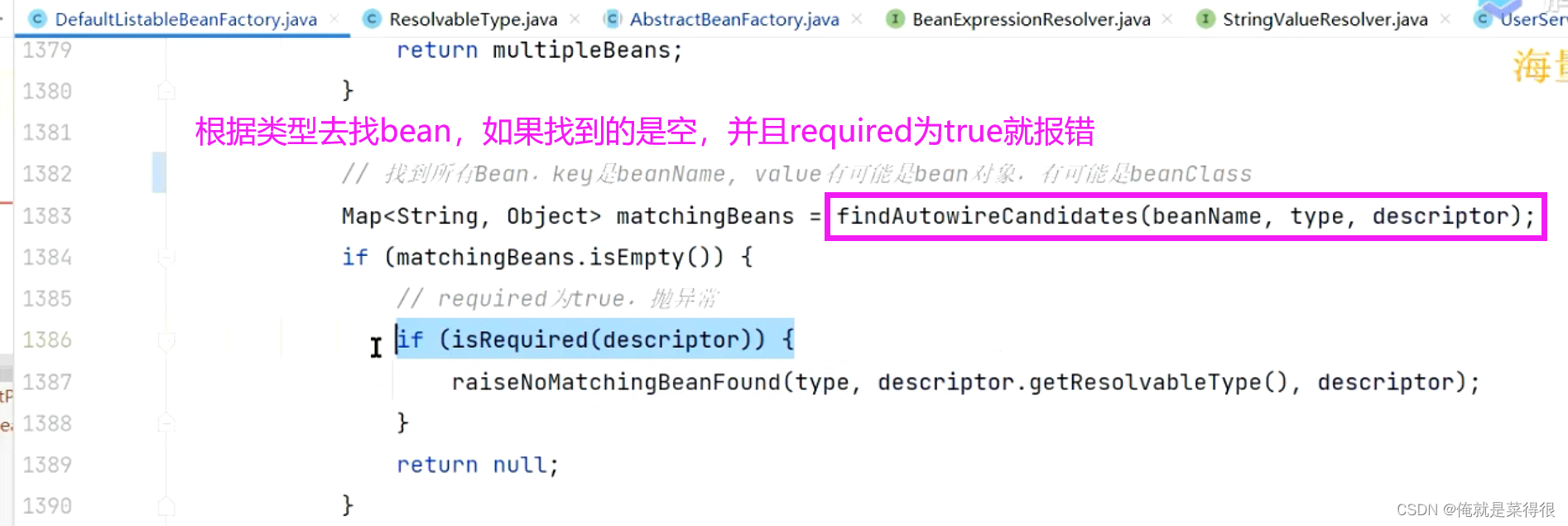
但是由于之前讲的@Autowired有一个required这个属性默认是true,如果没有相应的bean就会报错。

如果把把泛型改成Object。其实最后展示的就是所有的bean。
最后的结果是:

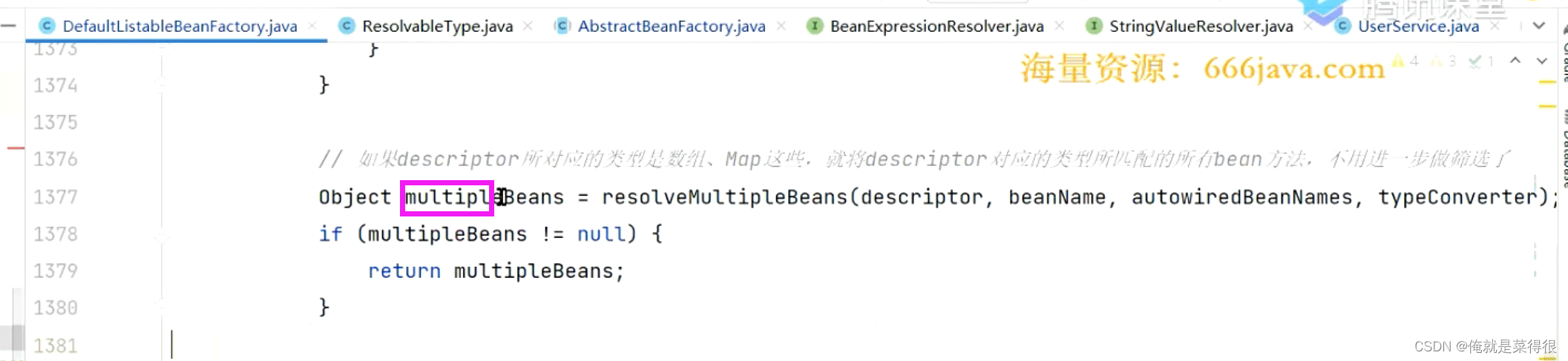
如果我们写不是Map、List等这种复合的类型的,我们就直接返回。
================================================================================
如果是普通的类型,不是List、Map、之类的。
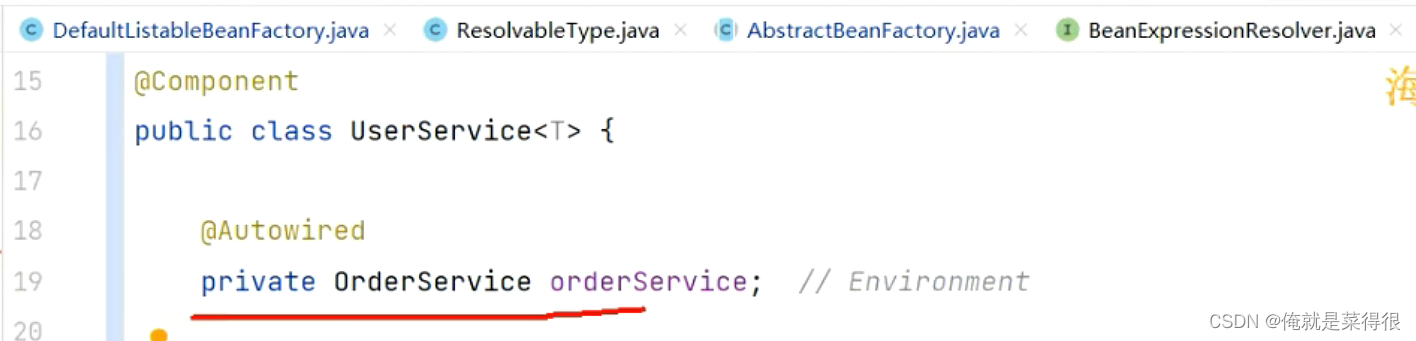
根据类型找bean。找到的bean中Map里面string是名字,Object不一定是bean对象,有可能是class
如果我们找到了多个bean
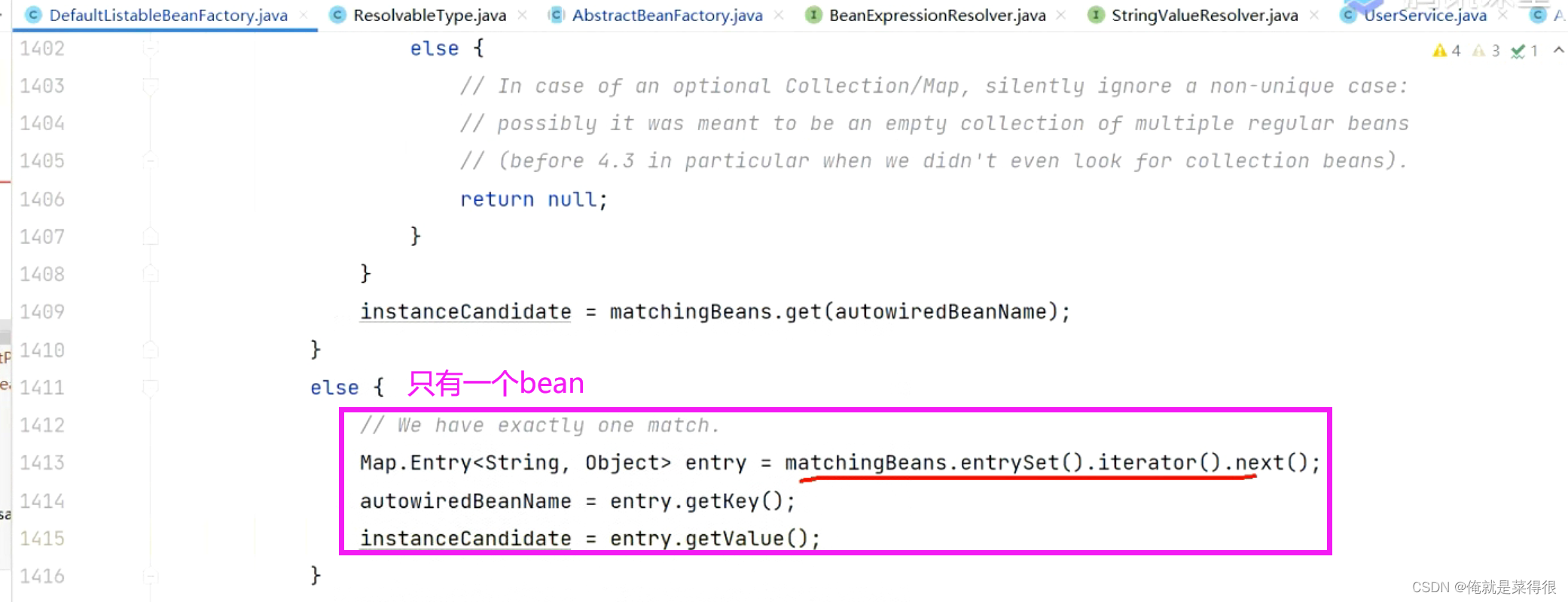
只有一个bean
============================================================================================
然后我们看找到多个bean的情况。
先根据类型找,找到了多个bean,进一步进行过滤,根据名字找。
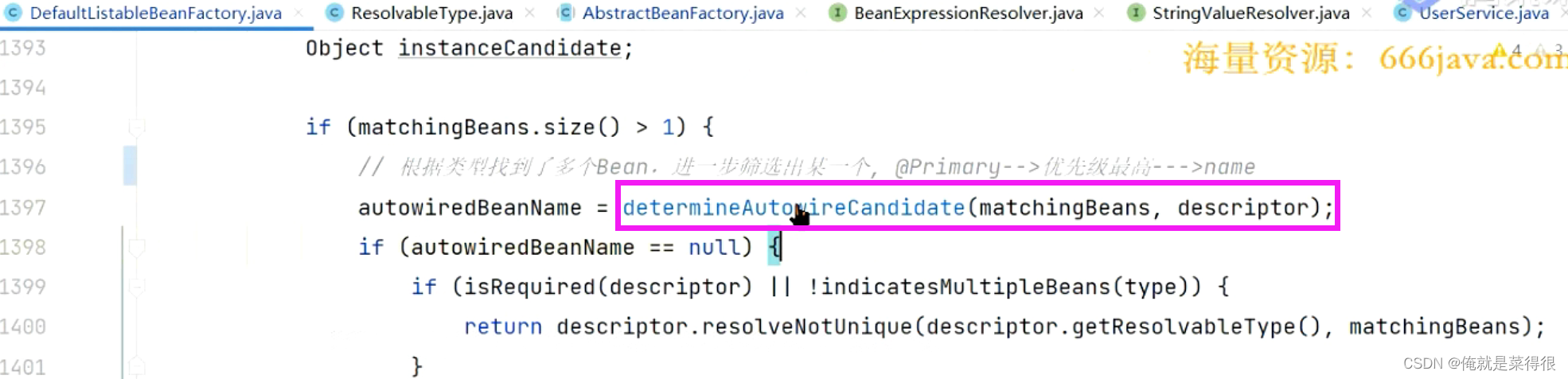
把多个名字拿出来判断。
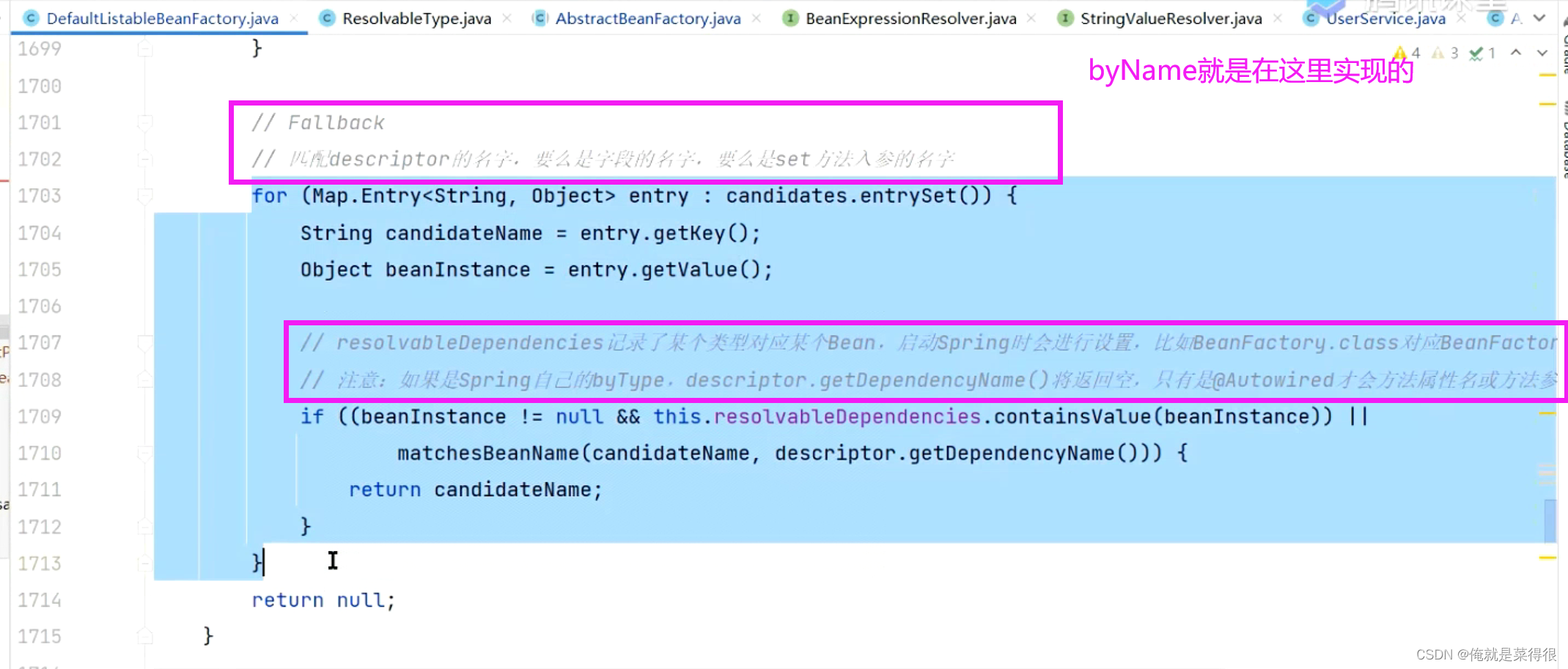
但是在进行名字判断还有一些其他的判断。
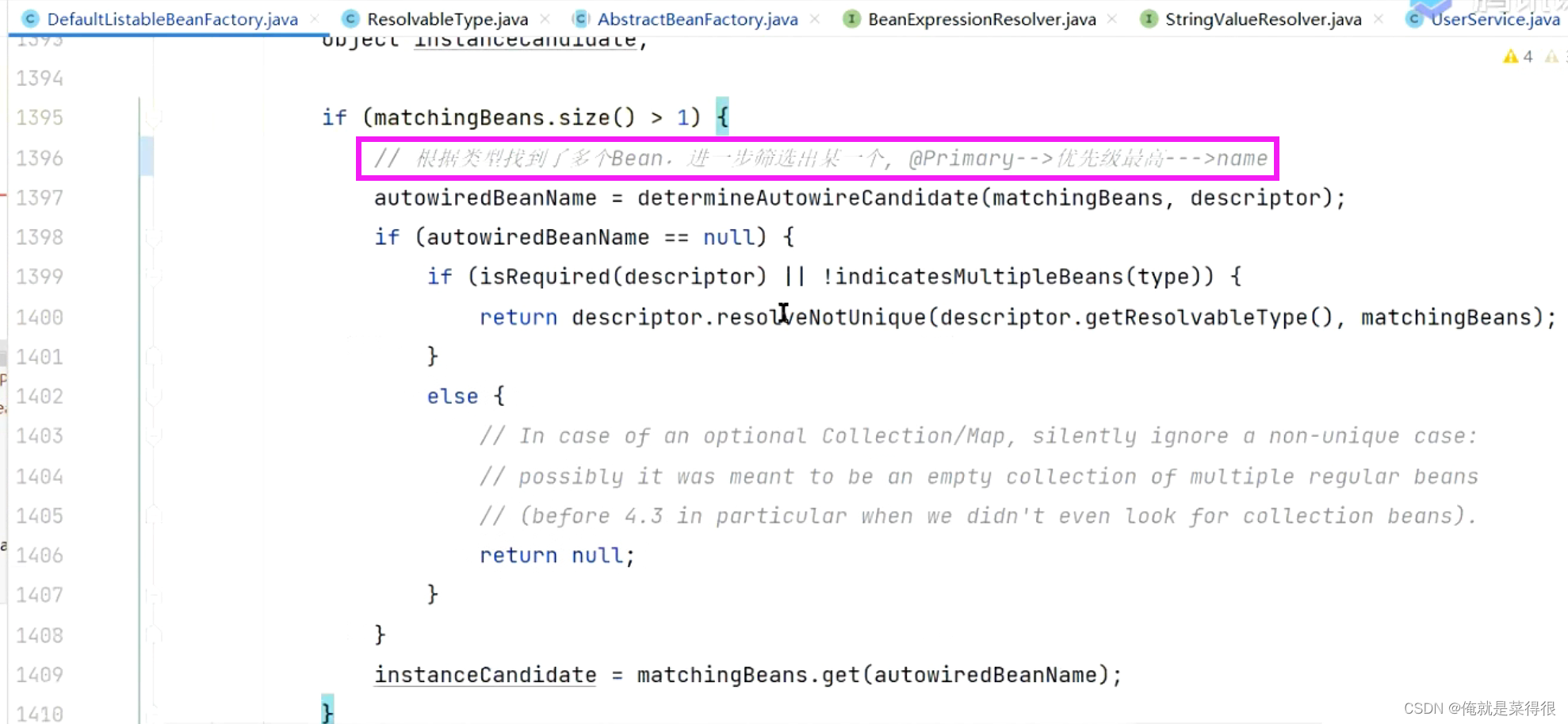
我们现在根据OrderService这个类型去找,容器里面我们有两个。先找这两个bean上面有没有primary注解。如果多个bean加了primary注解就报错,抛异常。
除此之外,我们还可以定义优先级。利用Priority注解。这个注解有一个不好的地方就是不能写在方法上面,只能写在类上。不然就报错。
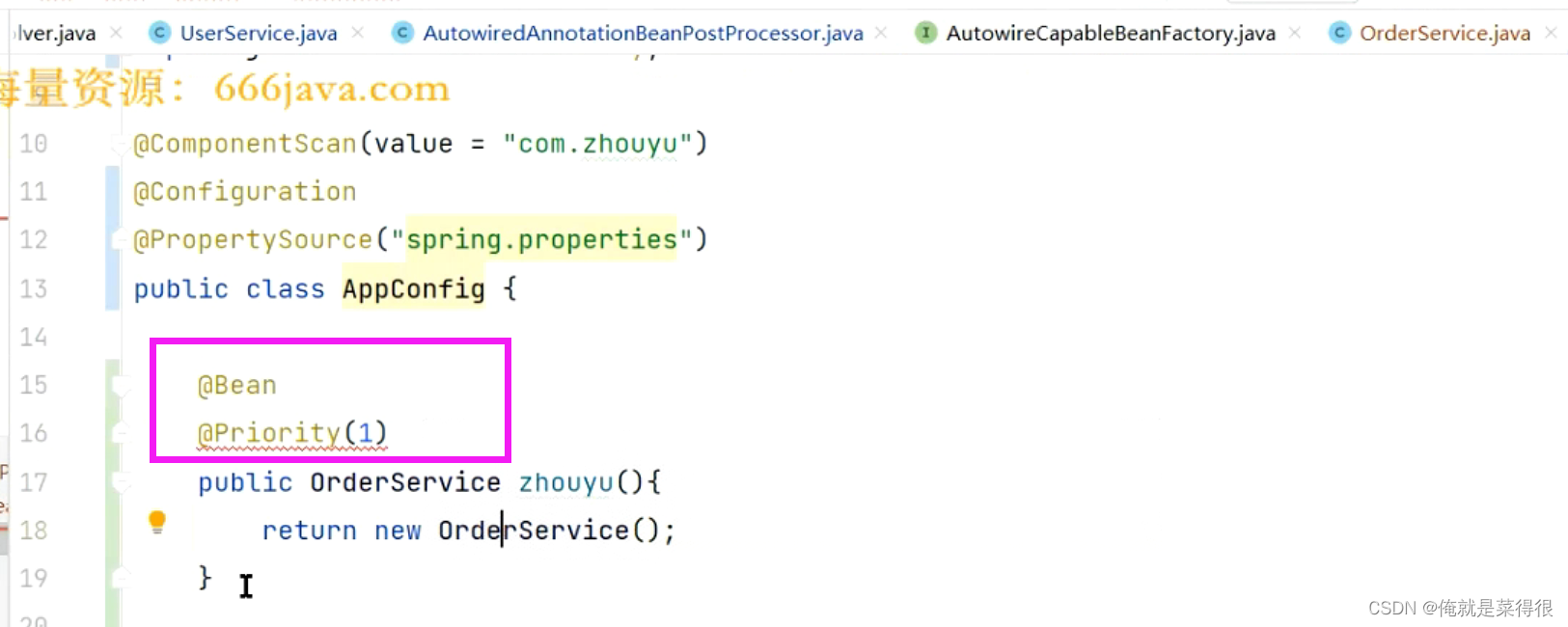
为达到以上效果,我们可以重新写一下,改一改原来的代码使得这个容器里面有两个bean的这种情况。
①、先创建一个interface接口

