






 本文介绍了使用C#实现随机数计算器的过程,包括环境配置、代码设计思路、问题解决及单元测试等内容。作者通过博客记录了从安装配置到代码实现再到测试的全过程。
本文介绍了使用C#实现随机数计算器的过程,包括环境配置、代码设计思路、问题解决及单元测试等内容。作者通过博客记录了从安装配置到代码实现再到测试的全过程。
| GIT地址 | https://github.com/thisverybigcat/AchaoCalculator |
| GIT用户名 | thisverybigcat |
| 学号后五位 | 62303 |
| 博客地址 | https://www.cnblogs.com/wyj1208/ |
| 作业链接 | https://edu.cnblogs.com/campus/xnsy/SoftwareEngineeringClass1/homework/2864 |
- 请以博客记录的方式,体现环境配置过程(包括遇到了哪些问题,你是如何解决的)
- 在大二上学期的学习中我们已经按照要求安装成功了VS2017版本,并且配置是完善的C#,以下是最终配置成果截图。
- 体现你代码设计的思路(注意:请保证代码能够运行通过)
- 本次实验中因为头一回拿到随机数问题而陷入了很长时间的纠结,感谢被我纠缠的诸多大佬的帮助和讲解,以及被我纠缠帮我指出不少错误的各位大佬们,使我有现在这个还算完善的代码。
- 通过转换函数输入了所需题目数量后, 利用循环函数开始逐一生成算式,算式生成即进行检验,成功则输入文件,错误则重新生成,直到符合要求的算式达到数量要求。
- 形成算式使用的是借助数组下标的方法,将符号仿佛数组,利用随机数生成数组下标,再使用循环和StringBuilder生成算式
- 大佬指点下我通过百度谷歌等搜索引擎学习了可以直接计算字符串相加的compute函数,可以直接在字符串后进行添加的StringBuilder,Random(Guid.NewGuid().GetHashCode())不生成重复随机数。
- 因为上学期就对于文件的学习过于薄弱,以至于后续陷入了很多的文件问题,首先是无法将内容输入文件,后来又出现文件中只有一个算式的情况(即覆盖),把书和百度翻了个底朝天后,最后在请教大佬才知道是使用了错误指令,一个简单的问题却困扰了我大半天,实在是对于我基础薄弱的坚实证明......
- 核心代码如下
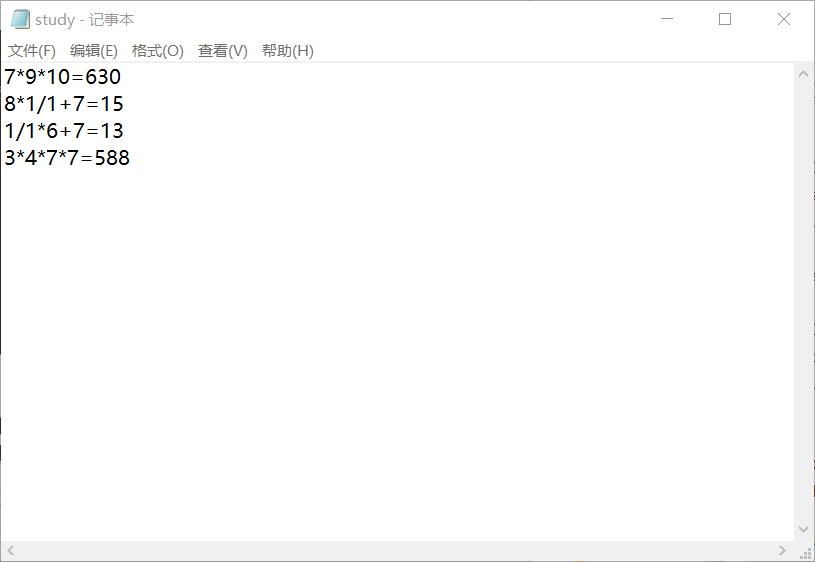
- 生成算式


