




大数据框架实例(Hadoop 原理总结)
- 简介
Hadoop是一个开发和运行处理大规模数据的软件平台,实现了在大量的廉
价计算机组成的集群中对海量数据进行分布式计算。
大概工作流程如下图:
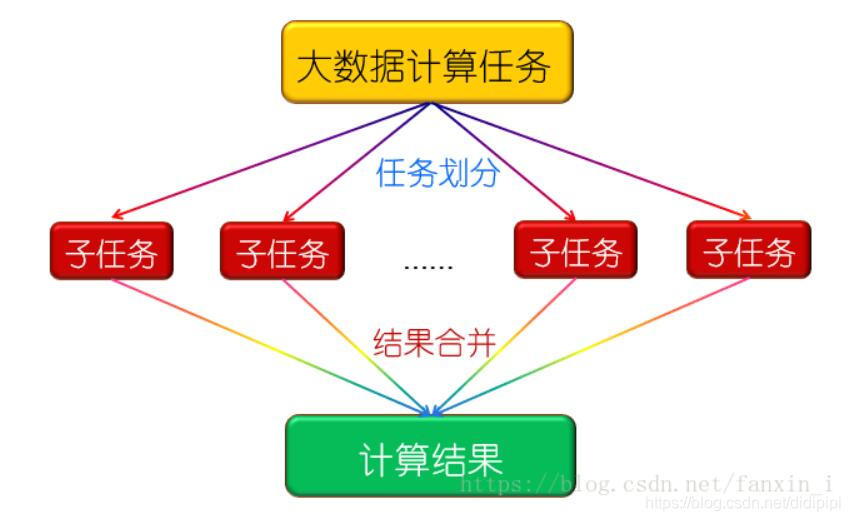
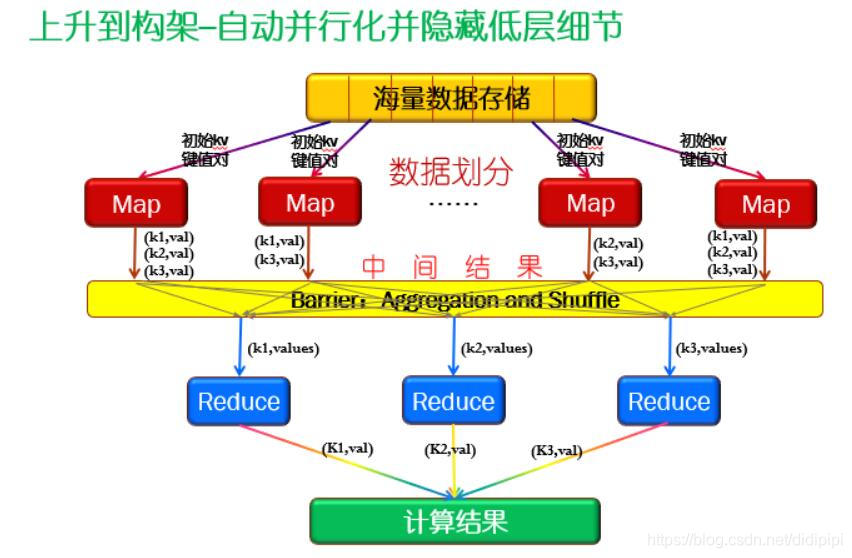
Hadoop框架中最核心的设计是HDFS(文件系统)和MapReduce(编程模型,大数据并行运算)。
二、HDFS(文件系统)
1、HDFS简介
HDFS即Hadoop Distributed File System:分布式文件存储系统,为海量的数据提供了存储,HDFS:其实就是个文件系统,和fastDFS类似,像百度云,阿里云等就是个文件存储系统,当然一般如果仅仅是为了用来存储文件的话直接fastDFS这个就已经够了,HDFS目的不单单是用来存储文件这么简单,它还涉及分布式计算等。
2、HDFS结构
HDFS 由一个管理结点 ( NameNode )和N个数据结点 ( DataNode )组成,
NameNode
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间。
NameNode基于内存存储,存储的是一些文件的详细信息,比如文件名、文件大小、创建时间、文件位置等。NameNode 也是整个 HDFS 的核心,它通过维护一些数据结构,记录了每一个文件被切割成了多少个 Block,这些 Block 可以从哪些 DataNode 中获得,各个 DataNode 的状态等重要信息。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2185
2185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