②、先来实现一个这个接口

③、再来实现一下

④、那么这个时候我们根据OrderInterface去找bean,就能找到两个。
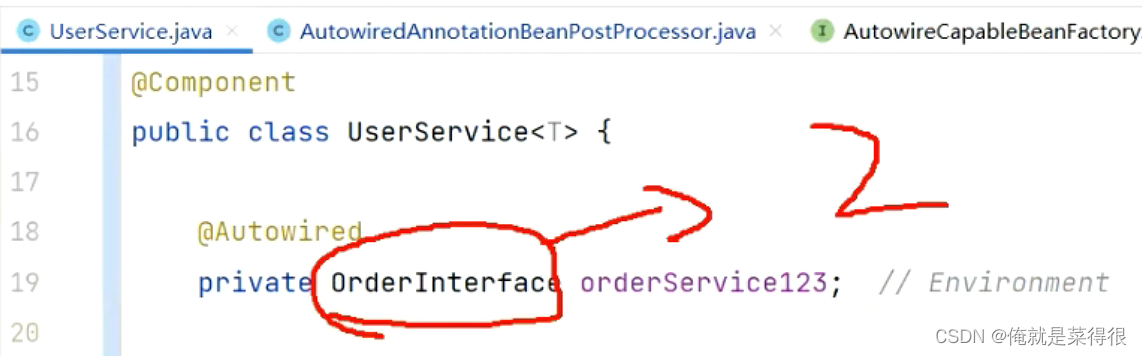
⑤、那么此刻根据名字来找肯定是找不到的,因为有两个,不知道是哪一个就会报错。

⑥、如果在上面加上Primary就不会报错了。
⑦、还有一种数字越小优先级越高,就是Primary后面可以加上“(数字)”。
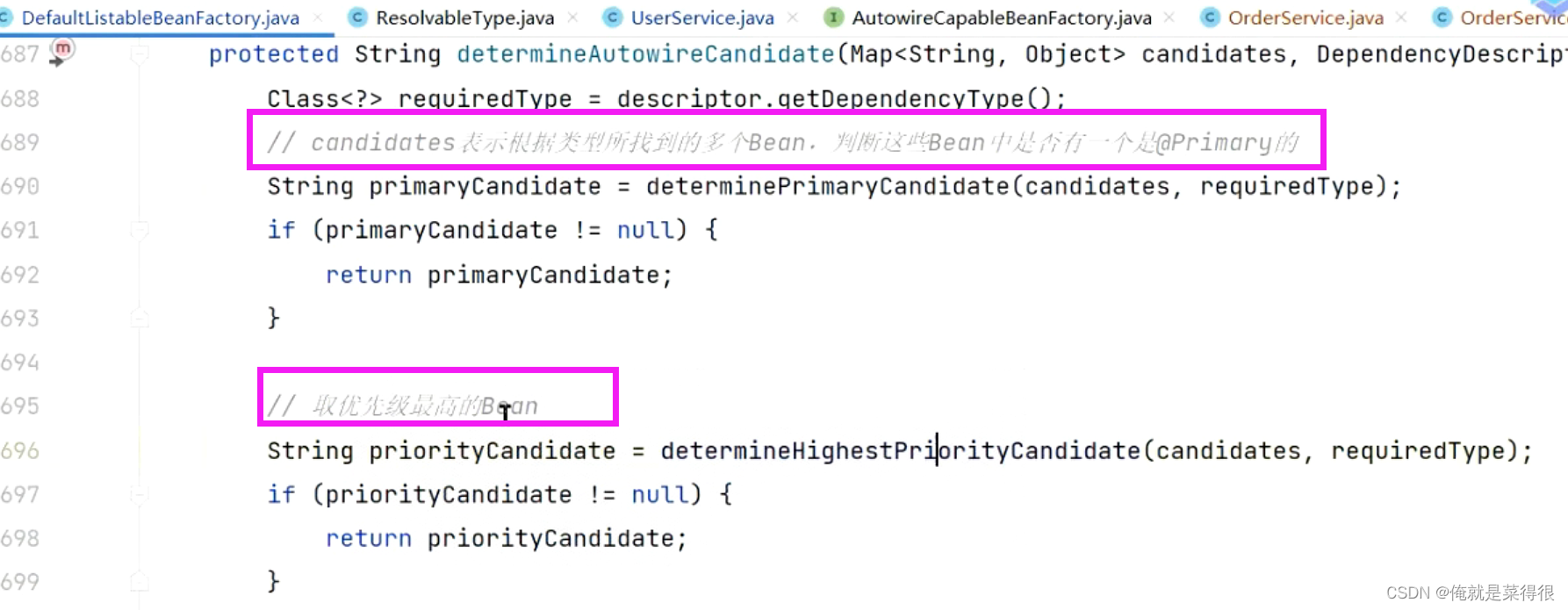
回到原来的方法,在这块就是判断优先级的一个过程。

============================================================================================
我们回到最原始的地方,

