



 本文介绍了Zookeeper和Redis两种实现分布式锁的方法。Zookeeper利用顺序临时节点和Watch机制确保锁的一致性和可靠性。Redis则通过Redlock算法在集群环境中提供高性能且可靠的分布式锁。
本文介绍了Zookeeper和Redis两种实现分布式锁的方法。Zookeeper利用顺序临时节点和Watch机制确保锁的一致性和可靠性。Redis则通过Redlock算法在集群环境中提供高性能且可靠的分布式锁。
Zookeeper 实现分布式锁
Zookeeper 是一种提供“分布式服务协调“的中心化服务,正是 Zookeeper 的以下两个特性,分布式应用程序才可以基于它实现分布式锁功能。
顺序临时节点
:Zookeeper 提供一个多层级的节点命名空间(节点称为 Znode),每个节
点都用一个以斜杠(/)分隔的路径来表示,而且每个节点都有父节点(根节点除外),非
常类似于文件系统。
节点类型可以分为持久节点(PERSISTENT )、临时节点(EPHEMERAL),每个节点还能
被标记为有序性(SEQUENTIAL),一旦节点被标记为有序性,那么整个节点就具有顺序
自增的特点。一般我们可以组合这几类节点来创建我们所需要的节点,例如,创建一个持久
节点作为父节点,在父节点下面创建临时节点,并标记该临时节点为有序性
Watch 机制:
Zookeeper 还提供了另外一个重要的特性,Watcher(事件监听器)。
ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,
ZooKeeper 服务端会将事件通知给用户
Zookeeper 是如何实现分布式锁
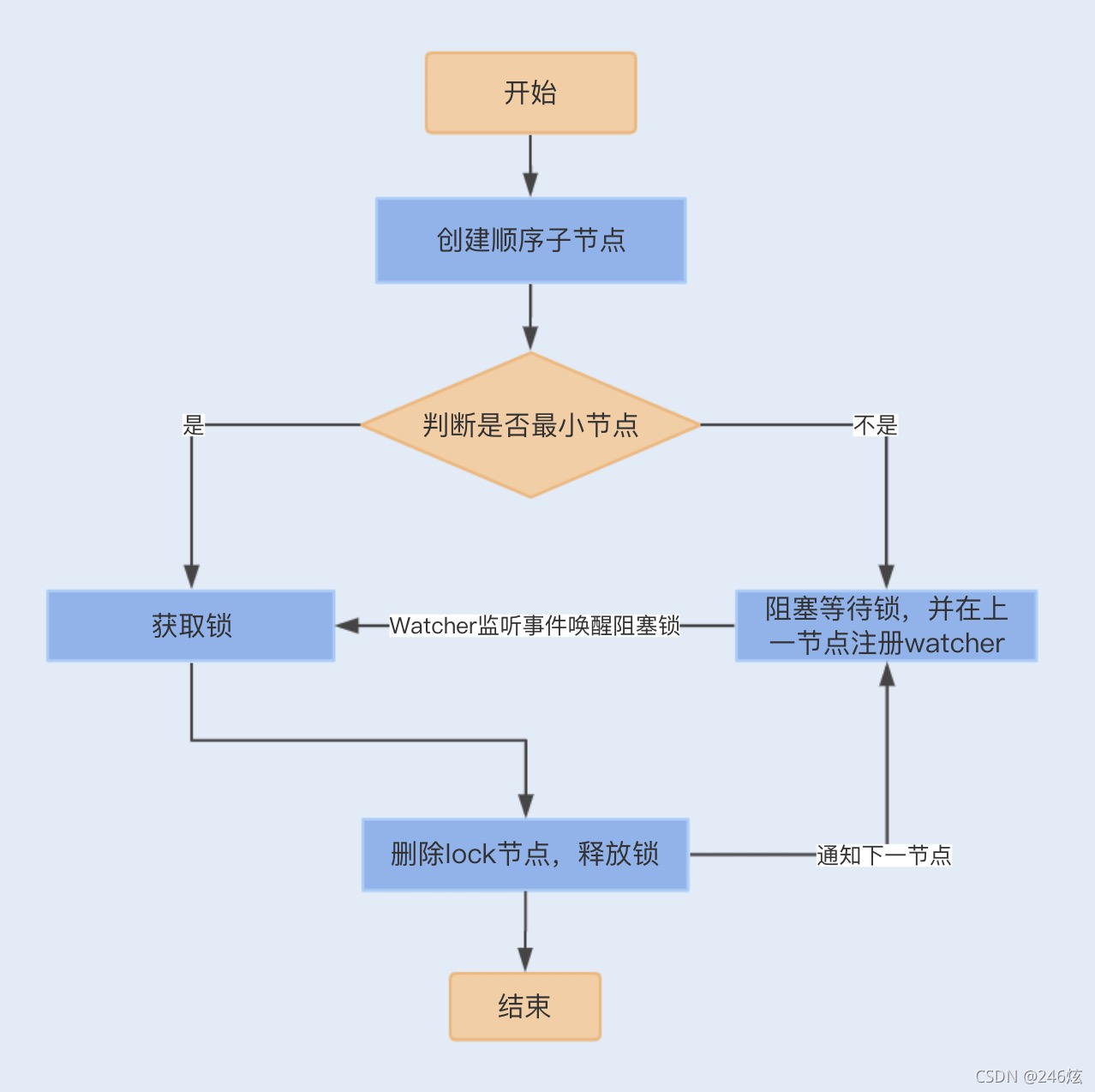
首先,我们需要建立一个父节点,节点类型为持久节点(PERSISTENT) ,每当需要访问
共享资源时,就会在父节点下建立相应的顺序子节点,节点类型为临时节点
(EPHEMERAL),且标记为有序性(SEQUENTIAL),并且以临时节点名称 + 父节点名
称 + 顺序号组成特定的名字。
在建立子节点后,对父节点下面的所有以临时节点名称 name 开头的子节点进行排序,判
断刚刚建立的子节点顺序号是否是最小的节点,如果是最小节点,则获得锁。
如果不是最小节点,则阻塞等待锁,并且获得该节点的上一顺序节点,为其注册监听事件,
等待节点对应的操作获得锁。
当调用完共享资源后,删除该节点,关闭 zk,进而可以触发监听事件,释放该锁。
Redis 实现分布式锁
相对于前两种实现方式,基于 Redis 实现的分布式锁是最为复杂的,但性能是最佳的
Redlock 算法
Redisson 由 Redis 官方推出,它是一个在 Redis 的基础上实现的 Java 驻内存数据网格
(In-Memory Data Grid)。它不仅提供了一系列的分布式的 Java 常用对象,还提供了许
多分布式服务。Redisson 是基于 netty 通信框架实现的,所以支持非阻塞通信,性能相对
于我们熟悉的 Jedis 会好一些。
Redisson 中实现了 Redis 分布式锁,且支持单点模式和集群模式。在集群模式下,
Redisson 使用了 Redlock 算法,避免在 Master 节点崩溃切换到另外一个 Master 时,多
个应用同时获得锁。
我们可以通过一个应用服务获取分布式锁的流程,了解下 Redlock 算法的实现:
在不同的节点上使用单个实例获取锁的方式去获得锁,且每次获取锁都有超时时间,如果请
求超时,则认为该节点不可用。当应用服务成功获取锁的 Redis 节点超过半数(N/2+1,
