






Link of the Paper: https://arxiv.org/abs/1412.2306
Main Points:
- An Alignment Model: Convolutional Neural Networks over image regions ( An image -> RCNN -> Top 19 detected locations in addition to the whole image -> the representations based on the pixels Ib inside each bounding box -> a set of h-dimensional vectors {vi | i = 1 ... 20} ), Bidirectional Recurrent Neural Networks over sentences, and a structured objective that aligns the two modalities through a multimodal embedding ( CNN - Structured Objective - BiRNN ).
- A Multimodal Recurrent Neural Network architecture: On the image side, Convolutional Neural Networks ( CNNs ) have recently emerged as a powerful class of models for image classification and object detection. On the sentence side, our work takes advantage of pretrained word vectors to obtain low-dimensional representations of words. Finally, Recurrent Neural Networks have been previously used in language modeling, but we additionally condition these models on images.
- Authors use bidirectional recurrent neural network to compute word representations in the sentence, dispensing of the need to compute dependency trees and allowing unbounded interactions of words and their context in the sentence.
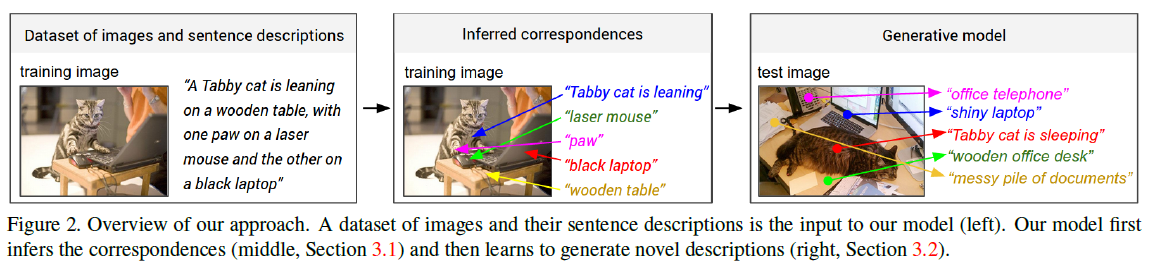

Other Key Points:
- The primary challenge towards generating descriptions of images is in the design of a model that is rich enough to simultaneously reason about contents of images and their representation in the domain of natural language. Additionally, the model should be free of assumptions about specific hard-coded templates, rules or categories and instead rely on learning from the training data. The second, practical challenge is that datasets of image captions are available in large quantities on the internet, but these descriptions multiplex mentions of several entities whose locations in the images are unknown.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