开始的时候会根据类型找到多个bean,然后看是否存在primary,

如果存在看看优先级,取优先级最高的。
如果上面这个图里面的两步骤都没有,才会根据名字去判断的。
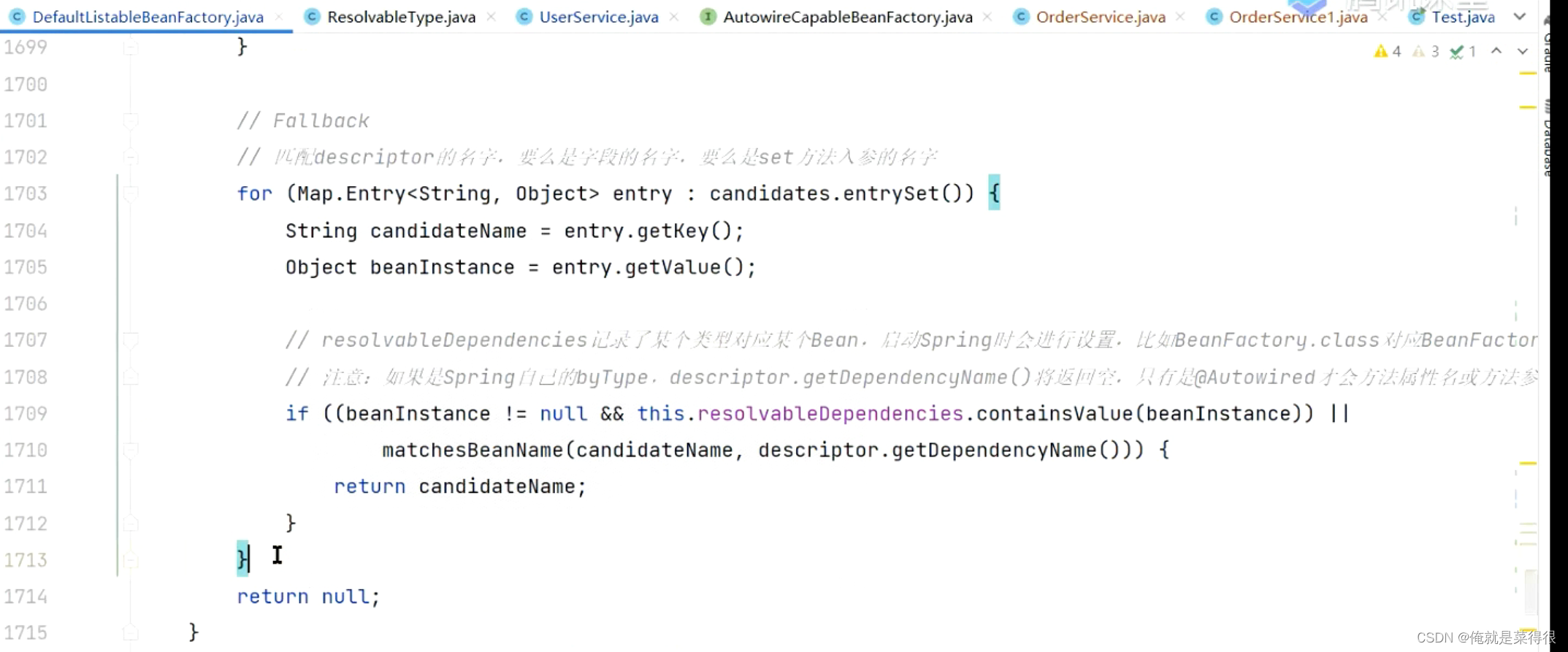
============================================================================================
我们再来看一下为什么那个Map里面那个value的object返回的不是bean而是class的情况。
当我们根据OrderService去找的时候,找到了两个bean与其匹配。如果我们最终找到的是OrderService,那这个OrderService1有没有必要在我目前属性注入的时候创建bean对象。意思就是我根据这个类型去找和我当前匹配的类型有哪些,并不是要把所有的bean对象都实例化出来,因为这两个类型都是OrderService,有可能我们只需要两个中的一个啊,另外一个最起码我在给这个属性赋值的时候我不需要OrderService1创建出来一个对象。因为你创建出来,我又用不到。
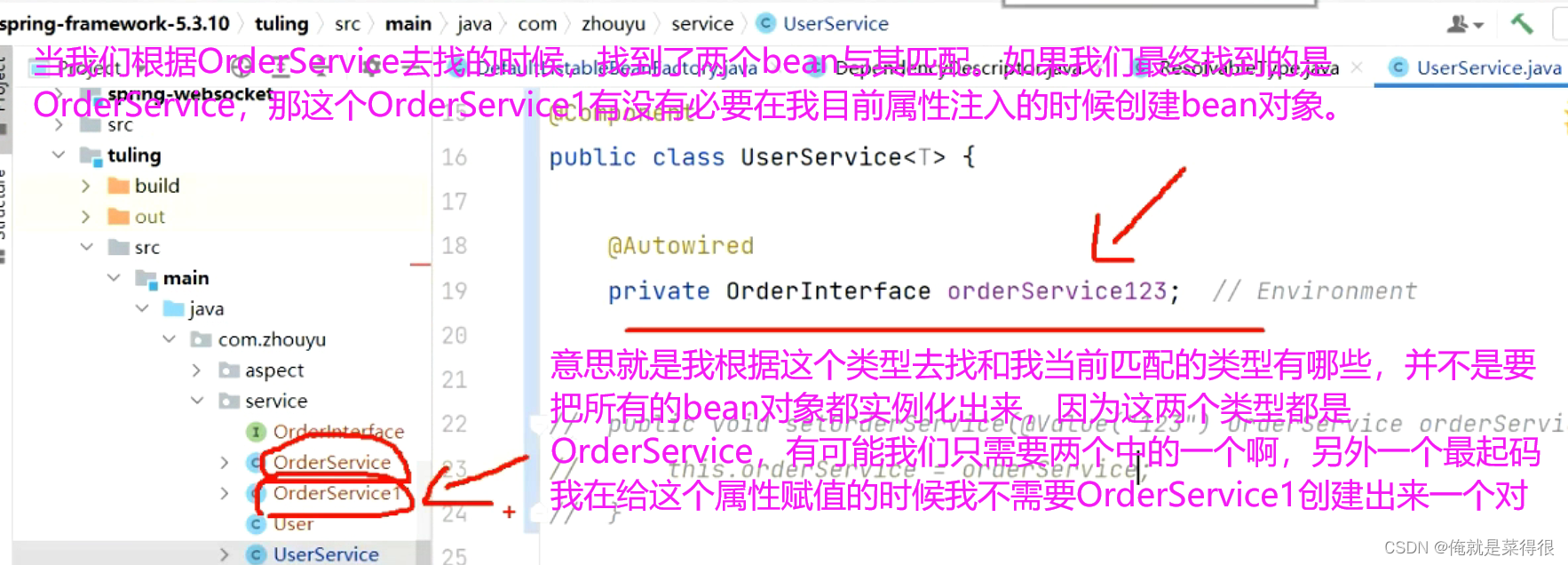
在根据类型找的时候这个Map里面key肯定是bean的名字,那他的value,如果我先遍历OrderService,如果你已经创建好一个对象了,那直接把这个对象当作value,如果你还没有创建好,我可以根据你这个bean的beanDefinition判断出来你的type和我的是不是匹配的,我只需要把你的class存进来就好了,这个value就是class。
去BeanFactory里面根据某一个类型去找bean的时候,不是非得把所有的bean都创建好了才能知道你的类型和当前要找的类型是不是匹配的,我们根据你这个bean的BeanDefinition记录的类型判断就可以。
总之就是你这个bean创建好了,这个value就是你的bean,如果没有创建好。就是你这个OrderService的class。
最终还是要进行判断的,这个时候如果判断出来是class,是因为需要把这个value值赋值给属性的,是需要进行创建的。
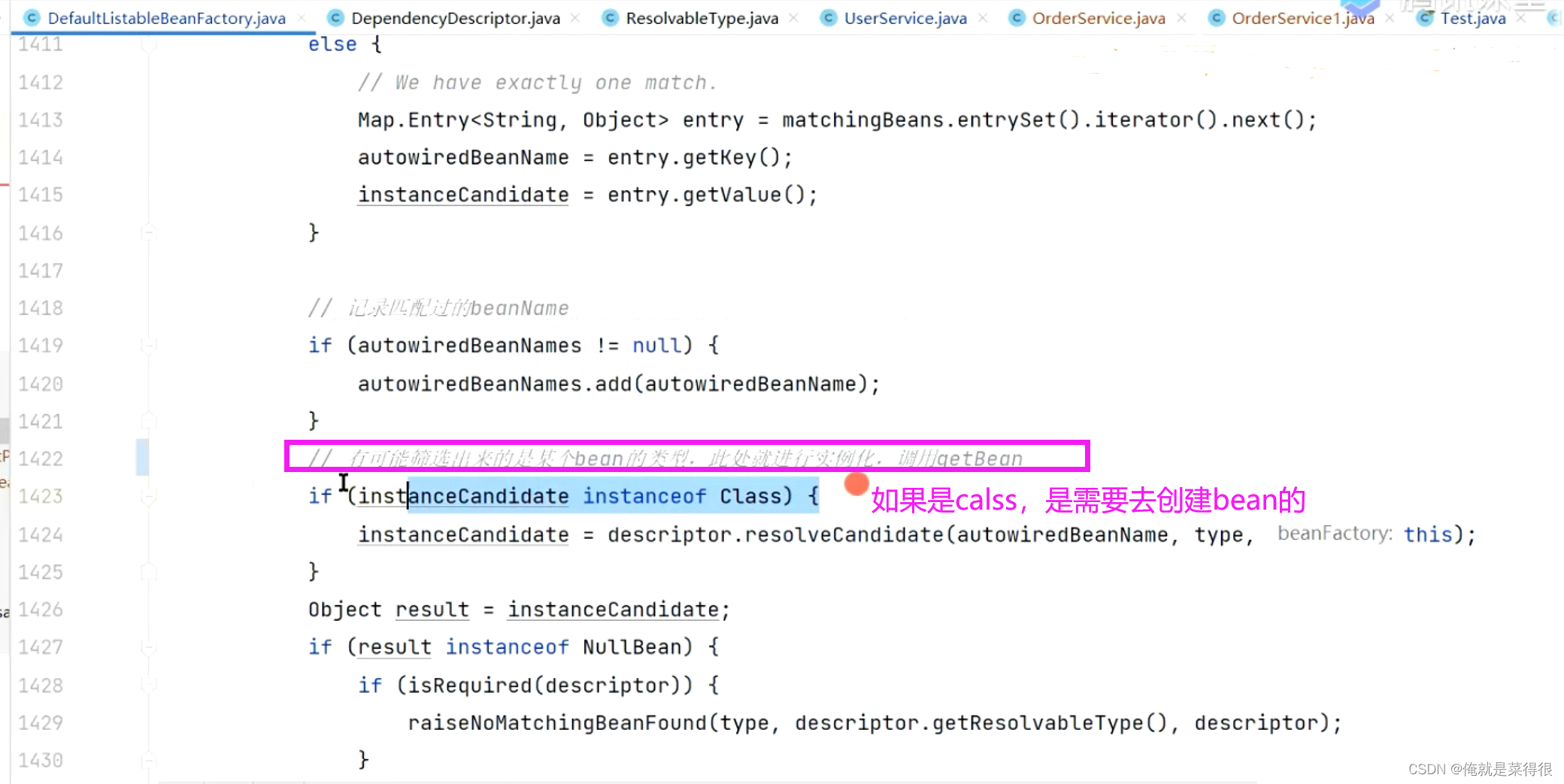
============================================================================================
还有些比较偏门的知识。
就是NullBean这种情况。最后显示的结果不是null。因为beanName还是zhouyu,value就是NullBean。
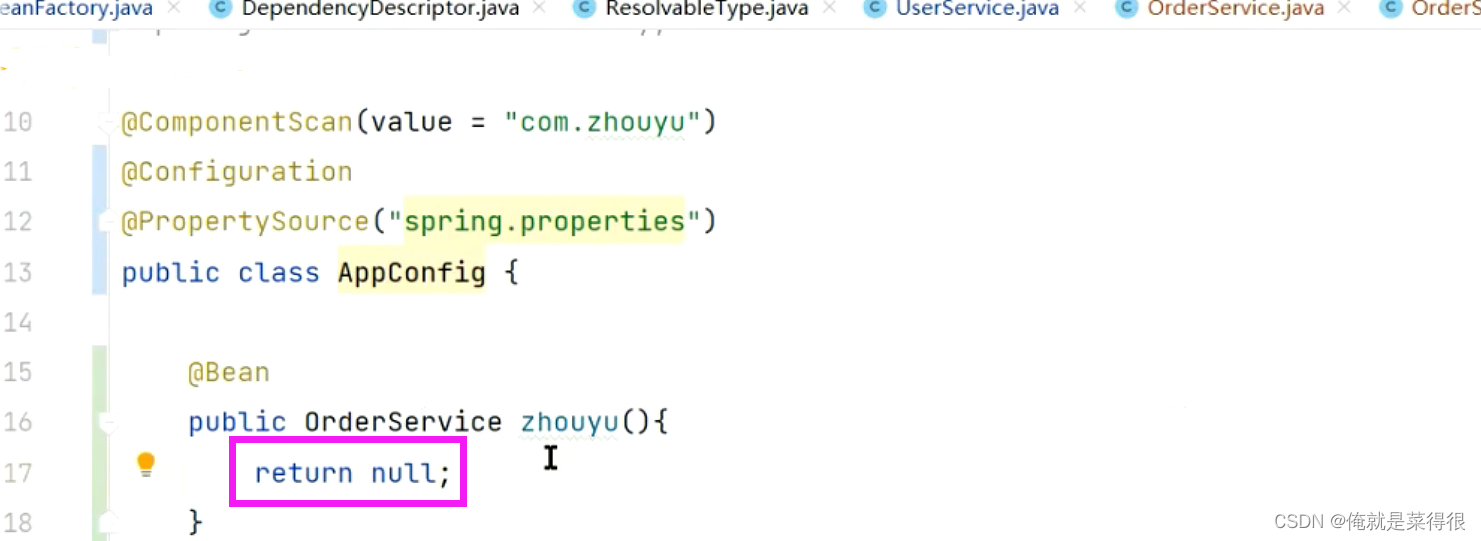
那spring是怎么处理的呢?

