




原理:

1.Client模式
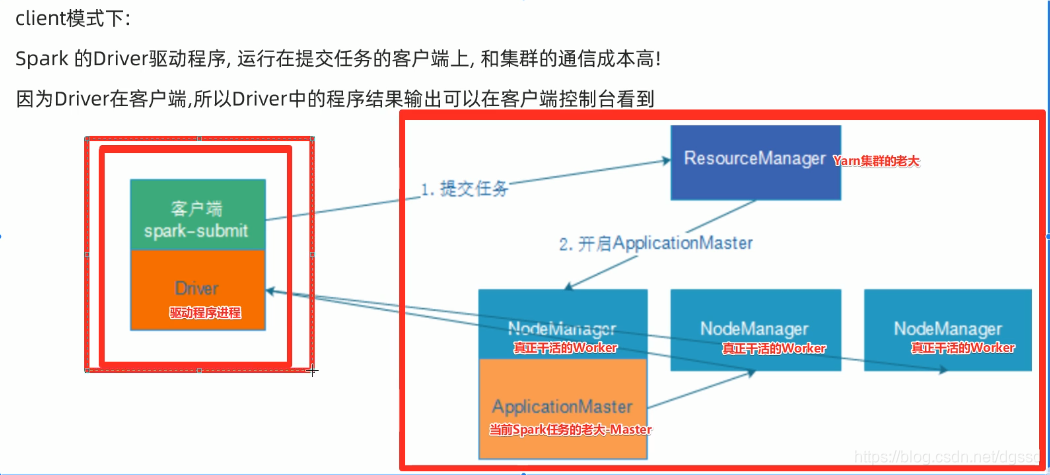
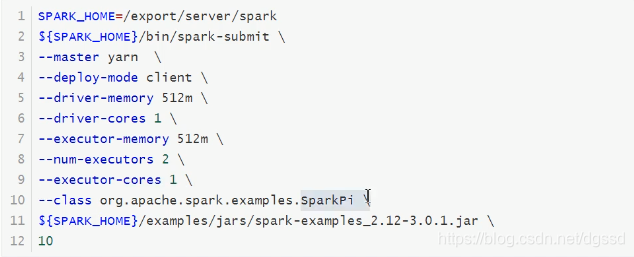

客户端直接显示结果

2.Cluster模式-[开发推荐使用]
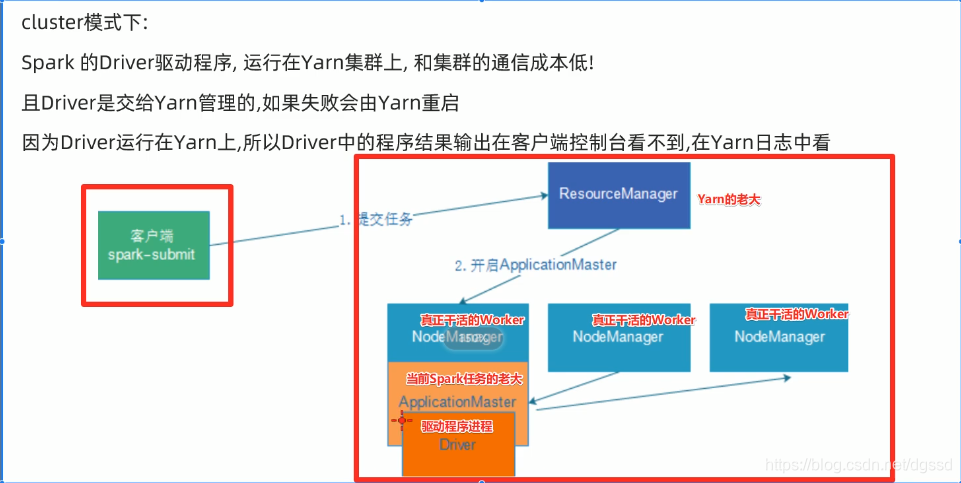
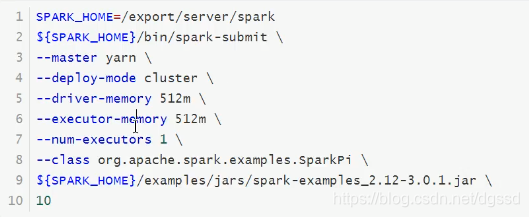
