






参考:
we highly recommend you to switch to use Dataset, which has better performance than RDD
第一要务:创建 SparkContext
连接到Spark"集群":local,standalone,yarn,mesos
通过SparkContext来创建RDD、广播变量到集群
在创建SparkContext之前需要创建一个SparkConf对象
进入spark的bin目录下
./pyspark
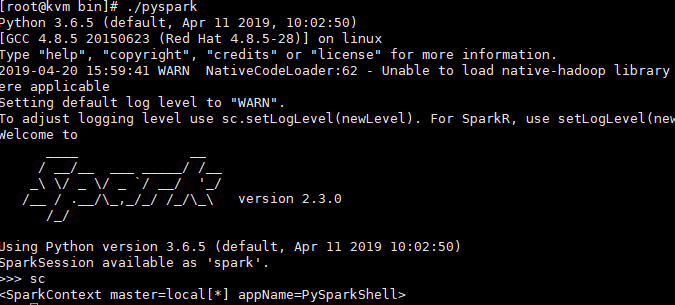
In the PySpark shell, a special interpreter-aware SparkContext is already created for you, in the variable called sc.
appName
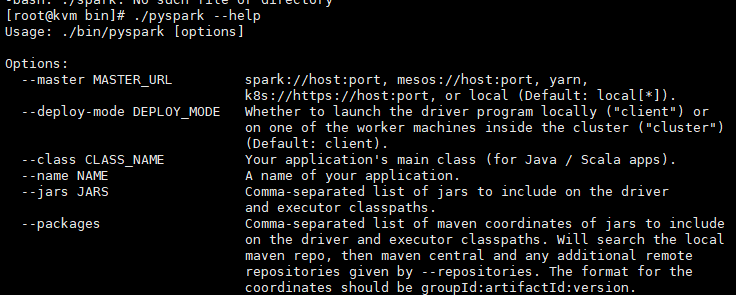
./pyspark --help 查看帮助
RDD创建方式
Parallelized Collections
data = [1, 2, 3, 4, 5] distData = sc.parallelize(data)
External Datasets
distFile = sc.textFile("file:root/app/test/hello.txt")
If using a path on the local filesystem, the file must also be accessible at the same path on worker nodes


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









