



 本文深入探讨Python面向对象编程的高级概念,包括类成员、成员修饰符、特殊成员及异常处理,详解私有成员、属性定义及单例模式,适合进阶学习。
本文深入探讨Python面向对象编程的高级概念,包括类成员、成员修饰符、特殊成员及异常处理,详解私有成员、属性定义及单例模式,适合进阶学习。
通过上一篇博客我们已经对面向对象有所了解,下面我们先回顾一下上篇文章介绍的内容:
上篇博客地址:http://www.cnblogs.com/phennry/p/5606718.html
-
面向对象是一种编程方式,此编程方式的实现是基于对类和对象的使用;
-
类是一个模版,模板中包装了多个方法供使用(这里方法就是函数);
-
对象,根据模板创建的实例,实例用于调用被包装在类中的函数;
-
面向对象的三大特性:封装、继承、多态。
今天博客的内容主要介绍:Python类的成员、成员修饰符、类的特殊成员、异常处理和单例模式。下面开始今天的内容:
一、类的成员
类的成员可以分为三大类:字段、方法和属性。
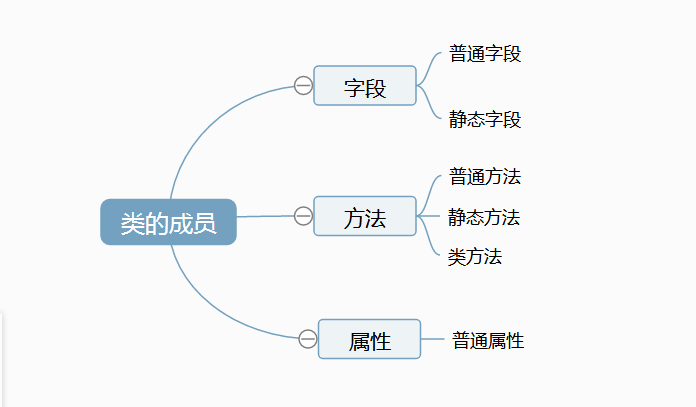
注:所有的成员中,只有普通字段的内容保存对象中,即:根据此类创建了多少对象,在内存中就有多少个普通字段;
其他成员,则都是保存在类中,即:无论对象的多少,在内存中只创建一份。
下面开始介绍类的成员:
(一)、字段
字段包括:普通字段和静态字段,他们定义和使用中有所区别,而最本质的区别是内存中保存的位置不同。
-
普通字段属于 对象
-
静态字段属于 类
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class
Func():
country
=
"中国"
#静态字段,保存在类里面
def
__init__(
self
,name):
self
.name
=
name
#普通字段,保存在对象里
#普通字段访问方法
hn
=
Func(
'河南'
)
print
(hn.name)
#静态字段访问方法
print
(Func.country)
|
由上述代码可以看出【普通字段需要通过对象来访问】【静态字段通过类访问】,在使用上可以看出普通字段的归属是不同的。其内部的存储方式类似下图:
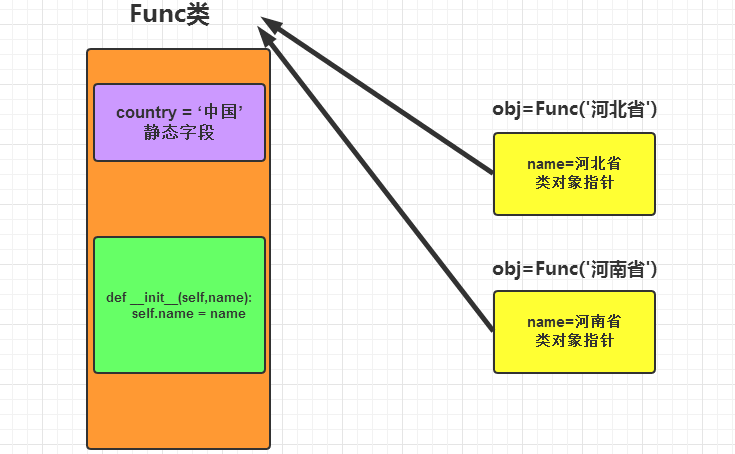
在Python中,可以通过类对象指针,找到类的静态字段。
字段的定义规则:
-
普通字段只能用对象访问;
-
静态字段用类访问(万不得已的时候可以使用对象访问),静态字段在代码加载时候,就已经创建。
(二)、方法
方法包括:普通方法、静态方法、类方法三种,三种方法在内存中都归属于类,区别在于调用方式不同。
-
普通方法:有对象调用;至少一个self参数;执行普通方法时,自动将调用该方法的对象赋值给self;
-
静态方法:有类调用;无默认参数;
-
类方法:有类调用;至少一个cls参数;执行类方法时,自动将该方法的类复制给self,即:cls为类名。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