============================================================================================
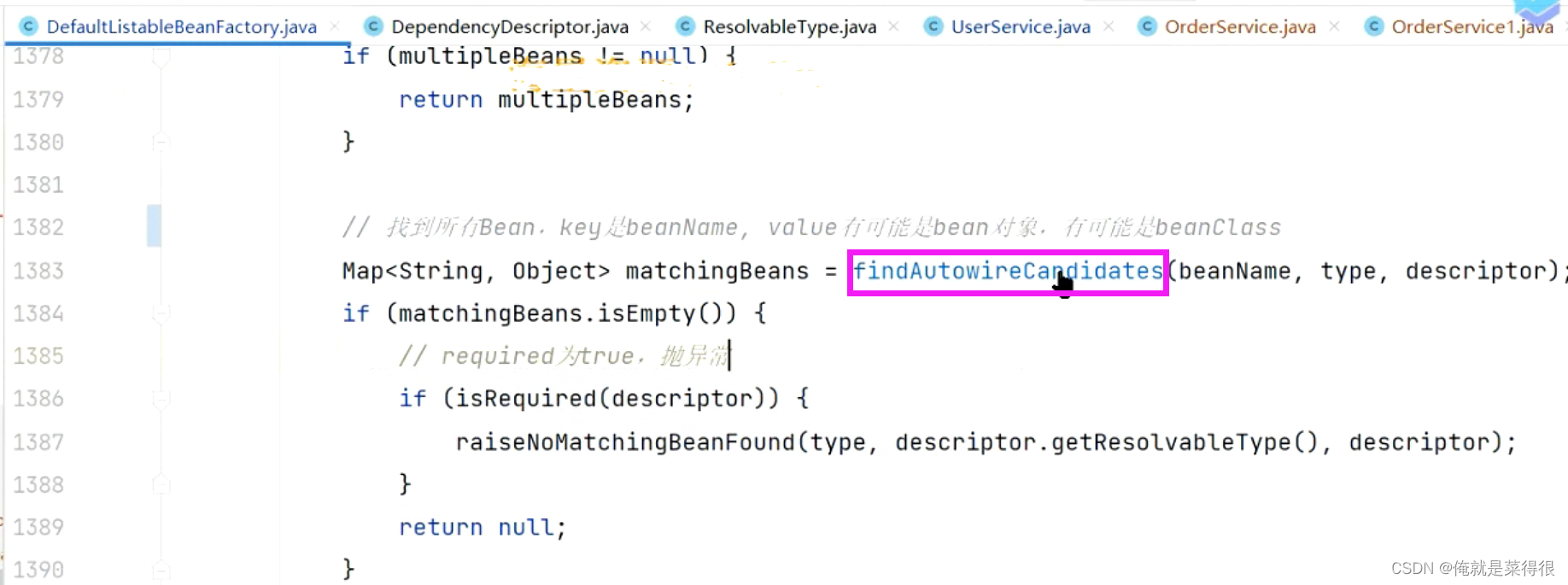
我们再回到那个核心的方法findAutowiredCandidates,根据类型去找bean,找到多个bean之后后面是怎么筛选的。这是我们前面讲的
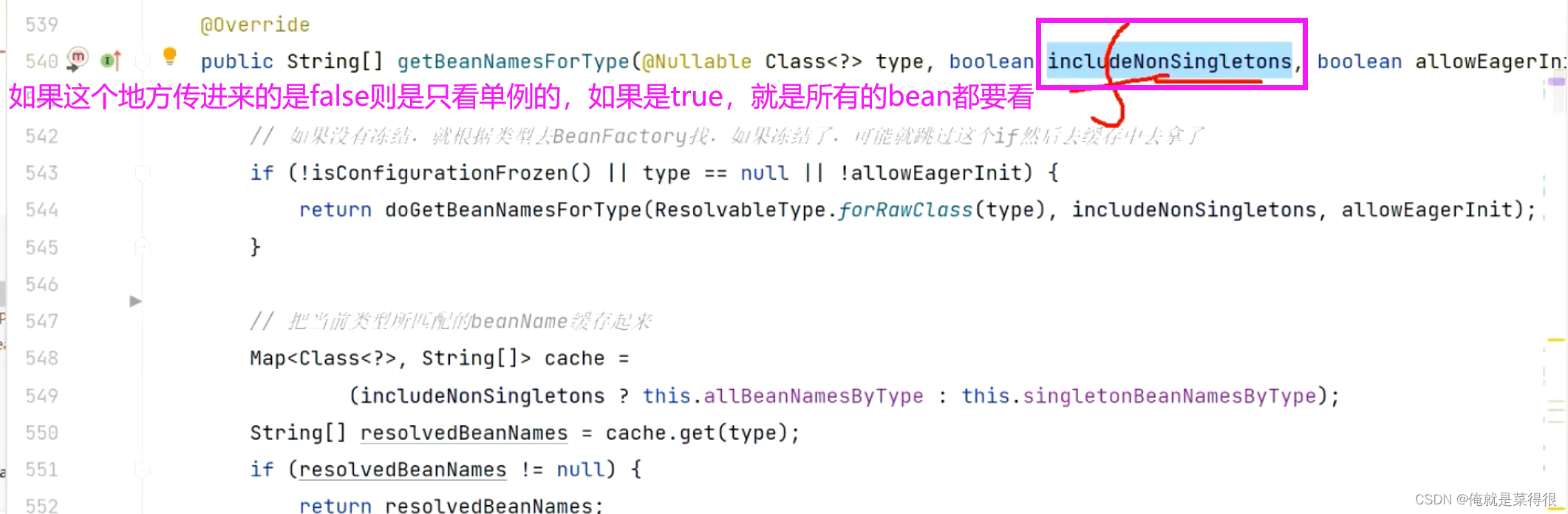
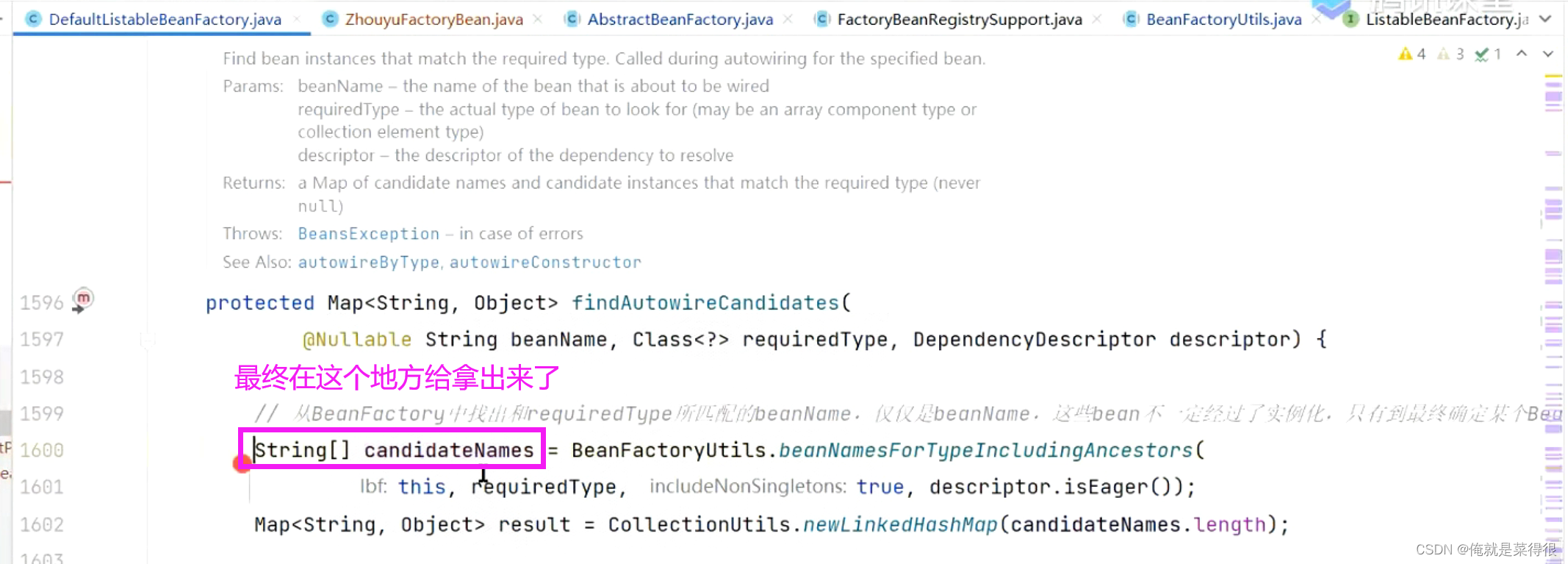
在spring里面那到底是如何根据类型去找到这些bean的呢?那么我们看一下这个方法。
进入这个方法之后想一下,BeanFactory里面有哪些东西是记录bean的类型的:单例池、BeanDefinitionMap。其实可以根据这两个类型去找哪些bean是符合的。然后我们先要有这个思路,再去看这个源码。
这个只会把名字给返回
这个时候要考虑bean工厂与父bean工厂。先到自己的bean工厂根据类型找到名字,然后再在父bean工厂里面根据类型找到名字。然后再把二者找到的名字合起来。
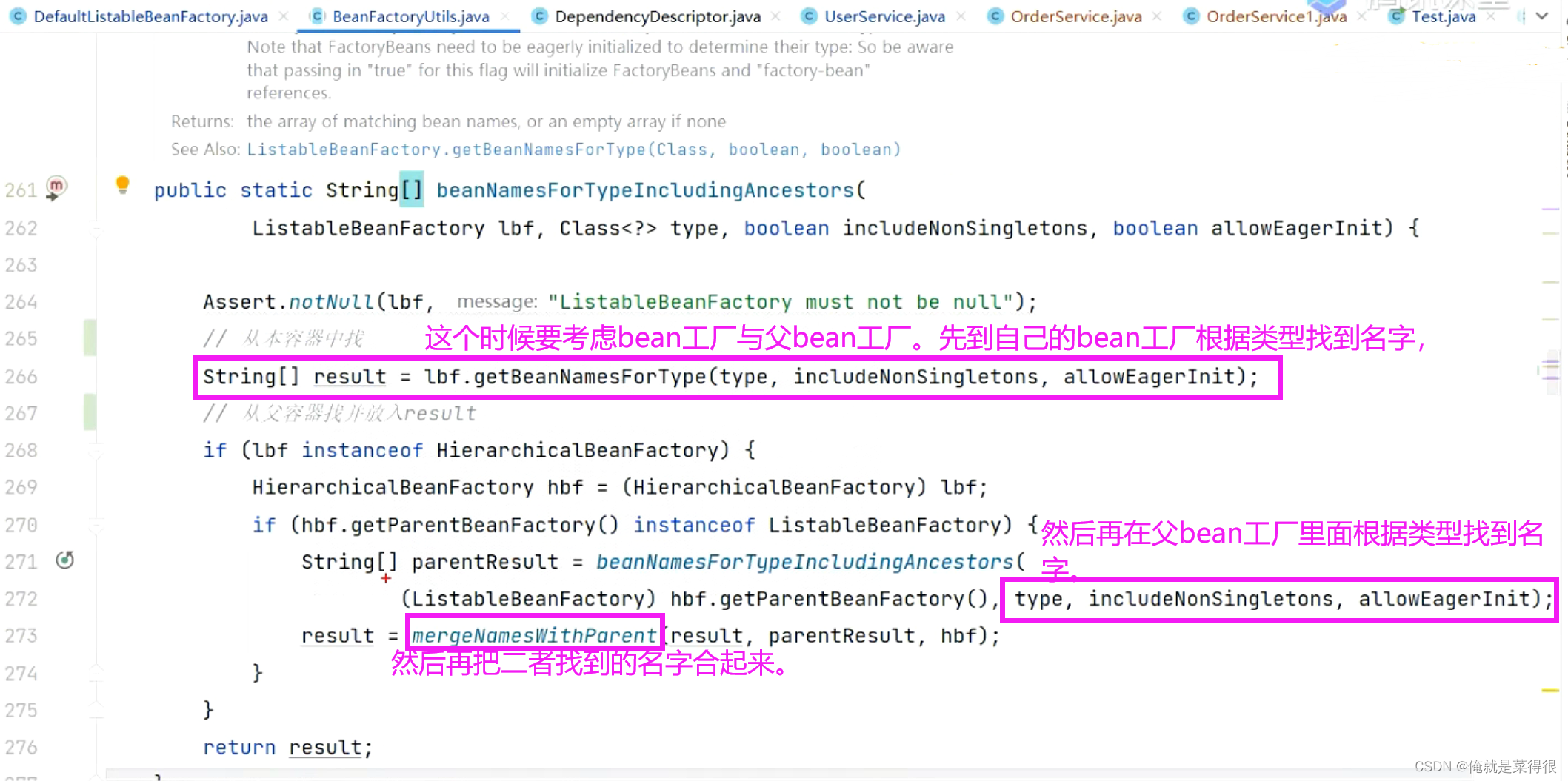
然后这块mergeNamesWithParent相当于是递归。
我们还是看getBeanNamesForType这个方法。
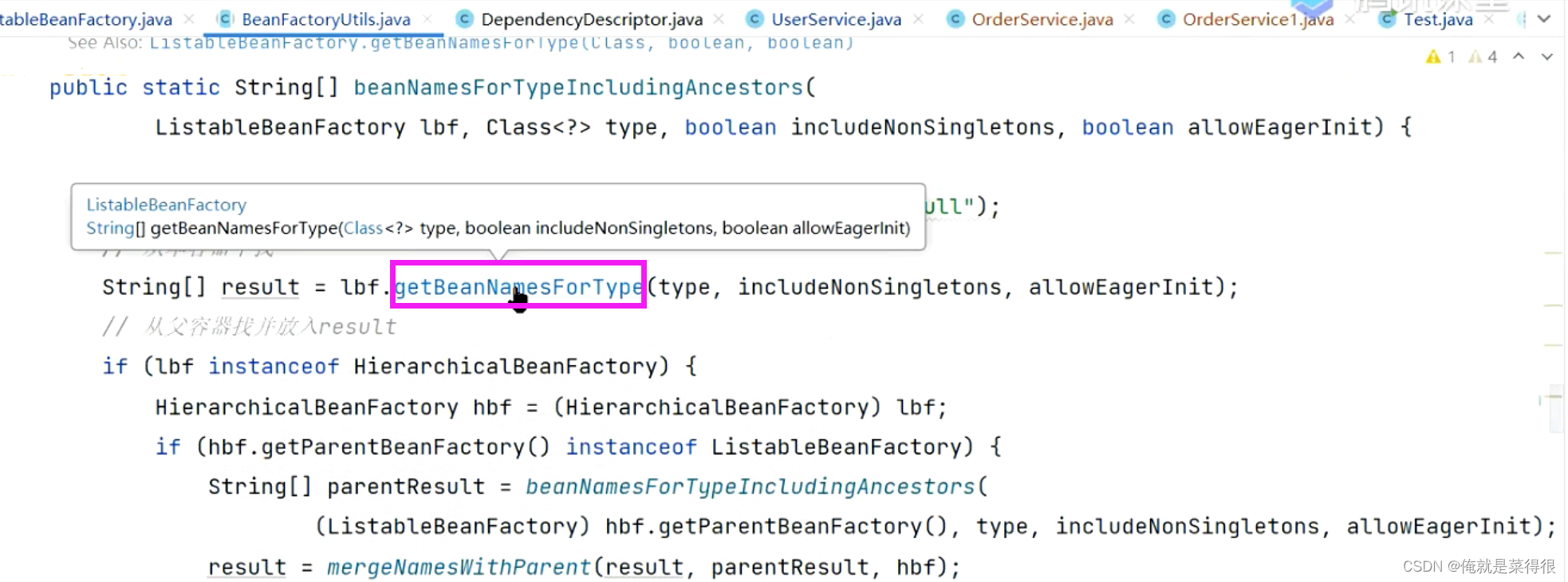
进入这个接口,在该接口中进去看实现方法。