运算

-
输入文件

运行结果

- 记录你使用github克隆项目以及提交代码的整个过程(包括遇到的问题,你是如何解决的)
- 安装过程中出现了小问题,我当时使用浏览器直接下载git安装包,下载三四次后点击安装都会被系统阻拦,我选择继续运行后便会提示我安装包已经损毁,请再次下载,如此反复我只能上群求助,在经历关闭杀软加入白名单再次下载后依旧不行,最后在大佬告知下使用了迅雷进行下载,不仅下载迅速,并且落地即安装成功(在此诚挚建议大家,别用浏览器下载了,用的我快气死了)
- 克隆以及提交过程我依照作业内要求步骤顺利提交,中途并未遇到什么问题。
- 记录你对项目进行单元测试和回归测试的过程(包括你遇到的问题,解决的方法是什么)
- 进行单元测试时,我着重测试了一下判断函数,尤其是对于出现小数的判断,判断函数我写的很简单,测试也顺利通过。
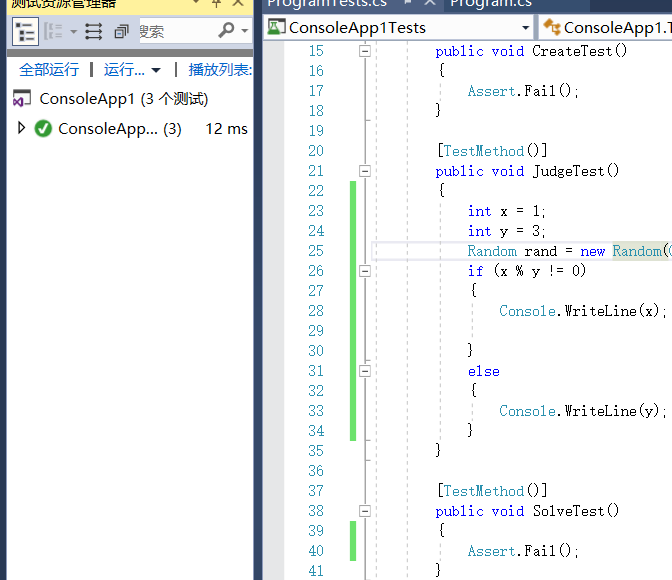
-
断点测试可以很方便的看出程序到底哪里出错了,能比较有效率的排查出一些循环逻辑问题。回归测试能检查出代码的效能退化,因此每改动一次代码时都应该进行一次回归测试。
- 根据作业要求步骤做了效能测试
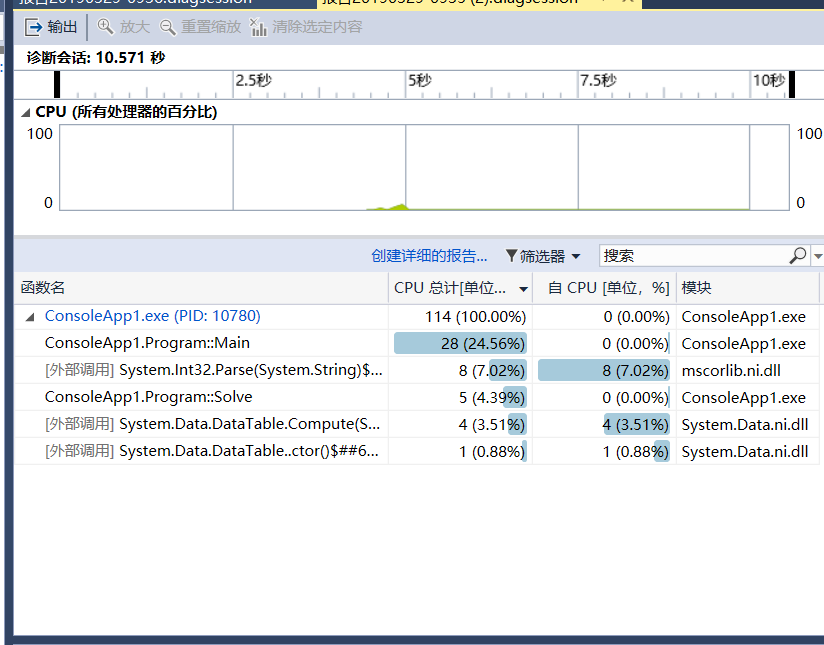
你对本次工具的熟悉过程,有什么感想?分享你学习到的新知识
本次实验中我接触了新的工具Git,并且尝试了很多之前并不熟悉的C#指令,而测试也是一个全新的知识点,对于软件工程中的步骤更加熟悉,最大的缺点大概就是我的英语不好,使我在使用GIT的时候各种犯错,而对于C#的很多新指令想要熟练运用也需要更多的练习。

















 3660
3660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