class
Func():
country
=
"中国"
def
__init__(
self
,name):
self
.name
=
name
#self.name
def
show(
self
):
# 普通方法:由对象去调用执行(方法属于类),至少一个self
print
(
self
.name)
# 静态方法:不依赖任何对象,由类调用执行,任意参数
@staticmethod
#创建静态方法的时候要把self去掉,再方法的上面加上@staticmethod
def
f1(arg1,arg2):
print
(arg1,arg2)
@classmethod
#创建类方法,至少一个cls,cls是python自动传入的,
def
f2(
cls
):
#cls为类名,是一个类,不是一个字符串
print
(
cls
)
#调用普通方法:
obj
=
Func()
obj.show()
#调用静态方法:
Func.f1()
#调用类方法:
Func.f2()
|
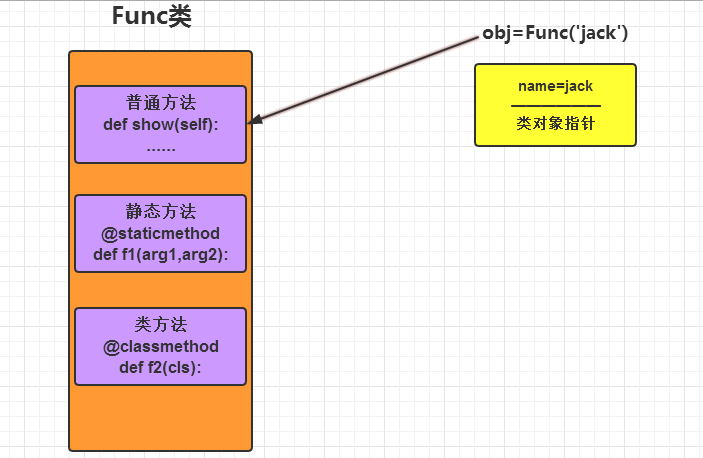
相同点:对于所有的方法而言,均属于类(非对象)中,所以在内存中只保存一份;
不同点:方法调用者不同、调用方法时自动传入的参数不同。
(三)、属性
python中属性其实就是普通方法的变种,这里我们介绍三个知识点:属性的基本使用,属性的两种定义方式。
1、属性的基本使用
|
1
2
3
4
5
6
7
8
9
10
11
12
|
class
Foo:
def
func(
self
):
pass
@property
#定义属性
def
prop(
self
):
pass
foo_obj
=
Foo()
#创建对象
foo_obj.func()
foo_obj.prop
#调用属性
|
定义方法:
-
定义时,在普通方法的基础上添加@property装饰器;
-
定义时,属性仅有一个self参数;
-
调用时,无需括号,方法调用时为foo_obj.func() ,调用属性时为foo_obj.prop
注意:属性存在意义是:访问属性可以制造出字段完全相同的假象,属性有方法变种而来,如果python中没有属性,方法完全可以代替其功能。
下面举个例子:
对于主机列表页面,每次请求不可能把数据库中的所有内容都显示到页面上,而是通过分页的功能局部显示,所以在向数据库数据时就要显示指定获取从第m到第n条的所有数据(即:limit m,n)这个分页的功能包括:
-
根据用户请求的当前页面和总数据条数计算出m和n;
-
根据m和n去数据库中请求数据。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
class
Pager:
def
__init__(
self
,current_page):
self
.current_page
#用户当前请求的页码(第一页、第二页...)