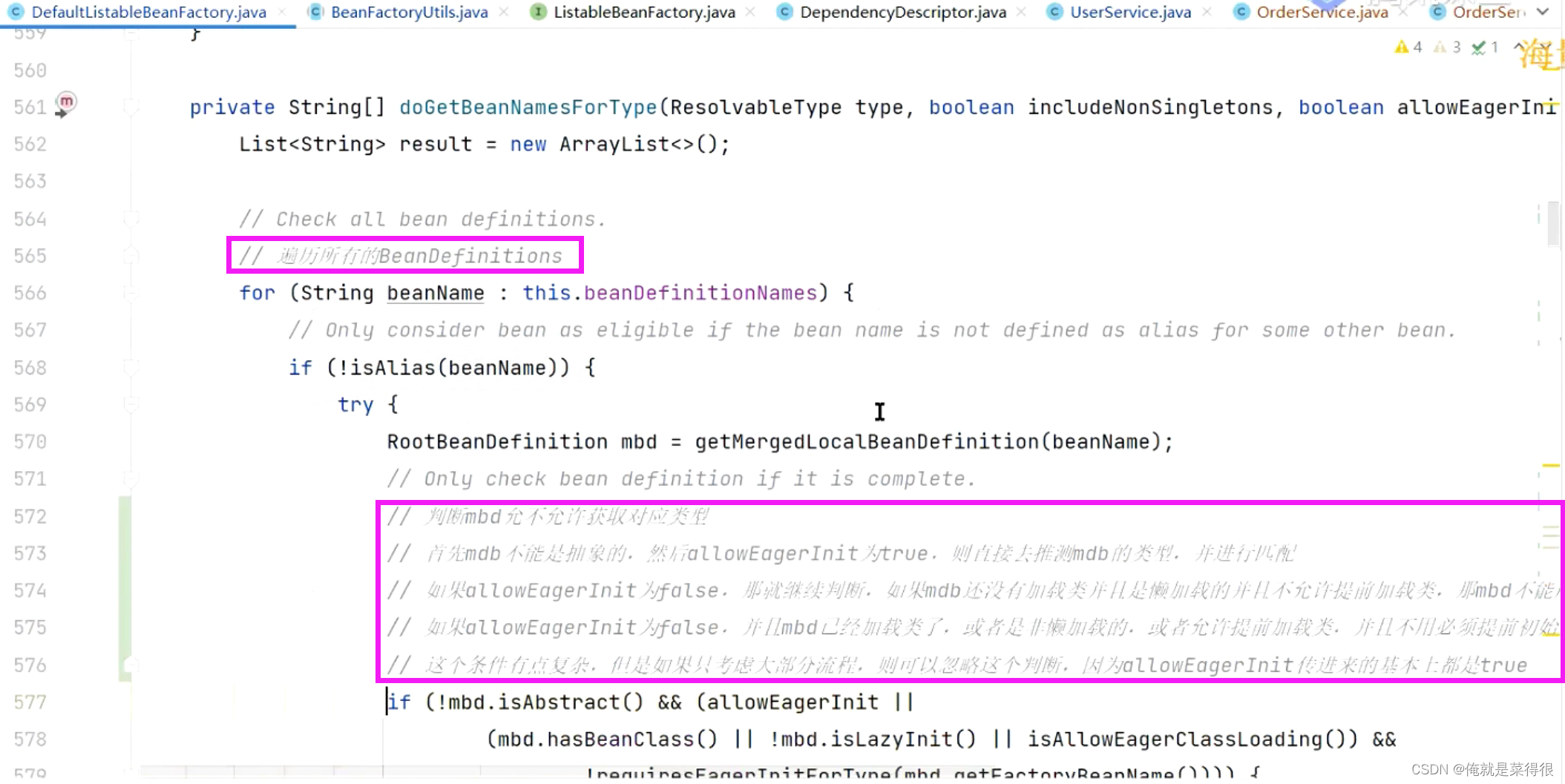
进来之后细看一下:
遍历beanDefinition。
我们拿到 这个bean需要看这个核心代码match这块进行比对是不是所需要的类型。
如果不是一个FactoryBean,就是一个普通的bean
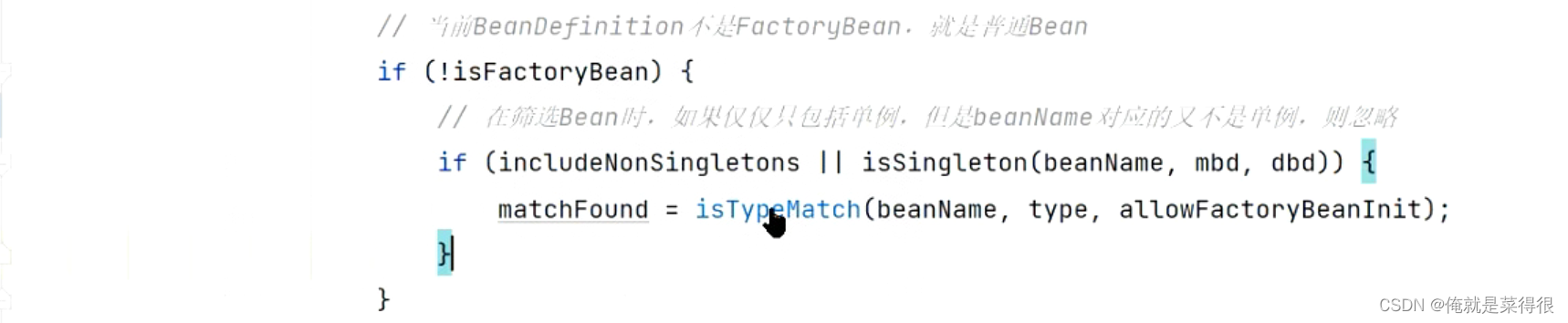
判断某一个bean的类型与传进来的bean的类型是不是同一个类型,首先就是看单例池里面有没有。
这个方法会考虑当前这个bean传过来的名字是怎么写的,要考虑很多种情况,你传进来的名字是不是FactoryBean,传进来的名字带不带&这个符号,如果是遍历的beanDefinition里面得到的名字是不会带有&这个的。但是他会兼容来考虑会不会带有这个&符号。
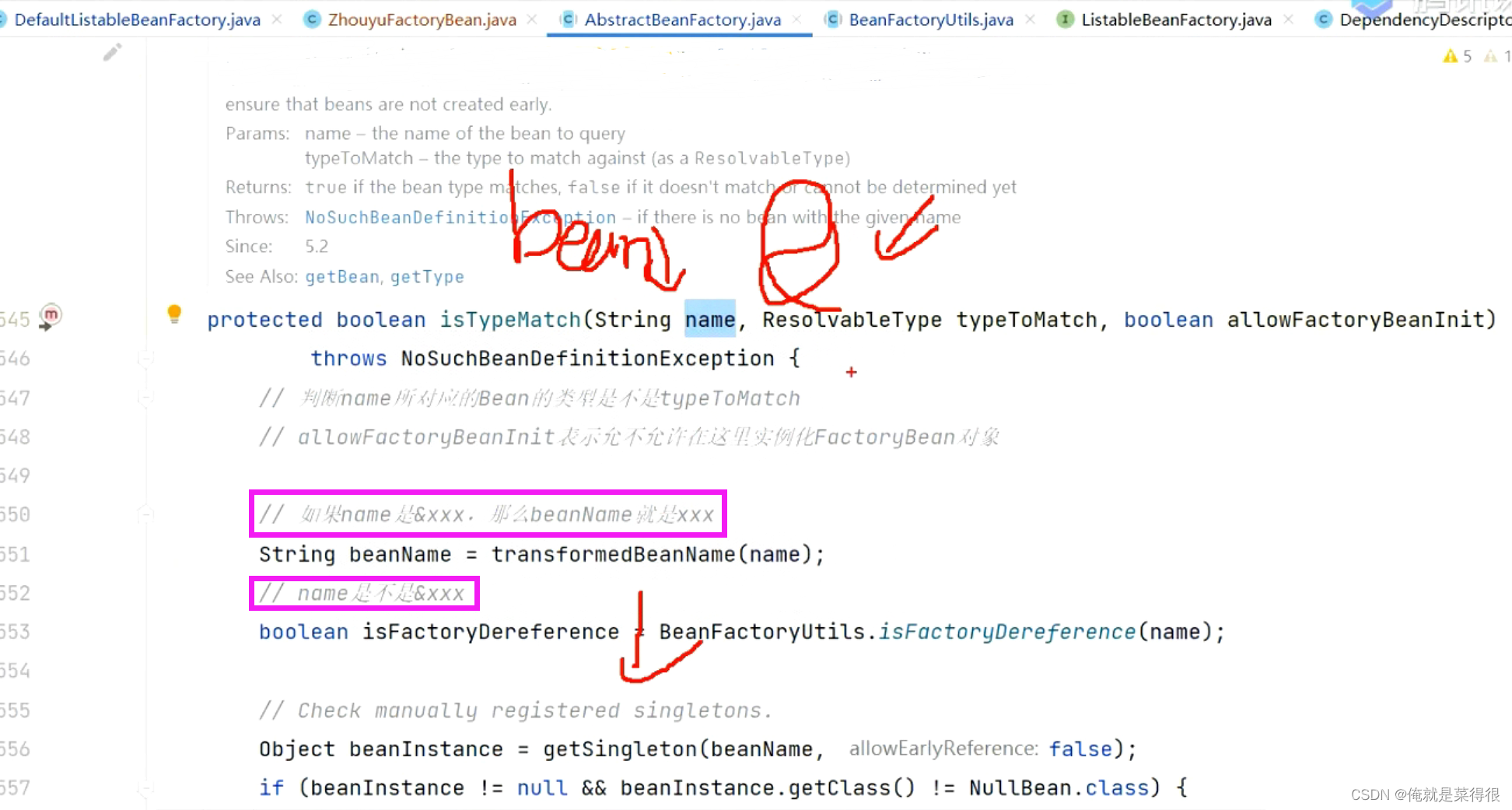
如果一个bean是FactoryBean,那么这个FactoryBean是什么类型呢?
我们定义一个FactoryBean的时候要调用两个方法,

这样设计的目的是什么?spring单独设置一个这样的方法的目的是:因为我有一个类型,我要判断当前这个bean是不是我要的这个类型,怎么判断呢?直接生成这个对象吗,不是。最好是先别实例化,因为你生成了万一我不用就浪费了,而是直接提供了一个API,不用生成这个对象。
所以当我们从单例池拿到一个对象,你是FactoryBean,直接调用下面这个方法。
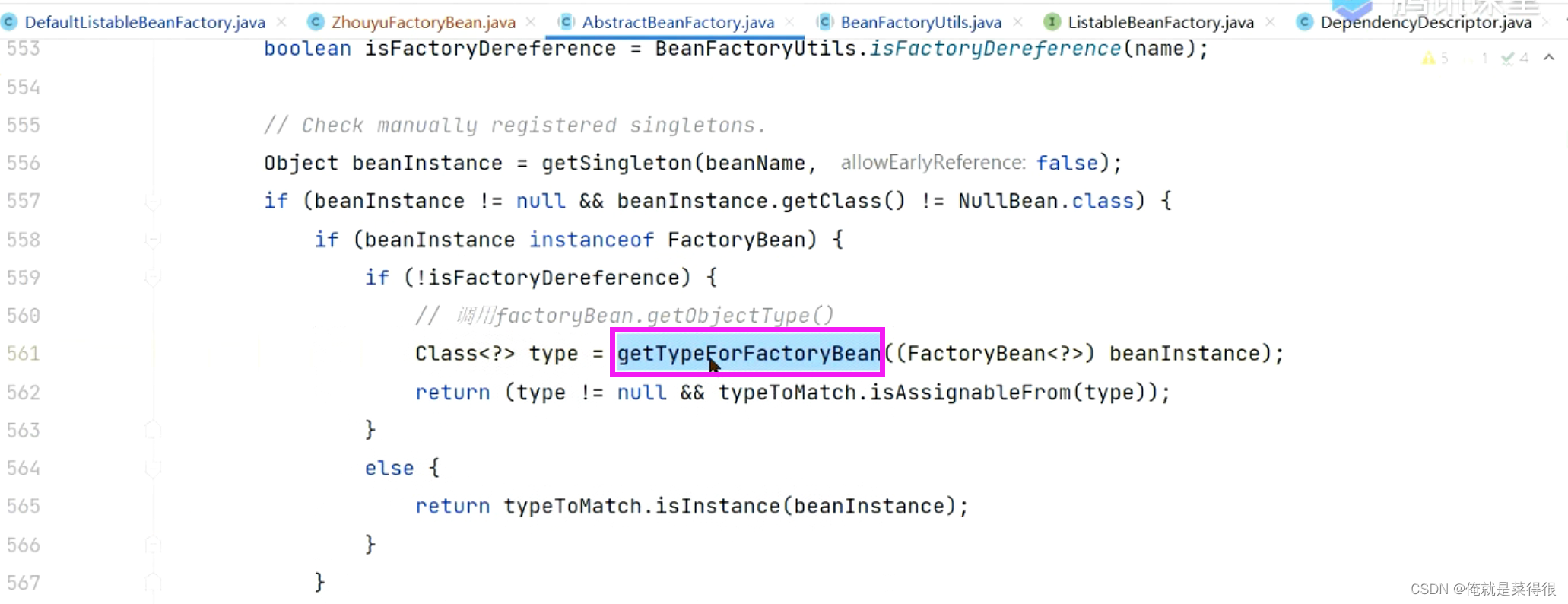
在这个方法里面直接调用FactoryBean里面的getObjectType方法。
如果遍历的单例bean里面没有这个bean。接下来只能用mbd
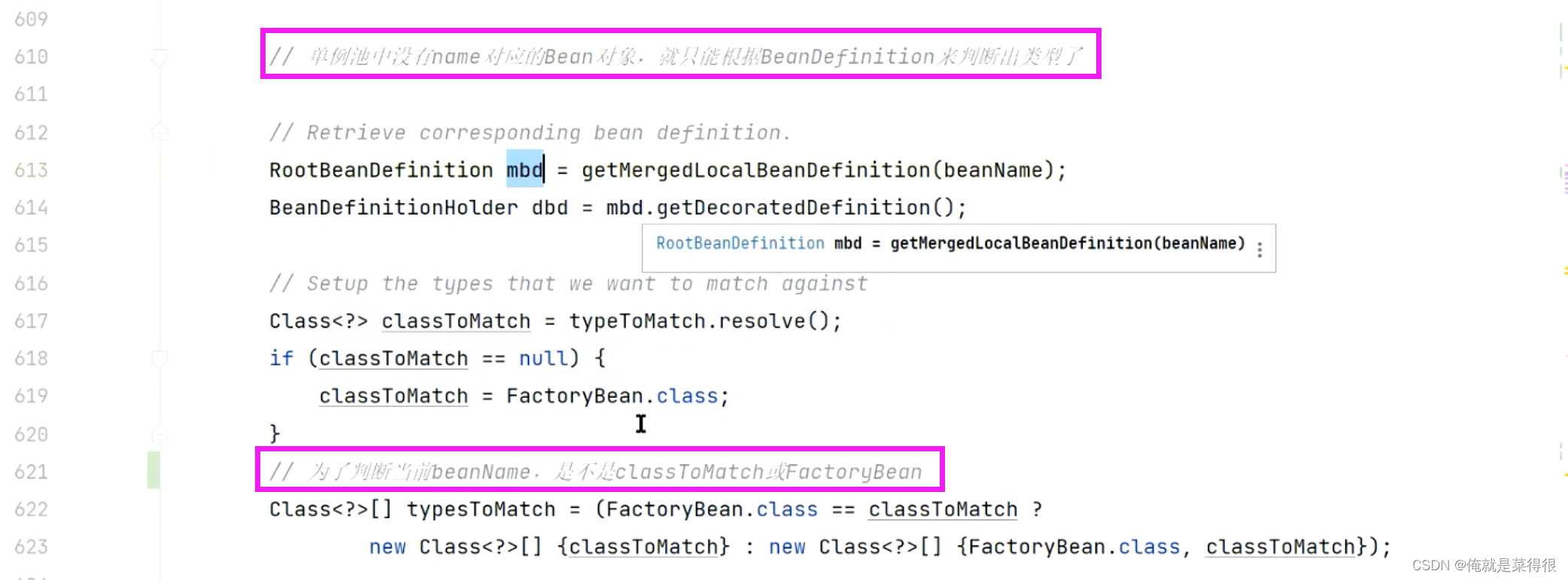
============================================================================================
spring在进行依赖注入的时候他需要根据当前的类型去找到到底是有哪些bean是之匹配的,就是把spring里面那些bean,那些bean的名字去遍历,去单例池里面去拿beanDefinition。去进行判断,最终看你的类型是不是和我是匹配的,最终会直接返回一个结果,这个结果就是符合要求的bean的名字。
这时候下面又涉及到一个Map,这个Map是和spring启动是有关系的。
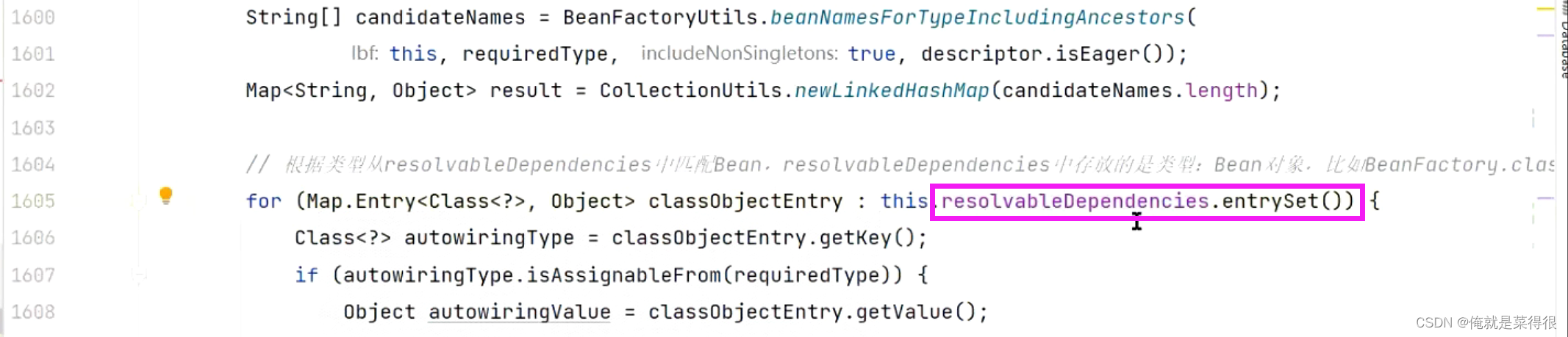
这个Map里面存的是某个类型你对应的bean是什么,这个和单例池不太一样。spring启动的时候就会往这个Map里面存东西。

