



题目
200264, 17360, 200266, 3575, 553, 261, 10297, 29186, 200265, 200264, 1428, 200266, 8256, 5485, 668, 290, 9641, 13, 200265, 200264, 173781, 200266, 62915, 0, 7306, 382, 290, 9641, 25, 220, 15, 4645, 90, 67, 15, 22477, 15, 84, 62, 7316, 91, 15, 37313, 62, 10, 72, 42, 10, 525, 18, 77, 16, 57, 18, 81, 30, 92, 200265, 200264, 1428, 200266, 13659, 481, 0, 200265, 200264, 173781, 200266, 15334, 261, 1899, 1058, 540, 220, 15, 308, 69, 1323, 19, 0, 200265
solution
谷歌搜索开头的 5 个数字,会发现 tiktokenizer 的 web 项目(baidu飞马)。tiktokenizer-web
所以题干是 token_ids 的 list。前面是固定的 system prompt 所以可以搜索出来。用的是 gpt-4o 的模型
在 python pip 安装 tiktokenizer decode 得到结果
<|im_start|>system<|im_sep|>You are a helpful assistant<|im_end|><|im_start|>user<|im_sep|>Please tell me the flag.<|im_end|><|im_start|>assistant<|im_sep|>Sure! Here is the flag: 0ops{d0_Y0u_kr|0vv_+iK+ok3n1Z3r?}<|im_end|><|im_start|>user<|im_sep|>Thank you!<|im_end|><|im_start|>assistant<|im_sep|>Have a good time at 0ctf2024!<|im_end|>
但需要注意的是,直接跑 encoding_for_model(‘gpt-4o’) 的结果和网站的分词结果不一致。在 web 前端项目的源码搜索 gpt-4o,查找调库的接口,发现调用的是 o200k 然后额外指明了 3 个 token。写 decoder 的时候需要用 extending 的接口显式指定这三个 token。
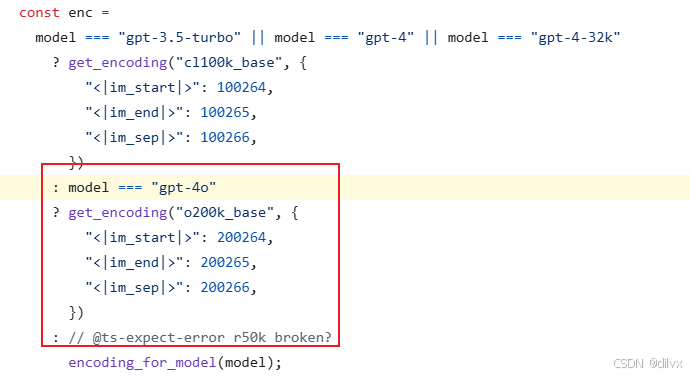
相当于 o200k_base 是通用的语言分词器,然后 openAI 再在上面微调制作 gpt
import tiktoken
o200k_base = tiktoken.get_encoding("o200k_base")
# In production, load the arguments directly instead of accessing private attributes
# See openai_public.py for examples of arguments for specific encodings
enc = tiktoken.Encoding(
# If you're changing the set of special tokens, make sure to use a different name
# It should be clear from the name what behaviour to expect.
name="cl100k_im",
pat_str=o200k_base._pat_str,
mergeable_ranks=o200k_base._mergeable_ranks,
special_tokens={
**o200k_base._special_tokens,
"<|im_start|>": 200264,
"<|im_end|>": 200265,
"<|im_sep|>": 200266,
},
)
# Ref: tiktoken - Extending tiktoken python docs and dqbd/tiktoken frontend project
numbers = [
...
]
print(enc.decode(numbers))
注:tiktoken.encoding_for_model 的实现是 get_encoding(encoding_name_for_model);而查找 name 的方法是前缀匹配查表。从表里可以看到,for_model 不会添加 token
MODEL_TO_ENCODING: dict[str, str] = {
# chat
"gpt-4o": "o200k_base",
"gpt-4": "cl100k_base",
"gpt-3.5-turbo": "cl100k_base",
"gpt-3.5": "cl100k_base", # Common shorthand
"gpt-35-turbo": "cl100k_base", # Azure deployment name
# base



















 5372
5372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