self
.per_items
=
10
#每页默认显示10条数据
@property
def
start(
self
):
val
=
(
self
.current_page
-
1
)
*
self
.per_items
return
val
@property
def
end(
self
):
val
=
self
.current_page
*
self
.per_items
p
=
Pager(
1
)
p.start
#起始值m
p.end
#结束值n
|
从上述可见,Python的属性的功能是:属性内部进行一系列的逻辑计算,最终将计算结果放回。
2、属性的两种定义方式
属性定义有两种方式:
-
装饰器:在方法上方应用装饰器;
-
静态字段:在类中定义值为property对象的静态字段。
装饰器的方式:
我们知道python2.*中的类有经典类和新式类,在python3.*中只有新式类,因为现在python3.*在企业中还没有广泛应用,这里先安装python2.*介绍:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#################经典类####################
class
Goods:
@property
#定义类属性
def
price(
self
):
return
"jack"
obj
=
Goods()
result
=
obj.price
#自动执行@property装饰的price方法,并获取方法的返回值
print
(result)
#结果:
jack
|
python2.*中的经典类,具有一种@property装饰器,如上例;下面来看一下新式类:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#################新式类#####################
class
Goods(
object
):
@property
def
price(
self
):
print
(
'get price'
)
@price
.setter
def
price(
self
,value):
print
(
'set price'
)
@price
.deleter
def
price(
self
):
print
(
'del price'
)
#调用方法:
obj
=
Goods()
obj.price
#自动执行@property修饰的price方法,并获取方法的返回值
obj.price(
123
)
#自动执行@property.setter修饰的price方法,并将123赋值给方法的参数
del
obj.price
#自动执行@property.deleter修饰的price方法,将方法删除
|
注: 经典类中的属性只有一种访问方式,其对应被@property修饰的方法;
新式类中的属性有三种访问方式,并分别对应了被@property、@方法名.setter、@方法名.deleter修饰的方法。
例子:
我们刚才知道了新式类具有三种你访问方式,下面通过属性的访问特点,取出商品的价格,修改商品的价格,和删除商品原价的操作,具体代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
class
Goods(
object
):
def
__init__(
self
):
self
.original_price
=
100
#原价
self
.discount
=
0.8
#折扣
@property
def
price(
self
):
new_price
=
self
.original_price
*
self
.discount
#实际价格 = 原价 * 折扣
return
new_price
@price
.setter
def
price(
self
,value):
self
.original_price
=
value
@price
.deleter
def
price(
self
):
del
self
.original_price
obj
=
Goods()
obj.price
#获取商品价格
obj.price
=
200
#修改商品价格
del
obj.price
#删除商品价格
|
静态字段的方式:
property的构造方法中有四个参数:
-
第一个参数是方法名,调用对象 ● 属性时自动触发执行方法 ;
-
第二个参数是方法名,调用对象 ● 属性 = xxx时自动触发执行方法;
-
第三个参数是方法名,调用del 对象 ● 属性时自动触发执行方法;
-
第四个参数是字符串,调用对象●属性.__doc__,此参数是该属性的描述信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
class
Goods(
object
):
def
__init__(
self
):
# 原价
self
.original_price
=
100
# 折扣
self
.discount
=
0.8
def
get_price(
self
):
# 实际价格 = 原价 * 折扣
new_price
=
self
.original_price
*
self
.discount
return
new_price
def
set_price(
self
, value):
self
.original_price
=
value
def
del_price(
self
):
del
self
.original_price
PRICE
=
property
(get_price, set_price, del_price,
'价格属性描述...'
)
obj
=
Goods()
ret
=
obj.PRICE
print
(ret)
obj.PRICE
=
200
ret1
=
obj.PRICE
print
(ret1)
del
obj.PRICE
|
所以,定义属性共用两种方式,分别是【装饰器方式】和【静态字段】,而【装饰器方式】针对经典类和新式类又有所不同。
二、类成员的修饰符
类的所有成员在上一步骤已经做了详细介绍,对于每一个类的成员而言都是有两种形式的:
-
公有成员:在任何地方都能访问;
-
私有成员:只有在类的内部才能访问。
私有成员和公有成员的定义不同:私有成员时,前两个字符是下划线(类似:__init__、__call__、__dict__等)
|
1
2
3
4
5
|
class
Foo:
def
__init__(
self
):
self
.name
#公有字段
self
.__name
#私有字段
|
私有成员和公有成员的访问权限不同:
静态字段:
-
公有静态字段:类可以访问,类内容部也可以访问,派生类中也可以访问;
-
私有静态字段:仅类内部可以访问。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class
C:
name
=
"jack"
#定义公有静态字段
def
func(
self
):
print
C.name
class
D(C):
def
show(
self
):
print
C.name
C.name
#类可以直接访问
obj
=
C()
obj.func()
#类内部也可以访问
obj_son
=
D()
obj_son.show()
#派生类也可以访问
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class