Map里面存的是某一个类型对应的bean对象是什么。
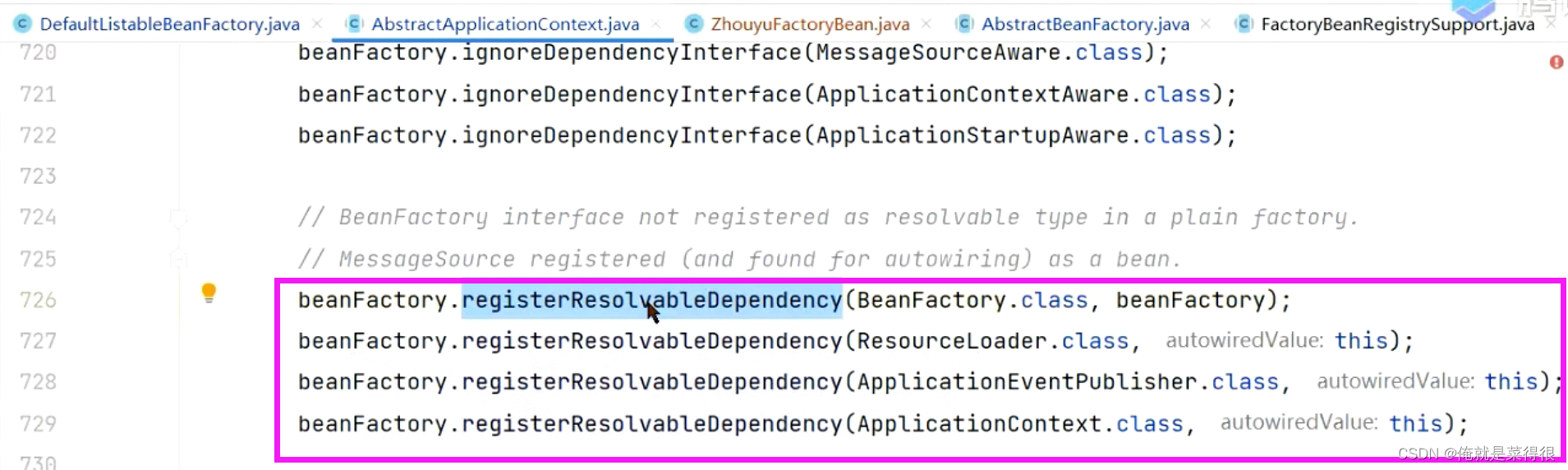
在外面你也可以直接指定某个类型对应的bean对象是什么。
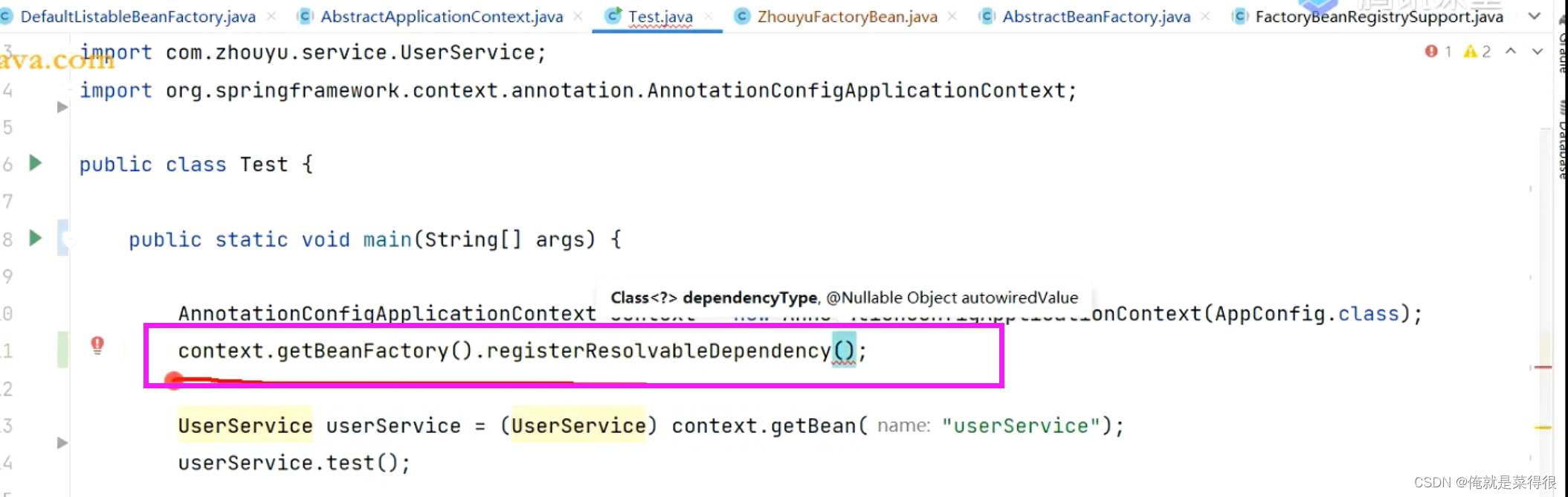
现在的目录是:

在spring里面既然支持一个这样的Map,现在就去spring容器中找有哪些bean是这个类型的。

如果直接存到这个Map里面的话,Map里面有没有我要的这个类型,把这个bean对象加到我这个集合里面来。其实通过这个方式是没有bean的名字的。

spring容器启动所存的东西,只是把一个类型的bean对象存起来了,其实这个bean对象是一直没有bean的名字的,所以beanDefinition、单例池里面都是没有那个对象的,比如applicationContext都没有,他只会存在resolvableDependencies里面。
现在举一个例子就是自己注入自己
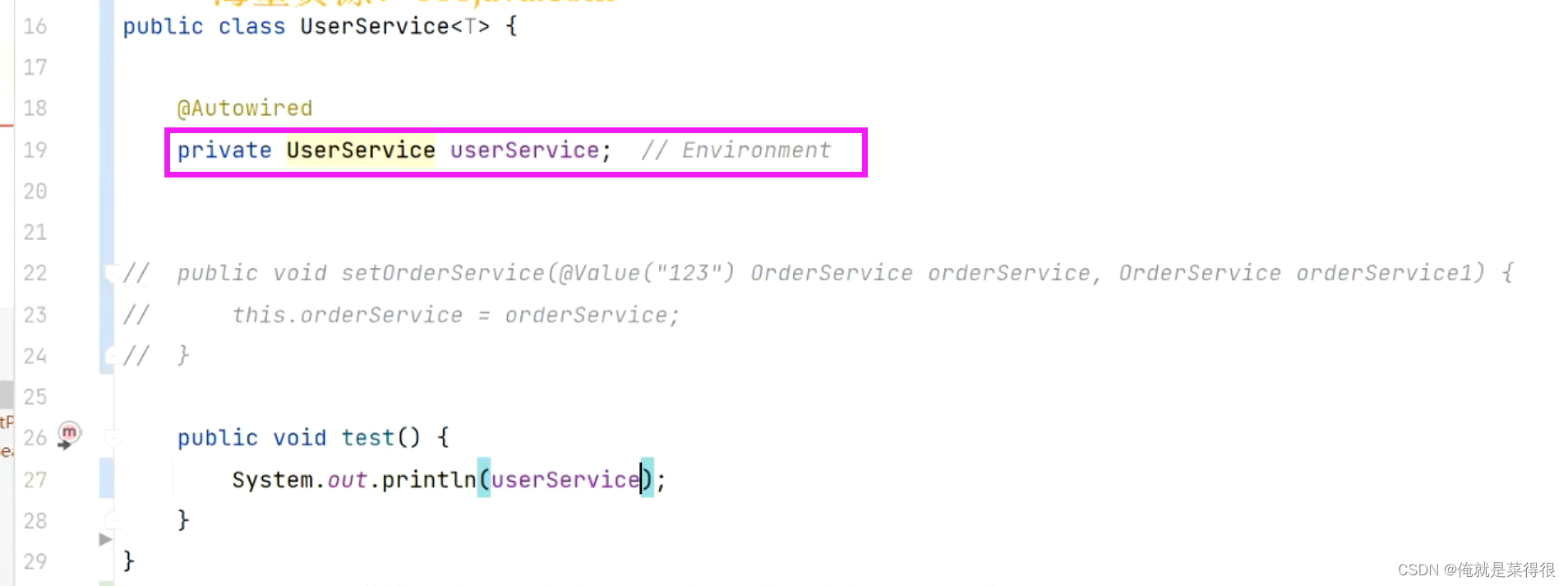
假设再定义一个bean

现在spring容器里面有两个UserService的bean。
现在相当于自己注入自己,那注入的到底是谁呢?
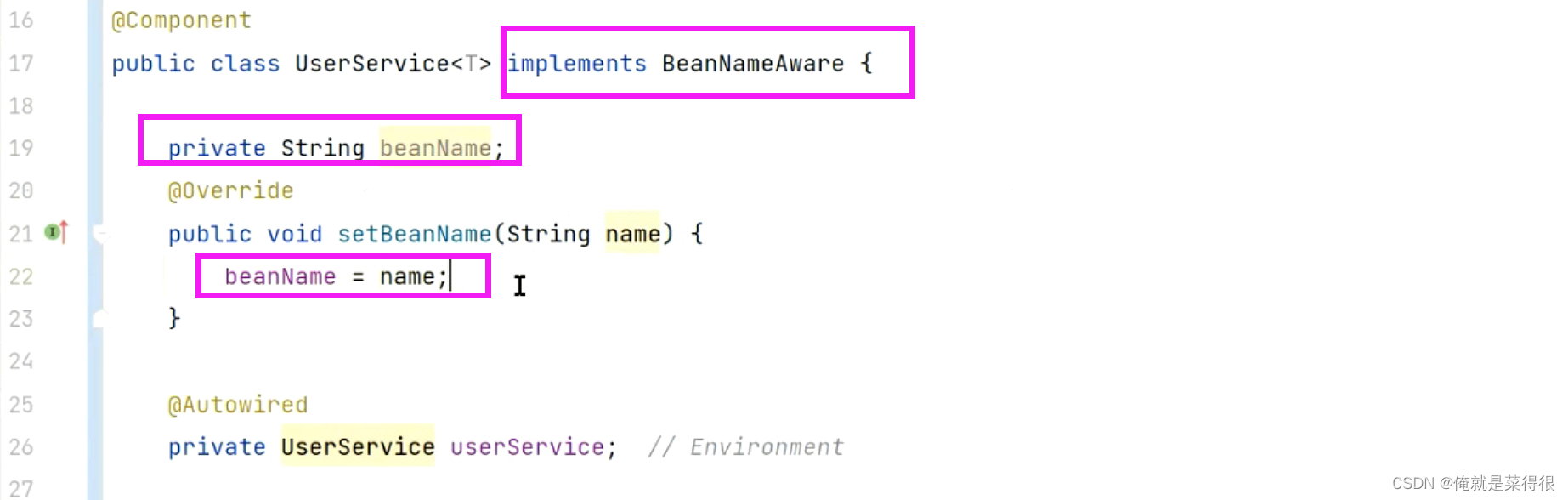
现在再在下面写一个toString方法

按照我们正常的分析,我们先根据类型去找,找到两个,然后最终根据名字去找,根据名字找到自己,因为另一个UserService是叫UserService1.
在进行依赖注入的时候他不是先考虑的自己,是先考虑别人,当依赖注入不是自己的时候先进行执行。
============================================================================================
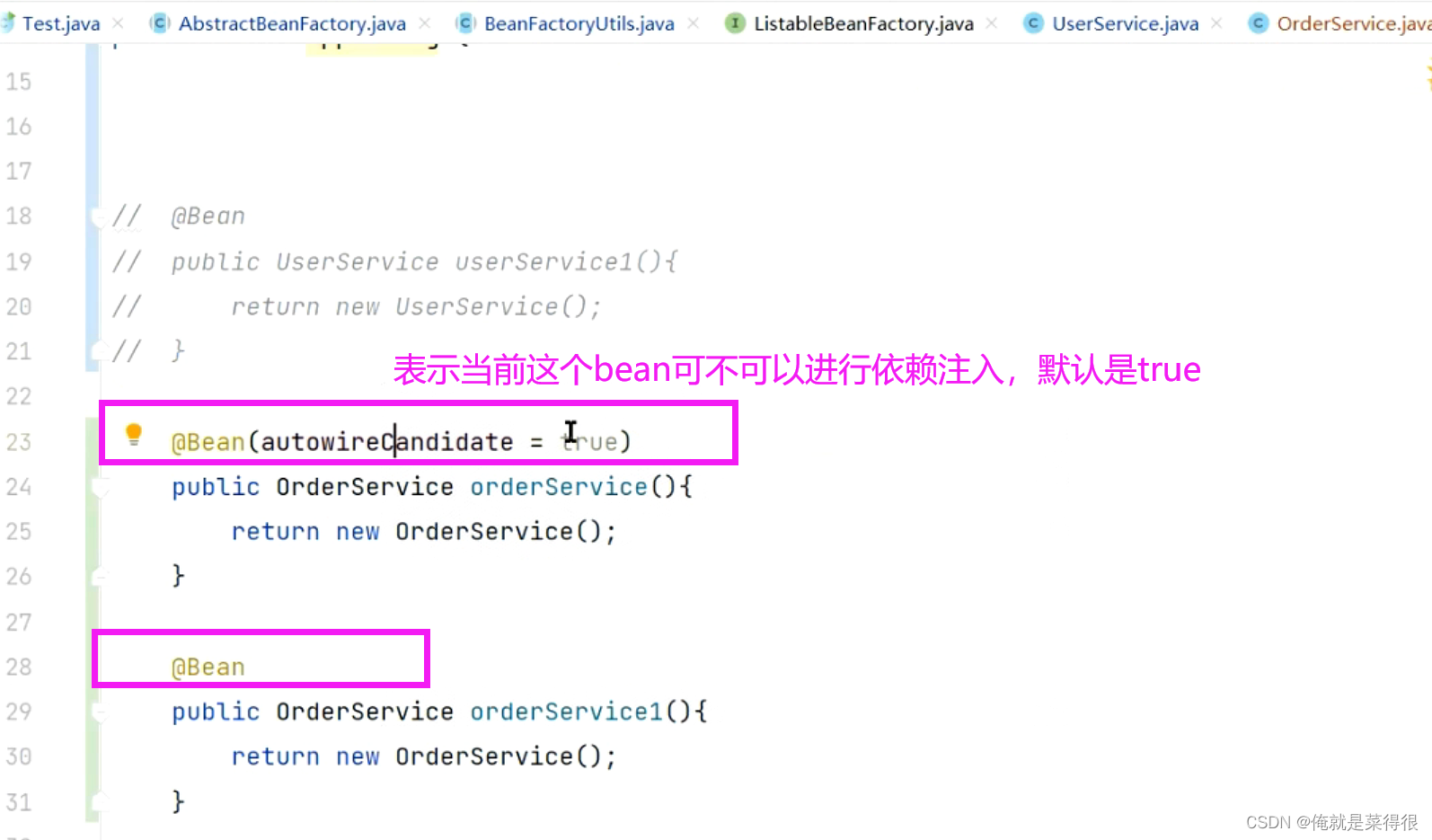
根据类型找到了与之匹配的,但是这些bean可不可以进行依赖注入呢?

