






前言
经过需求概述的分析,如果要实现一套代码适配多种数据库,因为service层要调用dao层,dao层调用mapper.xml,所以service层、dao层、mapper.xml会受到适配多种数据库方案的影响,我们先从最简单的方案:service层、dao层、mapper.xml全部改动开始,然后分析该方案的优缺点,针对该方案缺点进行方案升级,及过程中遇到的问题和解决思路,按照这个思路不断升级并形成最终方案。
一、初步方案概述
最简单的方案莫过于根据不同的数据库创建不同的dao层和mapper.xml,然后在service层根据当前数据库驱动类型调用对应的dao层接口。所以大概步骤如下:
- 准备新数据库环境
- 添加新数据库驱动依赖
- 添加新数据库连接配置
- 创建不同数据库适配的dao层接口及其实现mapper.xml
- service层创建不同数据库的dao层接口对象;根据当前配置的数据库驱动类型,选择适用的dao层接口
- 使用不同的数据库测试
二、项目改造
1、示例项目简介
如果自己有项目,可以在自己项目上测试,如果没有或者不想在自己项目测试,可以使用本文提供的示例项目。
- 开发框架:Spring Boot 2.7.18
- 持久层框架:MyBatis 3.5.6
- 数据库连接池:Druid 1.2.6
- 数据库:MySQL 5.7
- 数据库驱动:com.mysql.cj.jdbc.Driver 8.0.33
- 下载示例项目后先看README.md
- 功能简介:用户查询功能,数据库:demo,表:user,列:id、name
- 项目需求:添加PostgreSQL数据库(版本10+)的支持
2、项目改造
-
如果使用示例项目,先根据README.md正确运行示例项目
-
准备PostgreSQL数据库环境(版本10+),使用其他数据库环境也可以,根据实际情况选择
-- ---------------------------- -- postgres_user.sql概述:数据库:demo,模式:multi_database,表:user,自增主键:id,列:name -- ---------------------------- DROP TABLE IF EXISTS "multi_database"."user"; CREATE TABLE "multi_database"."user" ( "id" int8 NOT NULL GENERATED BY DEFAULT AS IDENTITY ( INCREMENT 1 MINVALUE 1 MAXVALUE 9223372036854775807 START 1 CACHE 1 ), "name" varchar(32) COLLATE "pg_catalog"."default" ) ; COMMENT ON COLUMN "multi_database"."user"."id" IS '主键'; COMMENT ON COLUMN "multi_database"."user"."name" IS '名称'; -- ---------------------------- -- Records of user -- ---------------------------- INSERT INTO "multi_database"."user" VALUES (1, '张三'); INSERT INTO "multi_database"."user" VALUES (2, '李四'); INSERT INTO "multi_database"."user" VALUES (3, '王二'); INSERT INTO "multi_database"."user" VALUES (4, '麻子'); -- ---------------------------- -- Auto increment value for user -- ---------------------------- SELECT setval('"multi_database"."user_id_seq"', 4, true); -- ---------------------------- -- Primary Key structure for table user -- ---------------------------- ALTER TABLE "multi_database"."user" ADD CONSTRAINT "user_pkey" PRIMARY KEY ("id"); -
添加PostgreSQL驱动依赖
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
- 修改为PostgreSQL数据库连接配置
# 数据库配置 TODO 根据实际情况修改
database:
ip: xxx
# mysql: 3306 ;postgres: 5432
port: 5432
database: demo
# postgres需要
schema: multi_database
username: xxx
password: xxx
# mysql: com.mysql.cj.jdbc.Driver ;postgres: org.postgresql.Driver
driver-class-name: org.postgresql.Driver
# mysql: jdbc:mysql://${database.ip}:${database.port}/${database.database}?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=GMT%2B8
# postgres: jdbc:postgresql://${database.ip}:${database.port}/${database.database}?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8&¤tSchema=${database.schema},sys_catalog
url: jdbc:postgresql://${database.ip}:${database.port}/${database.database}?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8&¤tSchema=${database.schema},sys_catalog
# 数据源配置
spring:
datasource:
# 数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: ${database.driver-class-name}
url: ${database.url}
username: ${database.username}
password: ${database.password}
- 创建UserPgMapper.java,文件内容与 UserMapper.java保持一致
package com.yu.dao;
import com.yu.entity.User;
import java.util.List;
public interface UserPgMapper {
/**
* 查询用户列表
*
* @param user 搜索条件
* @return 用户列表
*/
List<User> list(User user);
}
- 创建UserPgMapper.xml,内容如下
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.yu.dao.UserPgMapper">
<resultMap type="User" id="BaseResultMap">
<id property="id" column="id"/>
<result property="name" column="name"/>
</resultMap>
<sql id="Base_Column_List">
select
id,
name
<!--TODO 特别注意,系统也有user表,所以这里需要加上模式-->
from multi_database.user
</sql>
<select id="list" parameterType="User" resultMap="BaseResultMap">
<include refid="Base_Column_List"/>
<where>
<if test="name != null and name != ''">
and name like concat('%', #{name}, '%')
</if>
</where>
</select>
</mapper>
- service层创建不同数据库的dao层接口对象,根据驱动类型调用dao层接口
package com.yu.service.impl;
import com.yu.dao.UserMapper;
import com.yu.dao.UserPgMapper;
import com.yu.entity.User;
import com.yu.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserServiceImpl implements UserService {
private static final String MYSQL = "com.mysql.cj.jdbc.Driver";
private static final String POSTGRESQL = "org.postgresql.Driver";
@Value("${spring.datasource.driver-class-name}")
private String driverClass;
@Autowired
private UserMapper userMapper;
@Autowired
private UserPgMapper userPgMapper;
@Override
public List<User> list(User user) {
if (MYSQL.equals(driverClass)) {
return userMapper.list(user);
} else if (POSTGRESQL.equals(driverClass)) {
return userPgMapper.list(user);
}
return null;
}
}
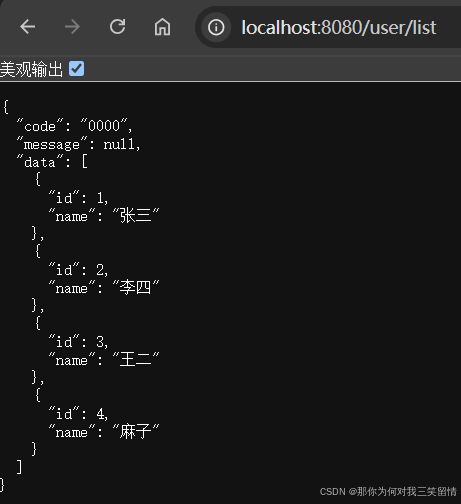
- 使用PostgreSQL数据库测试接口,访问获取用户列表接口 http://localhost:8080/user/list
三、方案总结
从上面修改情况来看,还是相当麻烦的,总结该方案的缺点如下:
- 重复代码太多
- mapper.java除了文件名不一样,其他全部一样,不管是扩展新功能还是升级旧功能,需要做好多没有价值的工作。
- mapper.xml重复也不少,即使有不同数据库使用相同的语法,也无法做到重用,必须copy一遍。
- Service层改动较大
- service层本身就是事务层,会有较多地方操作mapper,现在每次调用mapper之前需要判断当前数据库类型,本身工作量就很大,在新添加数据库类型时这部分工作又需要再做一遍,而且没什么价值,提升不了专业技能。
- 下文针对该缺点提出升级思路,升级过程中遇到的问题,及解决问题的思路,并形成升级方案。


















 2076
2076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