C:
__name
=
"jack"
#定义的私有静态字段
def
func(
self
):
print
C.__name
class
D(C):
def
show(
self
):
print
C.__name
C.__name
#这样直接类访问,是无法访问的
obj
=
C()
#类内部的方法调用是可以访问的
obj.func()
obj_son
=
D()
obj_son.show()
#派生类中也是不能访问的
|
普通字段:
-
公有普通字段:类可以访问,类内容部也可以访问,派生类中也可以访问;
-
私有普通字段:仅类内部可以访问。
注意:如果想要强制访问私有字段,可以通过【对象.__类名__私有字段名】访问(如:obj.__C__foo),但不建议强制访问私有成员。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class
C:
def
__init__(
self
):
self
.foo
=
"jack"
# 定义公有普通字段
def
func(
self
):
print
(
self
.foo)
# 类内部可以直接访问
class
D(C):
def
show(
self
):
print
(
self
.foo)
#派生类中访问
obj
=
C()
print
(obj.foo)
# 通过对象直接访问
obj.func()
# 通过调用类中的方法访问
obj_son
=
D()
obj_son.show()
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class Foo
:
def
__init__(
self
):
self
.__name
=
"jack" #定义私有普通字段
def
func(
self
):
print
(
self
.__name)
class Bar
(Foo):
def
show(
self
):
print
(
self
.__name)
obj
= Bar
("jack")
obj.show() #私有成员修饰符是无法继承的,只有自己可以访问
obj.func() #通过继承父类的方法是可以访问的
|
下面介绍一个使用私有成员修改静态方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class
Func():
country
=
"中国"
def
__init__(
self
,name):
self
.name
=
name
def
show(
self
):
print
(
self
.name)
@staticmethod
def
__f1():
print
(
"jack"
)
def
f2(
self
):
print
(Func.__f1())
obj
=
Func(
'jack'
)
obj.__f1()
#直接访问静态方法报错
obj.f2()
#在内部调用可以正常访问
|
三、类的特殊成员
上面介绍了Python的类成员以及成员修饰符,从而了解到类中有字段、方法和属性三大类成员,并且成员名前如果有两个下划线,则表示私有成员,私有成员只能有类内部调用;无论人或者事物往往都有不按套路出牌的情况,Python的类成员也是如此,存在着一些具有特殊含义的成员,下面我们详细介绍一下:
1、__doc__:表示类的描述信息
|
1
2
3
4
5
6
|
class
Foo:
"""此类,为学生类"""
def
func(
self
):
pass
print
(Foo.__doc__)
#输出类的描述信息
|
2、__init__:构造方法,通过类创建对象时,自动触发执行。
|
1
2
3
4
5
6
7
|
class
Foo:
def
__init__(
self
,name):
self
.name
=
name
self
.age
=
19
obj
=
Foo(
'jack'
)
#创建对象时,会自动触发类中的__init__方法
|
3、__del__:析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都交给了python解释器类执行,所以析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
4、__call__:对象后面加括号,触发执行
注:构造方法的执行是由创建对象触发的,即:对象=类名();而对于__call__方法的执行是由对象后加括号触发的,即:对象()或者类名()()
|
1
2
3
4
5
6
7
8
9
10
11
12
|
class
Foo:
def
__init__(
self
,name):
self
.name
=
name
self
.age
=
18
def
__call__(
self
):
print
(
'call'
)
obj
=
Foo(
"jack"
)
obj()
#对象后面加(),会执行call方法
Foo(
"jack"
)()
#或者类后面加两个括号也是会执行call方法
|
5、__dict__:获取对象中封装的数据
从上文我们知道,类的普通字段属于对象;类中的静态字段和方法等属于类,即:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
class
Province:
country
=
"China"
def
__init__(
self
,name,count):
self
.name
=
name
self
.count
=
count
def
func(
self
,
*
args,
*
*
kwargs):
print
(
"func"
)
print
(Province.__dict__)
#获取类的成语,即:静态方法、方法
#结果:
#{'__init__': <function Province.__init__ at 0x000001C3F419D510>, 'country': 'China', '__dict__': <attribute '__dict__' of 'Province' objects>, '__doc__': None, '__weakref__': <attribute '__weakref__' of 'Province' objects>, 'func': <function Province.func at 0x000001C3F419D598>, '__module__': '__main__'}
obj
=
Province(
'Hebei'
,
1000
)
#获取对象obj的成员
print
(obj.__dict__)
#结果:{'name': 'Hebei', 'count': 1000}
obj1
=
Province(
'beijing'
,
50000
)
#获取对象obj1的成员
print
(obj1.__dict__)
#结果:{'name': 'beijing', 'count': 50000}
|
6、__module__和__class__
-
__module__:表示当前操作的对象在那个模块
-
__class__:表示当前操作的对象的类是什么
|
1
2
3
4
5
6
|
#test.py 测试模块
class
Foo:
def
__init__(
self
):
self
.name
=
"jack"
|
|
1
2
3
4
5
6
|