N 为节点数) 时,并且获取锁消耗的实际时间不超过锁的过期时间,则获取锁成功。
一旦获取锁成功,就会重新计算释放锁的时间,该时间是由原来释放锁的时间减去获取锁所
消耗的时间;而如果获取锁失败,客户端依然会释放获取锁成功的节点。
从实现方式和可靠性来说,Zookeeper 的实现方式简单,且基于分布式集群,可以避免单
点问题,具有比较高的可靠性。因此,在对业务性能要求不是特别高的场景中,我建议使用
Zookeeper 实现的分布式锁。
Redisson 实现的分布式锁
Redis 分布式锁在集群环境下会出现不同应用服务同时获得锁的可能,而Redisson 中的 Redlock 算法很好地解决了这个问题。那 Redisson 实现的分布式锁是不是就一定不会出现同时获得锁的可能呢?
数据库实现分布式锁
数据库实现,select for update是为了放置幻读?是为了同时两个线程走到同一行查询代
码,然后插入两遍的意思吗?那后面的把查询和插入放同一个事务里面的作用是什么?
回复: 是的,这是一个间隙锁,可以防止两个事务插入相同订单号的数据。将查询和插入作为
一个事务,是保证在查询没有订单时,然后才能插入数据。
作者:有雨
链接:https://www.zhihu.com/question/23645117/answer/129505434
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
分布式,一来就直接看书,除非你有比较深厚的技术功底,要不还是很晦涩难懂的。
先想想为什么会有分布式,分布式怎么来的。
传统的电信、银行业,当业务量大了之后,普通服务器CPU/IO/网络到了100%,请求太慢怎么办?最直接的做法,升级硬件,反正也不缺钱,IBM小型机,大型机,采购了堆硬件。
但是互联网不能这么干,互联网没有那么财大气粗,还有很多初创,能不能赚钱还不知道。所以就有了软件方面的解决方案:分布式系统,简单说,就是一台服务器不行,我用两台、10台、100台…这就要软件系统需要支持。那么软件设计者就需要考虑了,那么多台机器,我如何让他们协同工作,这就需要一个调度中心(或注册中心);肯定涉及到机器间通信,那么需要一个高效的RPC框架;一个请求过来了,如何分发,需要一个请求分发系统(负载均衡);然后还要考虑每个角色都不能成为性能瓶颈;还有要能方便的进行横向扩展,还有考虑单节点故障。
这些事你在设计分布式系统需要考虑的问题。笔者现在在互联网行业,说的都是互联网业的方案。比如现在负载均衡用nginx/HA,前者更轻量,后者负载均衡算法更丰富;RPC框架用dubbo(可用当当的dubbox);用zookeeper中注册中心,所有服务注册在这里。
需要分布式系统,并发量肯定不低,那么有了上面的还是不够的,还需要考虑cache、mq、job、db等方面的问题。cache,现在第三方缓存也比较成熟,redis/memcache等;
mq,rabbitmq,kafka等等也不错;
job,现在第三方任务框架有elasticjob和tbschedule,或用quartz也支持分布式环境下的任务,不过quartz没有运维工具。
DB,数据库最好在项目前期就考虑好业务拆分,系统拆分后DB对应的垂直拆分,
后期可做读写分离,一主多从,甚至多主多从,业界也有了相应的解决方案。
总结一下,
楼主要自己了解分布式原理,
然后对应着每个功能区找业界内成熟的产品来实时。
互联网行业,基本都有开源的产品供你选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









