







最新案例动态,请查阅【案例共创】线性分类器与支持向量机 - 新闻标题主题分类(SVM)。小伙伴们快来领取华为开发者空间进行实操吧!
本案例由:梅科尔工作室提供
1 概述
1.1 案例介绍
在机器学习领域,分类的目标是指将具有相似特征的对象聚集。而一个线性分类器则透过特征的线性组合来做出分类决定,以达到此种目的。
支持向量机(Support Vector Machine, SVM)是一种广泛应用于机器学习的监督学习模型,主要用于分类和回归任务。其核心思想是通过寻找一个最优超平面,将不同类别的样本分开,并最大化类别之间的间隔。
本案例通过在开发者空间Notebook中,基于SVM并使用MindSpore框架进行数据预处理和词向量训练,对新闻标题进行预测分类。
通过本案例可以对线性分类器与⽀持向量机进行学习,同时了解MindSpore框架的使用。
1.2 适用对象
-
企业
-
个人开发者
-
高校学生
1.3 案例时间
本案例总时长预计30分钟。
1.4 案例流程
说明:
-
登录开发者空间,启动Notebook;
-
在Notebook中编写代码运行调试。
1.5 资源总览
本案例预计花费总计0元。
NPU basic · 1 * NPU 910B · 8v CPU · 24GB
euler2.9-py310-torch2.1.0-cann8.0-openmind0.9.1-notebook
免费 302 资源与开发环境准备
2.1 启动Notebook
参考“DeepSeek模型API调用及参数调试(开发者空间Notebook版)”案例的第2.2章节启动Notebook。
2.2 安装依赖库
在Notebook的新执行框中输入如下代码并运行,安装所有依赖库。
!pip install --upgrade pip setuptools wheel
!pip install numpy
!pip install mindspore
!pip install jieba
!pip install scikit-learn
!pip install joblib
!pip install pandas
!pip install gensim
3 新闻标题主题分类
- 导入必要的库
-
jieba:用于中文文本的分词处理。
-
numpy (np):用于数值计算和数组操作。
-
pandas (pd):用于数据处理和分析。
-
subprocess:用于执行系统命令,例如下载数据集。
-
mindspore:深度学习框架,用于构建和训练模型。
-
gensim.models.word2vec.Word2Vec:用于训练词向量模型。
-
sklearn.model_selection.train_test_split:用于划分训练集和测试集。
-
sklearn.metrics.accuracy_score, classification_report:用于评估模型性能。
-
joblib:用于保存和加载模型。
在Notebook的新执行框中输入如下代码并运行,导入所有使用到的库。
import jieba
import numpy as np
import pandas as pd
import subprocess
import mindspore as ms