比如我们以OrderService为例。
把这个OrderService单纯的定义为一个类,

在AppConfig里面还是定义两个bean
表示当前这个bean可不可以进行依赖注入,默认是true
那么这个到底能不能依赖注入在哪地方实现的呢?

你传给我一个bean的名字,我找到你的beanDefinition,找到之后判断这个属性是true还是false。
如果是true就可以进行依赖注入,如果不是就不能。
真正的类是这个类
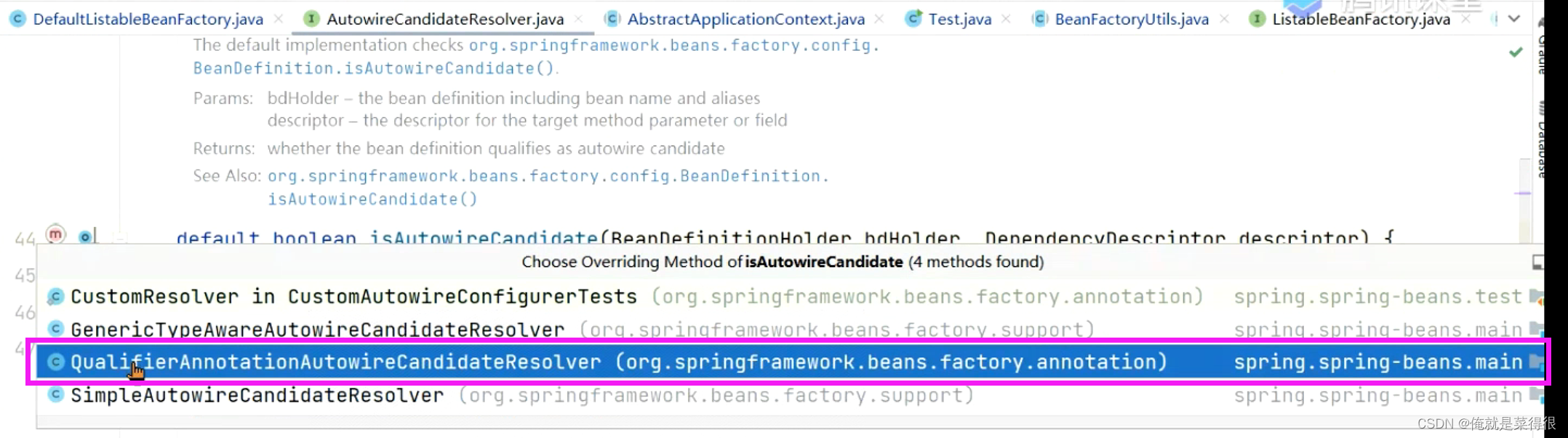
判断这个类能不能依赖注入,不是直接去判断这个属性的,是先判断父类能不能依赖注入,如果是不能依赖注入就是false就直接返回了。
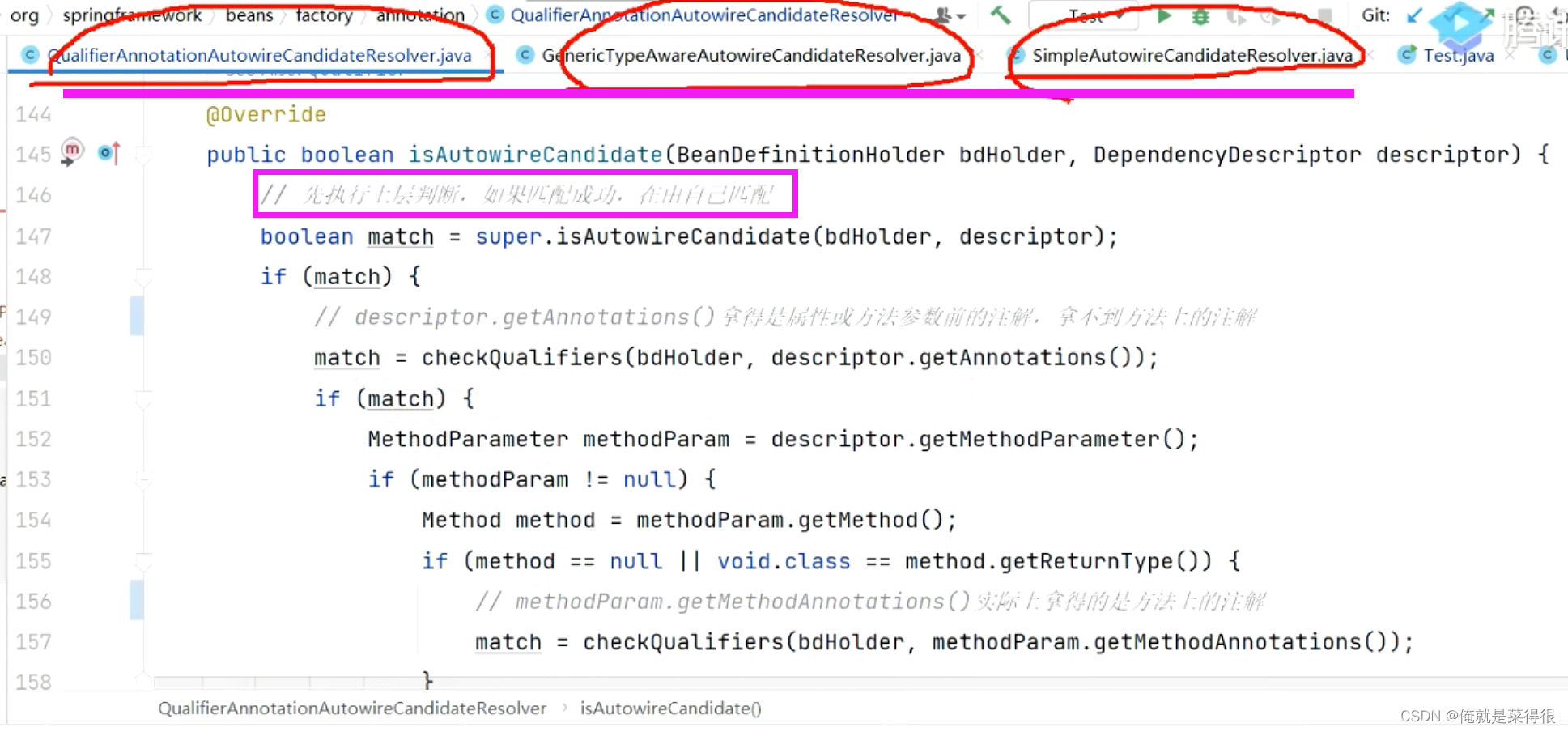
右一是根据属性判断能不能依赖注入,中间是与泛型相关的能不能进行依赖注入,左一是有一个Qualifiers进行判断的,分别有自己的责任。这就是责任链模式。
============================================================================================
我们先来看这个泛型的能不能进行依赖注入。
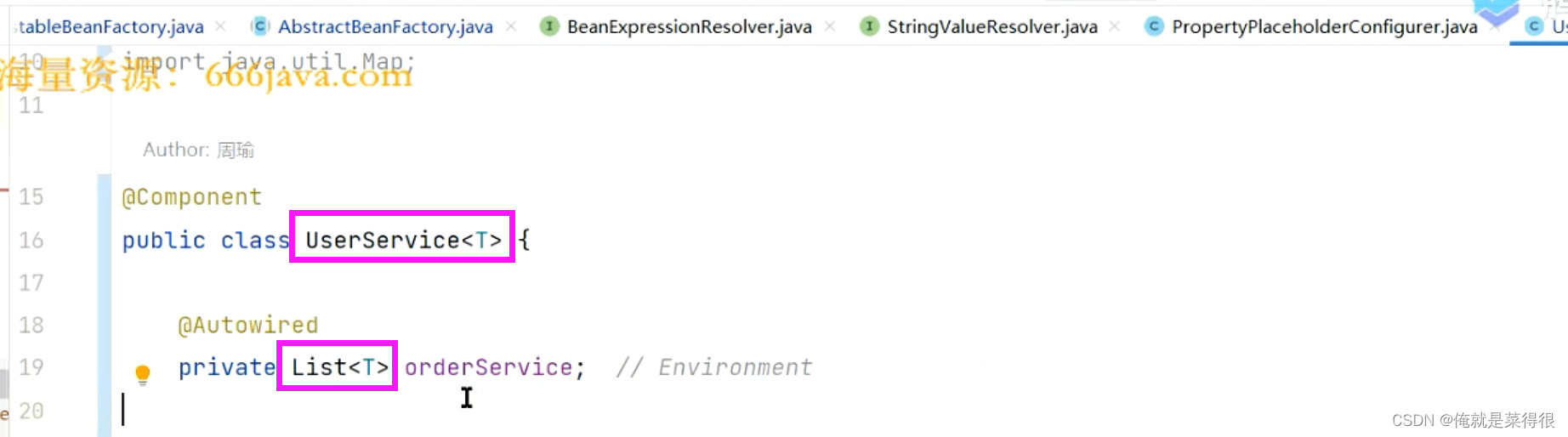
先举个例子,创建一个BaseService。

创建一个类,把他定义成一个bean

这个里面虽然没有属性但是父类里面有。

》
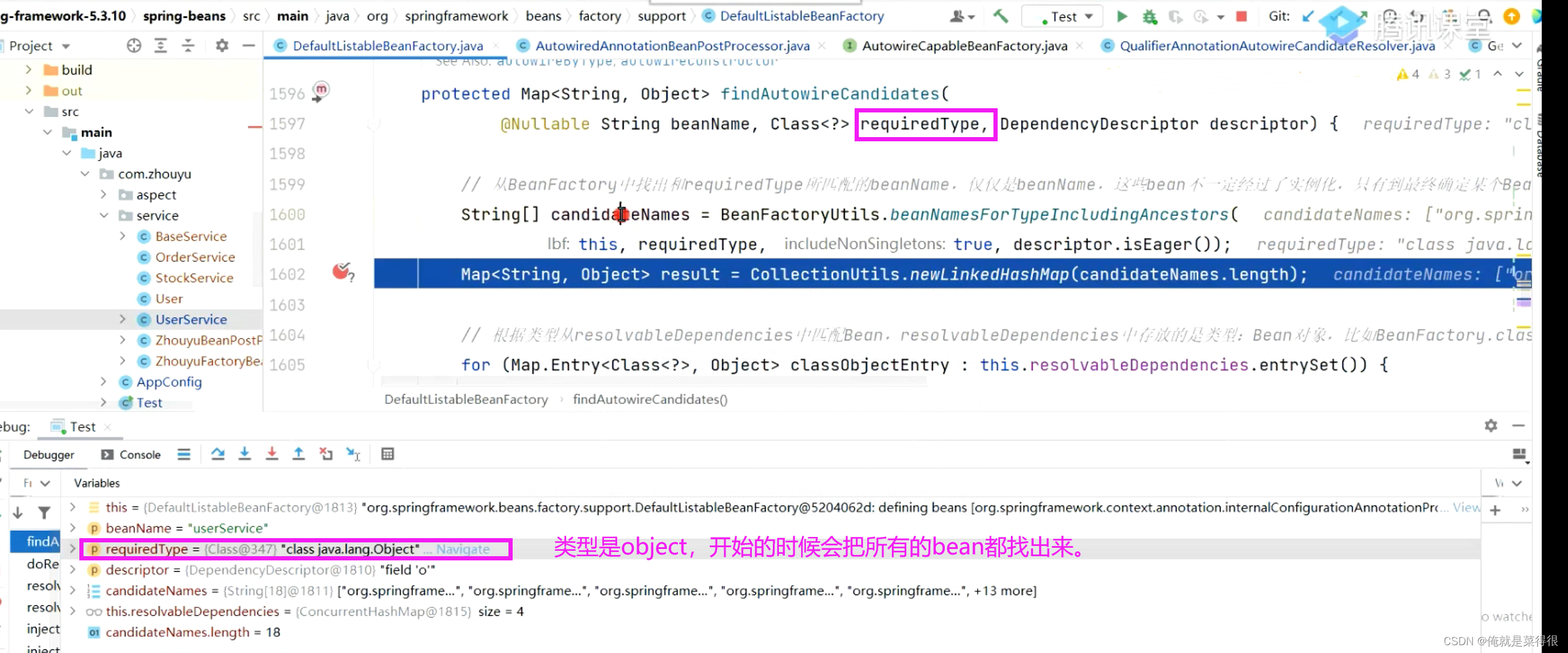
因为是泛型,会找到很多个。要进行筛选。
当进行判断的时候要知道真正的类型才能进行判断。
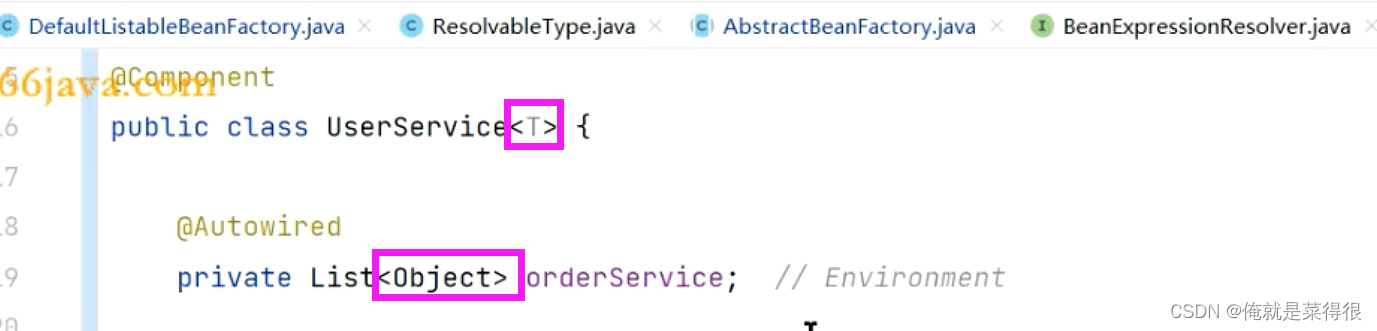
在Userservice继承BaseService下这个o就是OrderService。拿到类型之后可以再进行筛选。
通过反射机制可以拿到O,S对应关系
O就是OrderService,S就是stockService。
先根据类型去找bean,一开始会找到多个,进行筛选,多个中先进行autowireCandidate是否等于true进行判断进行第一次筛选。
再进行判断你这个属性是不是泛型,如果是泛型,再去看这个多个bean里面的泛型真正对应的bean是不是相当,相当于是第二层判断,也是第二次筛选。
基于以上两个判断完成后会再进行Qualifiers进行判断的。
在进行依赖注入筛选的时候是有6个判断的。
第一个判断就是这个属性。