from
Day8.test
import
Foo
obj
=
Foo()
print
(obj.__module__)
#输出Day8.test 即:输出模块名
print
(obj.__class__)
#输出<class 'Day8.test.Foo'> 即:输出类
|
7、__str__:如果一个类中定义了__str方法,那么在打印对象时,默认输出该方法的返回值。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class
Foo:
#构造方法
def
__init__(
self
,name,age):
self
.name
=
name
self
.age
=
age
def
__str__(
self
):
return
"%s - %s"
%
(
self
.name,
self
.age)
obj1
=
Foo(
'alex'
,
18
)
obj2
=
Foo(
'eric'
,
19
)
print
(obj1)
#直接打印对象,会执行__str__(如果没有调用对象的方法,会直接打印一个内存地址,并不友好,如果定义了__str__方法,会自动执行__str__方法)
print
(obj2)
#结果:
alex
-
18
eric
-
19
|
8、__getitem__、__setitem__、__delitem__:用于索引操作,如字典,分别为获取、设置和删除。
注:这个模块python2.*和python3.*中有不同之处,python3.*中直接可以通过上述三种方法进行切片操作,而python2.*中需要调用另外三种方法:__getslice__、__setslice__、__delslice__进行切片操作。
python3.*操作方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class
Foo(
object
):
def
__getitem__(
self
, key):
print
(
'__getitem__'
,key)
def
__setitem__(
self
, key, value):
print
(
'__setitem__'
,key,value)
def
__delitem__(
self
, key):
print
(
'__delitem__'
,key)
obj
=
Foo()
result
=
obj[
'k1'
]
# 自动触发执行 __getitem__
obj[
'k2'
]
=
'jack'
# 自动触发执行 __setitem__
del
obj[
'k1'
]
#自动触发执行 __delitem__
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
class
Foo:
#构造方法
def
__init__(
self
,name,age):
self
.name
=
name
self
.age
=
age
def
__getitem__(
self
, item):
print
(
type
(item))
#以切片格式取值时,这里的类型为slice
print
(item.start)
#获取切片的起始位置
print
(item.stop)
#获取切片的截至位置
print
(item.step)
#获取切片的步长
return
123
def
__setitem__(
self
, key, value):
print
(
'setitem'
)
def
__delitem__(
self
, key):
print
(
'delitem'
)
obj1
=
Foo(
'jack'
,
18
)
ret1
=
obj1[
1
:
4
:
2
]
#以切片的方式取值
obj1[
1
:
4
]
=
[
11
,
22
,
33
,
44
,
55
]
del
obj1[
1
:
4
]
#结果:
<
class
'slice'
>
1
4
2
setitem
delitem
|
python2.*执行方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class
Foo(
object
):
def
__getslice__(
self
, i, j):
print
'__getslice__'
,i,j
def
__setslice__(
self
, i, j, sequence):
print
'__setslice__'
,i,j
def
__delslice__(
self
, i, j):
print
'__delslice__'
,i,j
obj
=
Foo()
obj[
-
1
:
1
]
# 自动触发执行 __getslice__
obj[
0
:
1
]
=
[
11
,
22
,
33
,
44
]
# 自动触发执行 __setslice__
del
obj[
0
:
2
]
# 自动触发执行 __delslice__
|
9、__iter__:用于迭代器,之所以列表、字典、元组可以进行for循环,是因为内部定义了__iter__。
|
1
2
3
4
5
6
7
8
9
10
|
class
Foo:
def
__iter__(
self
):
#__iter__方法会有一个返回值为迭代器,有yield的为生成器,也可以使用return iter([11,22,33,44])
yield
1
yield
2
obj
=
Foo()
for
item
in
obj:
#当循环一个对象的时候会默认执行类里面的__iter__方法
print
(item)
|
10、__new__和__metaclass__
阅读以下代码:
|
1
2
3
4
5
6
|
class
Foo(
object
):
def
__init__(
self
):
pass
obj
=
Foo()
#obj是Foo类实例化的对象
|
上述代码中,obj是通过Foo类实例化的对象,其实不仅obj是一个对象,Foo类本身也是一个对象,因为在python中一切事物都是对象。
如果按照一切事物都是对象的理论:obj对象通过执行Foo类的构建方法创建,那么Foo类对象应该也是通过执行某个类的构造方法来创建的。
|
1
2
3
4
5
6
|
print
(
type
(obj))
print
(
type
(Foo))
#结果:
<
class
'__main__.Foo'
>
#表示,obj对象是Foo类创建的
<
class
'type'
>
#Foo类对象是type类创建的
|
所以,obj对象是Foo类的一个实例,Foo类对象是type类的一个实例,即:Foo类对象是通过type类的构造方法创建的。
那么创建类就有两种方式:
(1)、普通方式
|
1
2
3
4
|
class
Foo(
object
):
def
func(
self
):
print
(
'hello'
)
|
(2)、特殊方式(type类的构造函数)
|
1
2
3
4
5
6
7
8
|
def
func(
self
):
print
(
'hello'
)
Foo
=
type
(
'Foo'
,(
object
,),{
'func'
:func})
#type第一个参数:类名
#type第二个参数:当前类的基类(父类)
#type第三个参数:类的成员
|
那么问题来了,类默认是由type类实例化产生的,type类中如何实现的创建类,类又是如何创建对象呢?