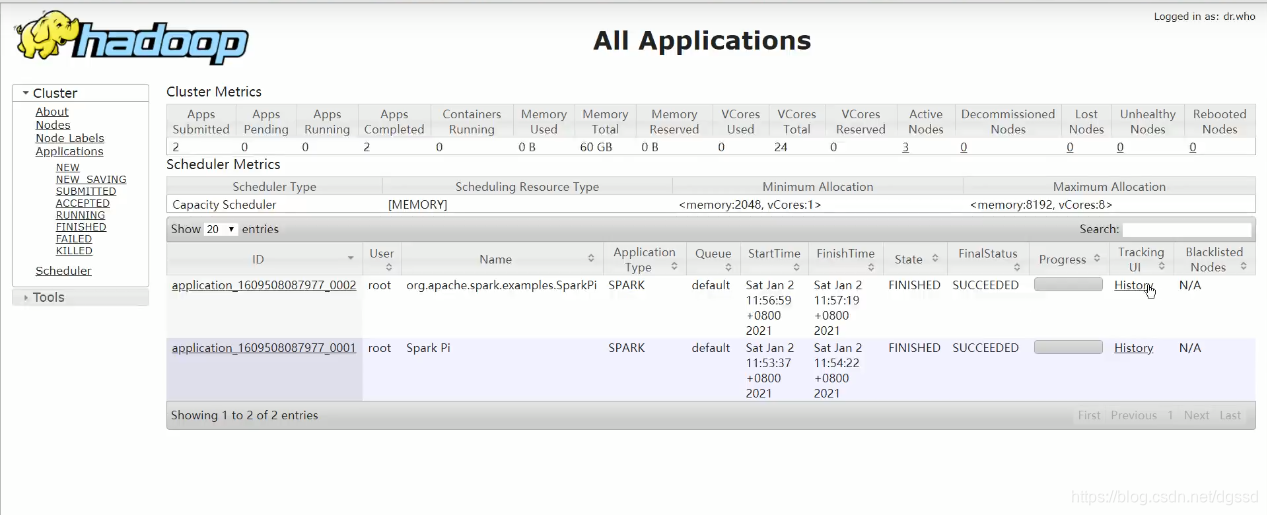
客户端不显示结果
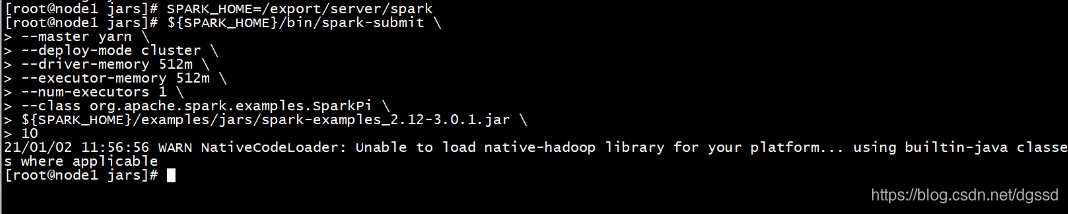
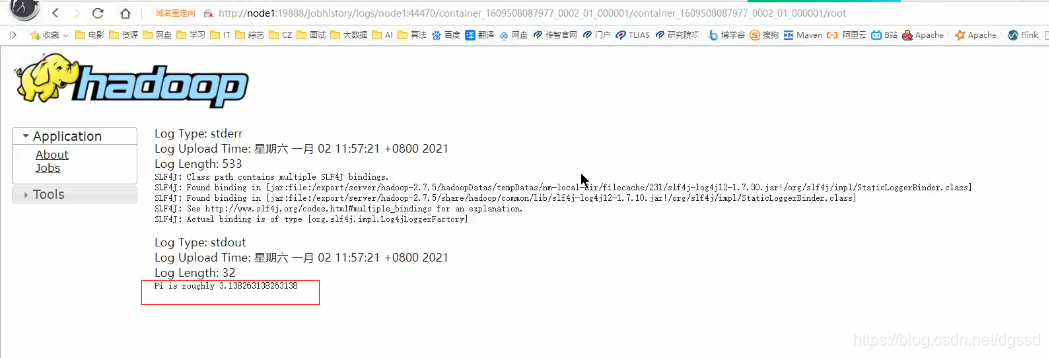
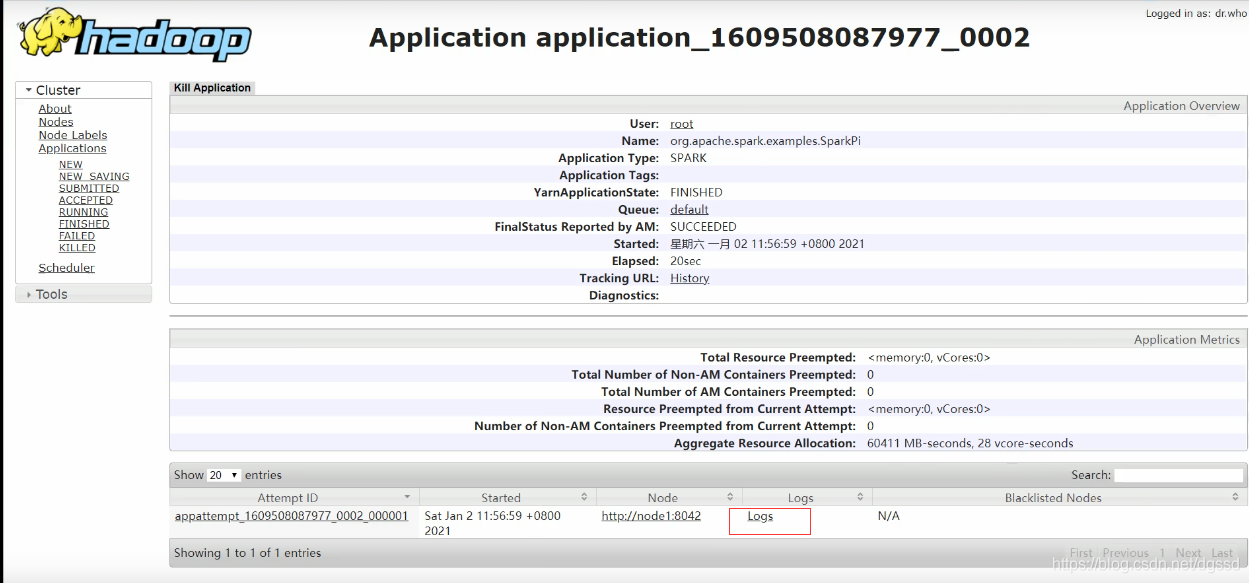
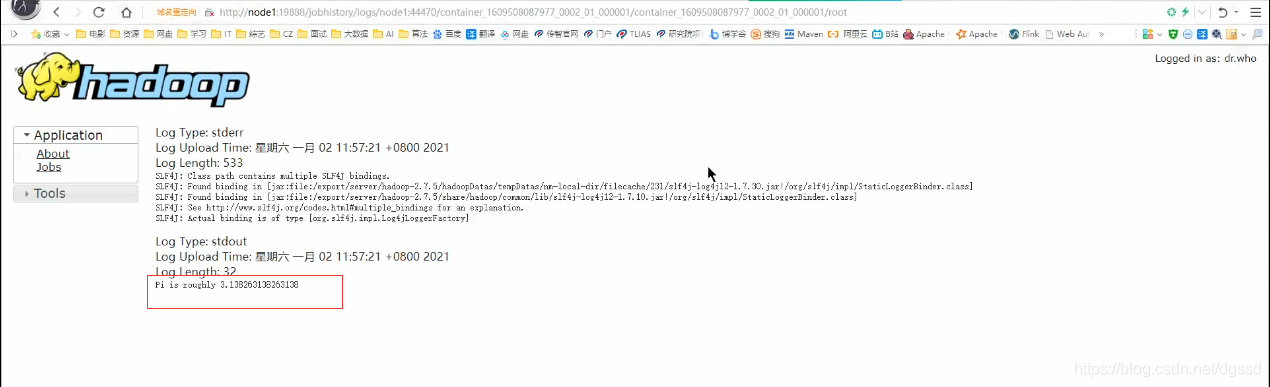
 本文探讨了客户端直显与集群模式在开发中的应用,重点介绍为何推荐Cluster模式,并解释两者在实际项目中的角色。
本文探讨了客户端直显与集群模式在开发中的应用,重点介绍为何推荐Cluster模式,并解释两者在实际项目中的角色。
原理:
1.Client模式
客户端直接显示结果
2.Cluster模式-[开发推荐使用]
客户端不显示结果
 1375
2453
2780
1375
2453
2780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