第二个判断是,是不是泛型的这个判断。
第三个判断就是Qualifiers
第四个判断primary这个判断
第五个判断就是优先级最高的判断
第六个判断就是你的名字。
============================================================================================
============================================================================================
上节课我们讲了Spring中的自动注入(byName,byType)和@Autowired注解的工作原理以及源码分析,那么今天这节课,我们来分析还没讲完的,剩下的核心的方法:
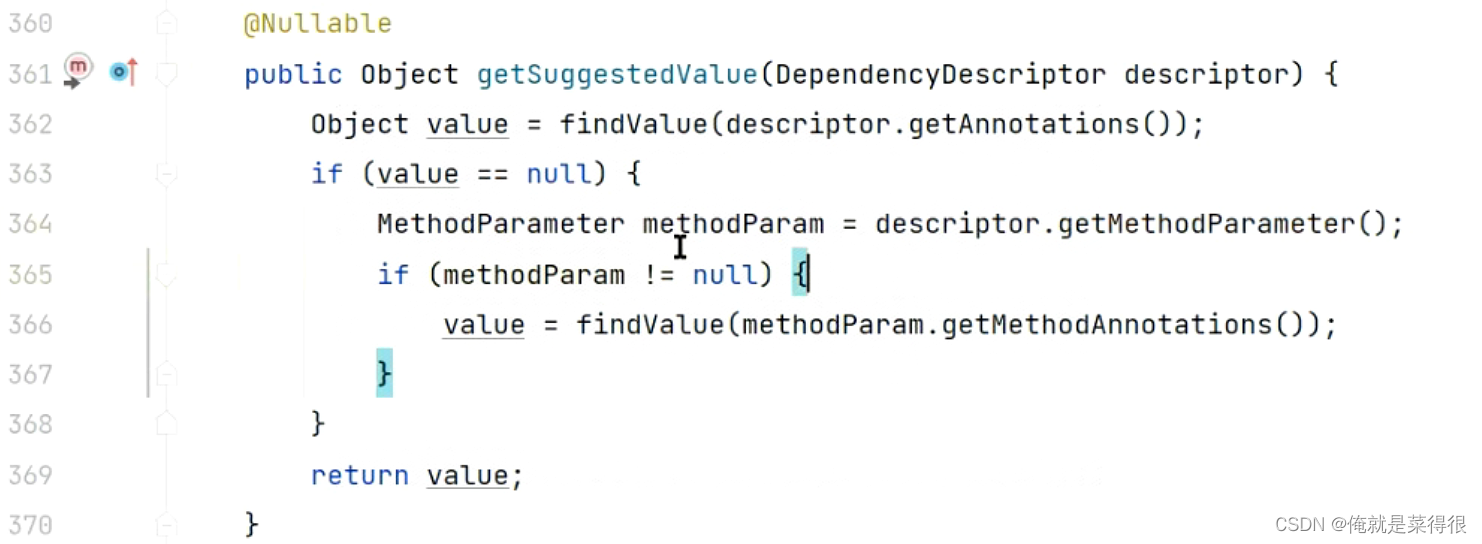
@Nullable
Object resolveDependency(DependencyDescriptor descriptor, @Nullable String requestingBeanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException;
该方法表示,传入一个依赖描述(DependencyDescriptor),该方法会根据该依赖描述从BeanFactory中找出对应的唯一的一个Bean对象。
下面来分析一下DefaultListableBeanFactory中resolveDependency()方法的具体实现,具体流程图:
https://www.processon.com/view/link/5f8d3c895653bb06ef076688
findAutowireCandidates()实现
根据类型找beanName的底层流程:https://www.processon.com/view/link/6135bb430e3e7412ecd5d1f2
对应执行流程图为:https://www.processon.com/view/link/5f8fdfa8e401fd06fd984f20
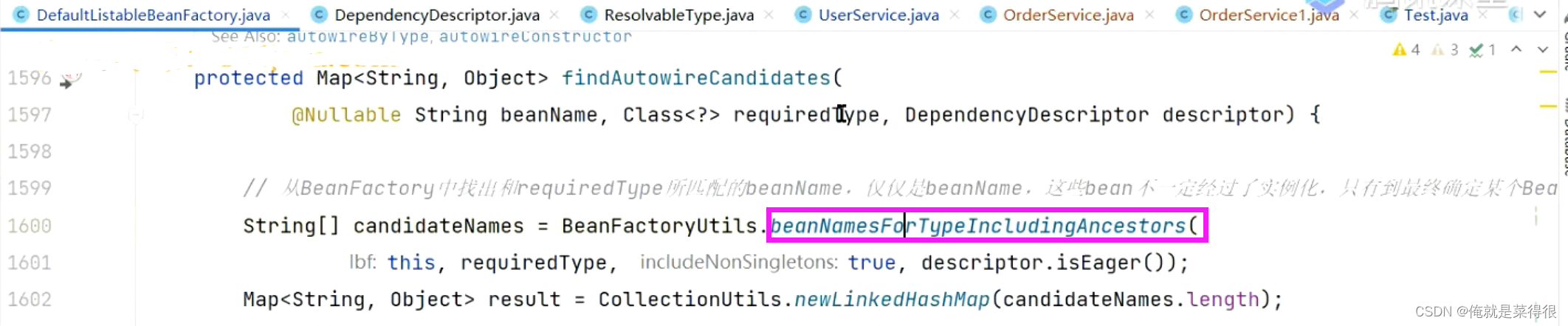
- 找出BeanFactory中类型为type的所有的Bean的名字,注意是名字,而不是Bean对象,因为我们可以根据BeanDefinition就能判断和当前type是不是匹配,不用生成Bean对象
- 把resolvableDependencies中key为type的对象找出来并添加到result中
- 遍历根据type找出的beanName,判断当前beanName对应的Bean是不是能够被自动注入
- 先判断beanName对应的BeanDefinition中的autowireCandidate属性,如果为false,表示不能用来进行自动注入,如果为true则继续进行判断
- 判断当前type是不是泛型,如果是泛型是会把容器中所有的beanName找出来的,如果是这种情况,那么在这一步中就要获取到泛型的真正类型,然后进行匹配,如果当前beanName和当前泛型对应的真实类型匹配,那么则继续判断
- 如果当前DependencyDescriptor上存在@Qualifier注解,那么则要判断当前beanName上是否定义了Qualifier,并且是否和当前DependencyDescriptor上的Qualifier相等,相等则匹配
- 经过上述验证之后,当前beanName才能成为一个可注入的,添加到result中
关于依赖注入中泛型注入的实现
首先在Java反射中,有一个Type接口,表示类型,具体分类为:
- raw types:也就是普通Class
- parameterized types:对应ParameterizedType接口,泛型类型
- array types:对应GenericArrayType,泛型数组
- type variables:对应TypeVariable接口,表示类型变量,也就是所定义的泛型,比如T、K
- primitive types:基本类型,int、boolean
大家可以好好看看下面代码所打印的结果:
public class TypeTest<T> {
private int i;
private Integer it;
private int[] iarray;
private List list;
private List<String> slist;
private List<T> tlist;
private T t;
private T[] tarray;
public static void main(String[] args) throws NoSuchFieldException {
test(TypeTest.class.getDeclaredField("i"));
System.out.println("=======");
test(TypeTest.class.getDeclaredField("it"));
System.out.println("=======");
test(TypeTest.class.getDeclaredField("iarray"));
System.out.println("=======");
test(TypeTest.class.getDeclaredField("list"));
System.out.println("=======");
test(TypeTest.class.getDeclaredField("slist"));
System.out.println("=======");
test(TypeTest.class.getDeclaredField("tlist"));
System.out.println("=======");
test(TypeTest.class.getDeclaredField("t"));
System.out.println("=======");
test(TypeTest.class.getDeclaredField("tarray"));
}
public static void test(Field field) {
if (field.getType().isPrimitive()) {
System.out.println(field.getName() + "是基本数据类型");
} else {
System.out.println(field.getName() + "不是基本数据类型");
}
if (field.getGenericType() instanceof ParameterizedType) {
System.out.println(field.getName() + "是泛型类型");
} else {
System.out.println(field.getName() + "不是泛型类型");
}
if (field.getType().isArray()) {
System.out.println(field.getName() + "是普通数组");
} else {
System.out.println(field.getName() + "不是普通数组");
}
if (field.getGenericType() instanceof GenericArrayType) {
System.out.println(field.getName() + "是泛型数组");
} else {
System.out.println(field.getName() + "不是泛型数组");
}
if (field.getGenericType() instanceof TypeVariable) {
System.out.println(field.getName() + "是泛型变量");
} else {
System.out.println(field.getName() + "不是泛型变量");
}
}
}
Spring中,但注入点是一个泛型时,也是会进行处理的,比如:
@Component
public class UserService extends BaseService<OrderService, StockService> {
public void test() {
System.out.println(o);
}
}
public class BaseService<O, S> {
@Autowired
protected O o;
@Autowired
protected S s;
}
- Spring扫描时发现UserService是一个Bean
- 那就取出注入点,也就是BaseService中的两个属性o、s
- 接下来需要按注入点类型进行注入,但是o和s都是泛型,所以Spring需要确定o和s的具体类型。
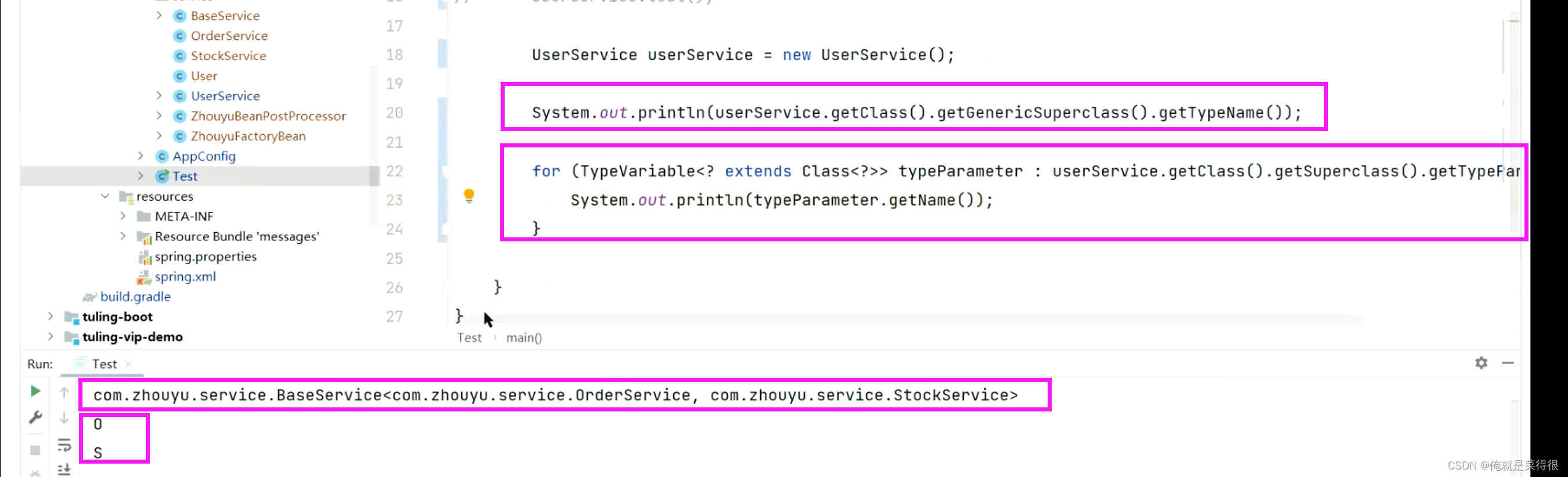
- 因为当前正在创建的是UserService的Bean,所以可以通过userService.getClass().getGenericSuperclass().getTypeName()获取到具体的泛型信息,比如com.zhouyu.service.BaseService<com.zhouyu.service.OrderService, com.zhouyu.service.StockService>
- 然后再拿到UserService的父类BaseService的泛型变量: for (TypeVariable<? extends Class<?>> typeParameter : userService.getClass().getSuperclass().getTypeParameters()) {
System.out.println(typeParameter.getName());
} - 通过上面两段代码,就能知道,o对应的具体就是OrderService,s对应的具体类型就是StockService
- 然后再调用oField.getGenericType()就知道当前field使用的是哪个泛型,就能知道具体类型了
@Qualifier的使用
最后来看一下这个Qualifiers
举个例子

》

那么最终属性注入的结果是什么。
就是上面都是a的。
到底有什么用。举例子:
定义两个注解:
@Target({ElementType.TYPE, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Qualifier("random")
public @interface Random {
}
@Target({ElementType.TYPE, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Qualifier("roundRobin")
public @interface RoundRobin {
}
定义一个接口和两个实现类,表示负载均衡:
public interface LoadBalance {
String select();
}
@Component
@Random
public class RandomStrategy implements LoadBalance {
@Override
public String select() {
return null;
}
}
@Component
@RoundRobin
public class RoundRobinStrategy implements LoadBalance {
@Override
public String select() {
return null;
}
}
使用:
@Component
public class UserService {
@Autowired
@RoundRobin
private LoadBalance loadBalance;
public void test() {
System.out.println(loadBalance);
}
}
这个时候使用的是@RoundRobin。
@Resource
@Resource注解底层工作流程图:
https://www.processon.com/view/link/5f91275f07912906db381f6e

















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