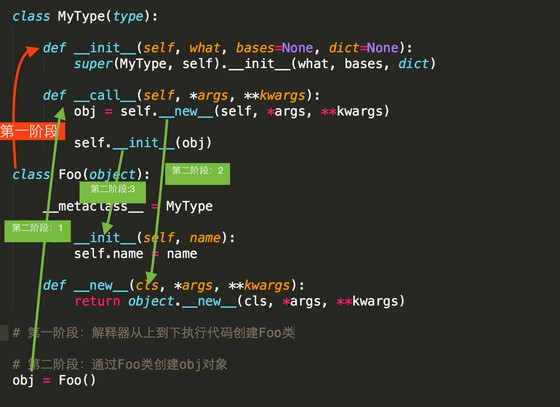
类中有一个属性__metaclass__,其用来表示该类由谁来实例化创建,所以我们可以为__metaclass__设置一个type类的派生类,从而查看类创建的过程。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
class
MyType(
type
):
def
__init__(
self
, what, bases
=
None
,
dict
=
None
):
super
(MyType,
self
).__init__(what, bases,
dict
)
def
__call__(
self
,
*
args,
*
*
kwargs):
obj
=
self
.__new__(
self
,
*
args,
*
*
kwargs)
self
.__init__(obj)
class
Foo(
object
):
__metaclass__
=
MyType
def
__init__(
self
, name):
self
.name
=
name
def
__new__(
cls
,
*
args,
*
*
kwargs):
return
object
.__new__(
cls
,
*
args,
*
*
kwargs)
# 第一阶段:解释器从上到下执行代码创建Foo类
# 第二阶段:通过Foo类创建obj对象
obj
=
Foo()
|
上面介绍的是__metaclass__方法,下面我们介绍一下__new__方法:
继承自object的新式类才有__new__方法,__new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时有Python解释器自动提供。
注:__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类__new__出来的实例,或者直接object的__new__出来的实例。
看网上很多人拿__init__和__new__做对比,大家都知道__init__有一个参数self,其实这个参数就是__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__
不需要返回值,若__new__没有正确返回当前类cls的实例,那__init__是不会调用的,即使是父类的实例也不行。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class
A(
object
):
pass
class
B(A):
def
__init__(
self
):
print
"init"
def
__new__(
cls
,
*
args,
*
*
kwargs):
print
"new %s"
%
cls
return
object
.__new__(A,
*
args,
*
*
kwargs)
b
=
B()
print
type
(b)
#输出:
new <
class
'__main__.B'
>
<
class
'__main__.A'
>
|
补充:
下面补充两个与类相关的两个内置函数:
1、isinstance(obj, cls) :检查obj是否是cls的对象
|
1
2
3
4
5
6
7
8
9
10
11
|
class
Bar:
pass
class
Foo(Bar):
pass
obj
=
Foo()
#obj,Bar(obj类型和obj类型的父类)的实例
ret
=
isinstance
(obj,Bar)
#它既可以判断是不是Foo对象,也可以判断是不是Foo父类的对象
print
(ret)
#输出:True
|
2、issubclass(sub, super) :检查sub类是否是super类的派生类
|
1
2
3
4
5
6
7
8
9
|
class
Bar:
pass
class
Foo(Bar):
pass
ret
=
issubclass
(Foo,Bar)
print
(ret)
#输出:True
|
今天介绍的内容就到这里,以上就是面向对象进阶篇的所有内容,谢谢大家。

















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