from mindspore import Tensor, nn, ops
from mindspore.dataset import GeneratorDataset
from gensim.models.word2vec import Word2Vec
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import joblib
3.1 下载数据集
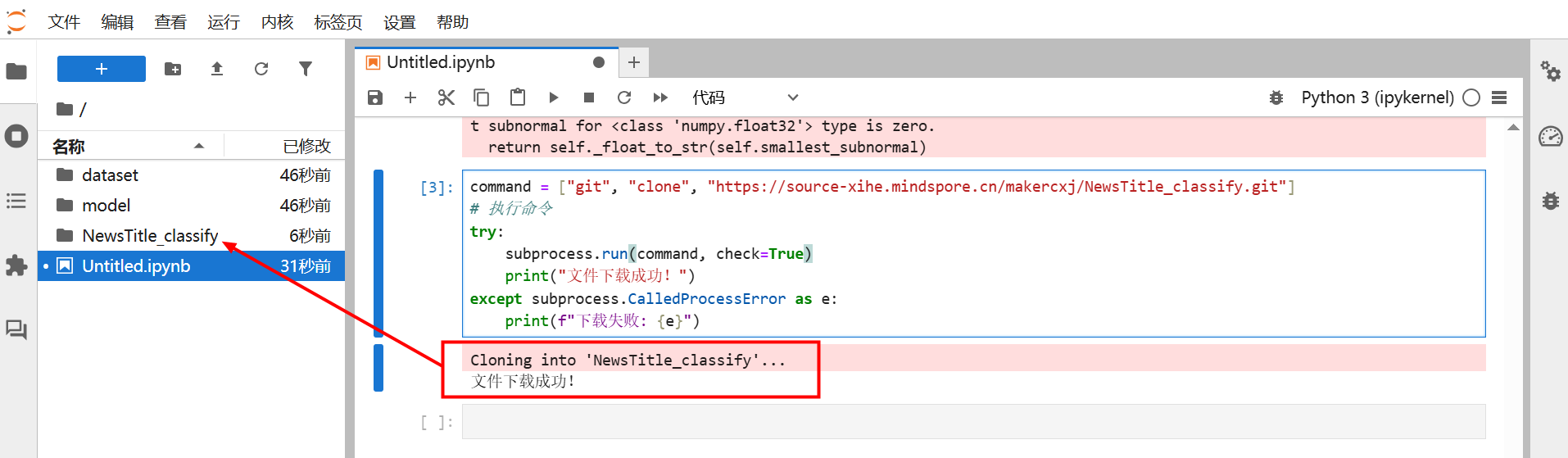
使用Git命令从远程仓库下载新闻标题分类的数据集。如果下载成功,打印“文件下载成功!”;如果失败,打印错误信息。
在Notebook的新执行框中输入如下代码并运行:
command = ["git", "clone", "https://source-xihe.mindspore.cn/makercxj/NewsTitle_classify.git"]
# 执行命令
try:
subprocess.run(command, check=True)
print("文件下载成功!")
except subprocess.CalledProcessError as e:
print(f"下载失败: {e}")
3.2 加载数据
使用Pandas读取两个文本文件,一个是文化体育类新闻标题(正类),另一个是生态环境类新
闻标题(负类)。
在Notebook的新执行框中输入如下代码并运行:
pos = pd.read_csv('NewsTitle_classify/culture_title.txt', encoding='UTF-8', header=None)
neg = pd.read_csv('NewsTitle_classify/nature_title.txt', encoding='UTF-8',header=None)
3.3 数据预处理
对每个新闻标题进行分词处理,将标题切分成一个个的词。
在Notebook的新执行框中输入如下代码并运行:
pos['words'] = pos[0].apply(lambda x: jieba.lcut(x))
neg['words'] = neg[0].apply(lambda x: jieba.lcut(x))
合并数据和标签
将正类和负类的分词结果合并为一个数组x,创建标签数组y,正类标签为1,负类标签为0。
在Notebook的新执行框中输入如下代码并运行:
x = np.concatenate((pos['words'], neg['words']))
y = np.concatenate((np.ones(len(pos)), np.zeros(len(neg))))
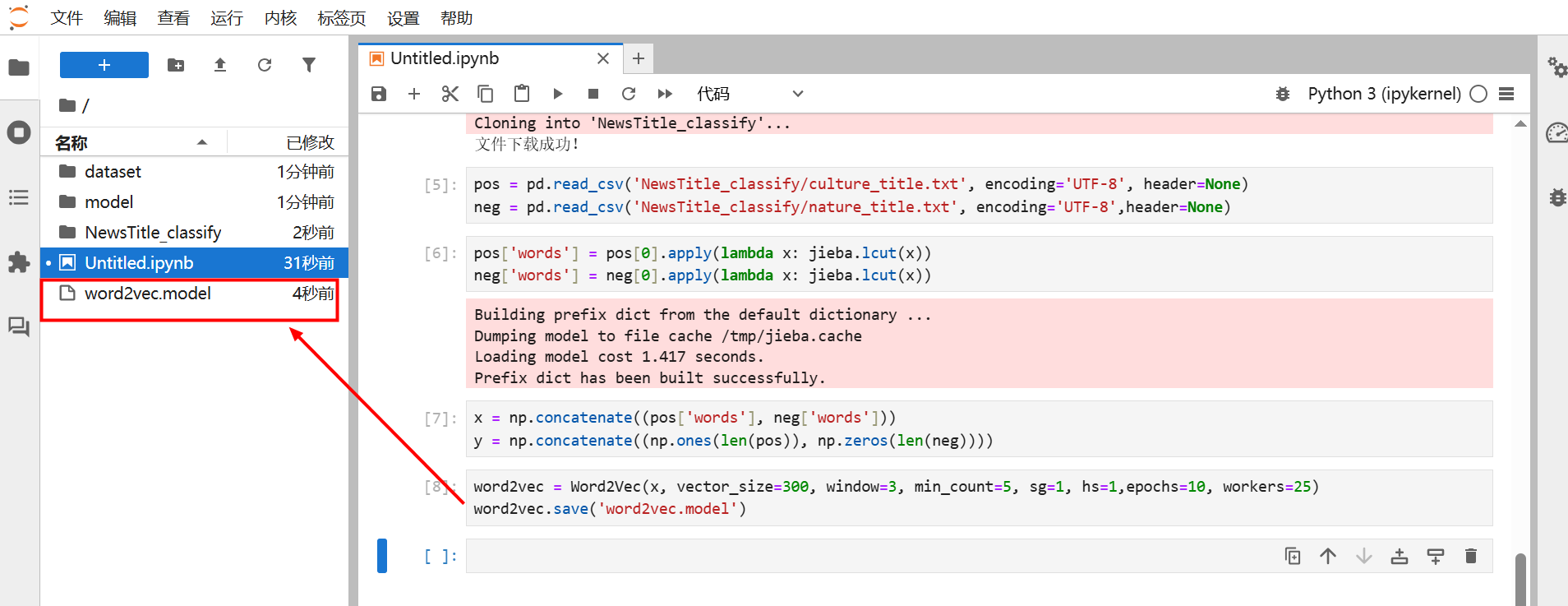
3.4 训练词向量
使用Word2Vec模型训练词向量,将每个词映射到300维的向量空间,并保存训练好的词向量模型。
在Notebook的新执行框中输入如下代码并运行:
word2vec = Word2Vec(x, vector_size=300, window=3, min_count=5, sg=1, hs=1,epochs=10, workers=25)
word2vec.save('word2vec.model')
