



 本文深入解析Elasticsearch中数据的存储机制,包括_source、_all字段的功能与使用场景,以及store属性对字段存储的影响,帮助读者理解如何高效管理和查询数据。
本文深入解析Elasticsearch中数据的存储机制,包括_source、_all字段的功能与使用场景,以及store属性对字段存储的影响,帮助读者理解如何高效管理和查询数据。
首先要明确一份数据在进入es中之后通常是如何存储的
原始文档数据在进入es中之后,es会将其存为两份,一部分是对其中的索引字段数据进行分词索引,然后存储所有的分词索引结果,这个结果并不一定是整个文档数据(通常都指定索引部分字段)。而另一份则是原始文档数据,而该文档的所有的分词索引都会指向该文档。
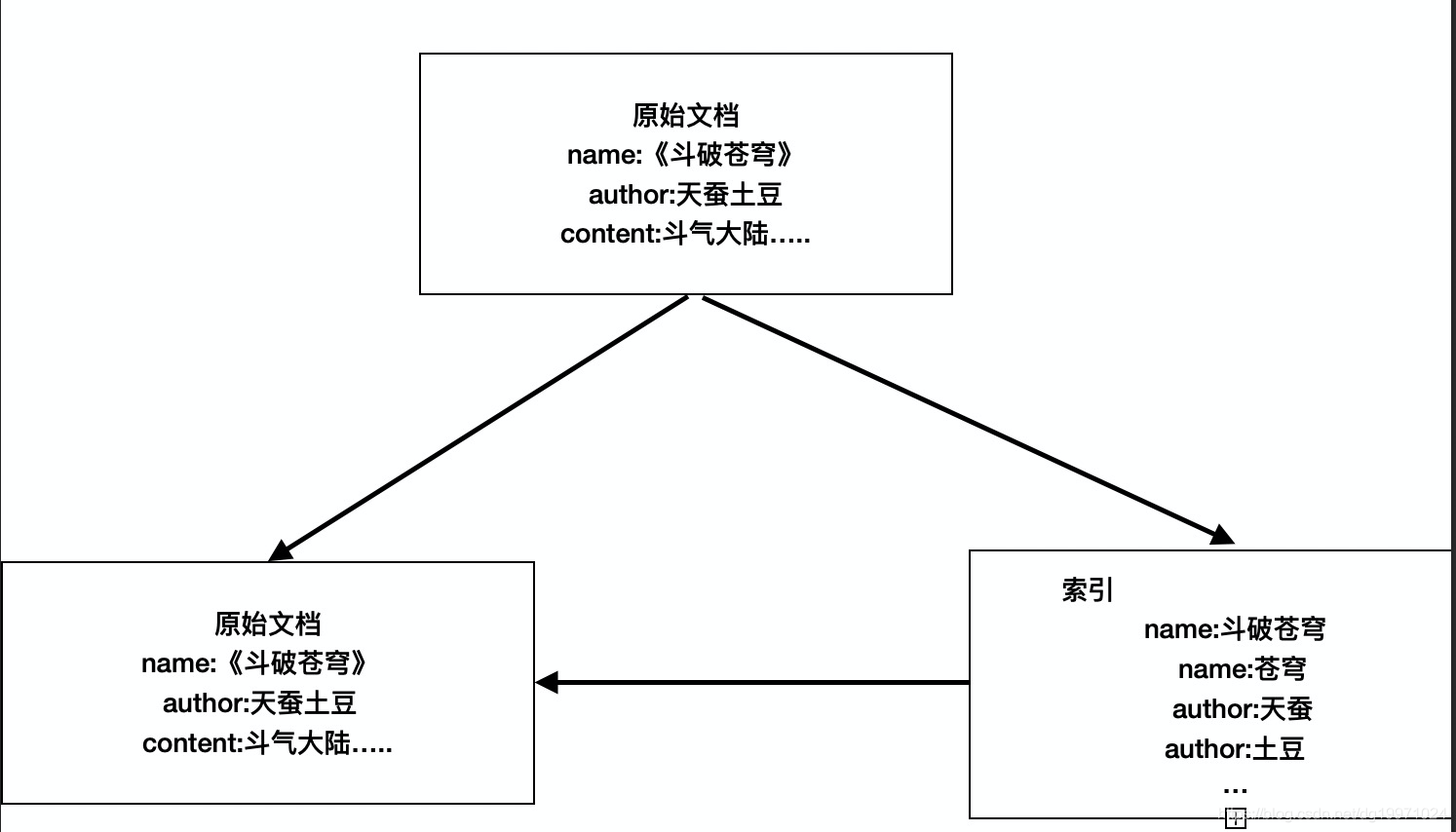
1. _source的作用
_source就是指源文档的存储,你可以理解为是es将你传输的原始文档数据放在了_source字段中存储,该设置是用来控制是否存储源文档数据的,如果将该设置设置为false,那就表示不会存储源文档的数据。会出现的问题就是导致查询的时候无法完整展示所有文档数据,只能看到索引中的数据。在检索数据时,最终检索结果实际上就是_source中的数据。
2._all的作用
与_source类似,_all也是一个字段,同样也是存储了完整的文档数据,但不同的是_all是一个超级字段。以图中的文档为例,如果开启_all字段,那么name+author+content会组成一个超级字段,这个字段包含了其他字段的所有内容,当然也可以设置只存储某几个字段到_all属性里面或者排除某些字段,该字段默认不会被存储,也就是说只会在进行分词索引时存在,分词索引结束后该字段就不会存在,如果要存储该字段,对_all字段开启store属性即可。
_all主要是在当检索内容无法确定是在哪个字段上的时候,比较适合开启该字段。
3.文档对象中设置字段的store属性作用
@Document(indexName = "item",type = "docs", shards = 1, replicas = 0)
public class Item {
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word", store = false)
private String title; //标题
@Field(type = FieldType.Keyword)
private String category;// 分类
@Field(type = FieldType.Keyword)
private String brand; // 品牌
@Field(type = FieldType.Double)
private Double price; // 价格
@Field(index = false, type = FieldType.Keyword)
private String images; // 图片地址
public Item() {
}
}
store属性设置作用于文档中的某个字段之上,表示是否开启索引字段原数据存储,其实简单来理解就是将_source的范围缩小为某个属性字段,设置为true后,es会将该属性字段的原数据额外单独存储一份,即该字段的原数据会存储两份,一份是在原始文档,另一份则是单独该字段的存储。这也是为什么es的API中默认将该属性设为false,因为其与_source字段重复存储了同一部分数据。
_source和store两个设置任意为true都能够对字段实现高亮查询,因为高亮查询必须保证原字段数据的存储,才能进行高亮查询。
通常不建议开启该属性,store属性和_source字段两个设置同时开启会存储重复数据。而且当通过索引检索时,检索的结果中如果包含store属性字段,该store属性字段的内容不会从原始文档中读取,而是额外进行一次IO,读取该字段的单独存储的文档,所以会损失部分性能。
总结:
(1)_source和_all其实都是两个字段,只不过区别是_source是存储的结构化的原始文档,而_all是存储的是一个所有field字段拼接而成的字符串,两者是有区别的。
(2)store是作用于field(字段)上的属性,决定该field是否单独存储一份文档,该属性可以作用于_all字段上,但与_source字段重复。

















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