3.5 定义函数将词向量转换为特征向量
定义函数total_vector ,将每个新闻标题的词向量相加,得到一个固定长度的特征向量。
在Notebook的新执行框中输入如下代码并运行:
def total_vector(words):
vec = np.zeros(300)
for word in words:
try:
vec += word2vec.wv[word]
except KeyError:
continue
return vec
3.6 生成训练数据的特征向量
将所有新闻标题转换为特征向量,形成训练数据。
在Notebook的新执行框中输入如下代码并运行:
train_vec = np.array([total_vector(words) for words in x])
3.7 划分训练集和测试集
将数据集划分为训练集和测试集,测试集占20%。
在Notebook的新执行框中输入如下代码并运行:
X_train, X_test, y_train, y_test = train_test_split(train_vec, y,test_size=0.2, random_state=42)
3.8 转换为MindSpore tensor
将NumPy数组转换为MindSpore的Tensor,以便在MindSpore框架中使用。
在Notebook的新执行框中输入如下代码并运行:
X_train_ms = Tensor(X_train, dtype=ms.float32)
y_train_ms = Tensor(y_train, dtype=ms.float32)
X_test_ms = Tensor(X_test, dtype=ms.float32)
y_test_ms = Tensor(y_test, dtype=ms.float32)
3.9 定义SVM模型(使用逻辑回归替代)
定义一个简单的线性模型,用于二分类任务。
在Notebook的新执行框中输入如下代码并运行:
class SVM(nn.Cell):
def __init__(self, input_size):
super(SVM, self).__init__()
self.linear = nn.Dense(input_size, 1)
def construct(self, x):
return self.linear(x)
3.10 初始化模型、损失函数和优化器
初始化模型、二分类交叉熵损失函数和Adam优化器。
在Notebook的新执行框中输入如下代码并运行:
model = SVM(300)
loss_fn = nn.BCEWithLogitsLoss()
optimizer = nn.Adam(model.trainable_params(), learning_rate=0.001)
3.11 定义训练网络
使用MindSpore的WithLossCell 和TrainOneStepCell 构建训练网络。
在Notebook的新执行框中输入如下代码并运行:
net_with_loss = nn.WithLossCell(model, loss_fn)
train_net = nn.TrainOneStepCell(net_with_loss, optimizer)
3.12 训练模型
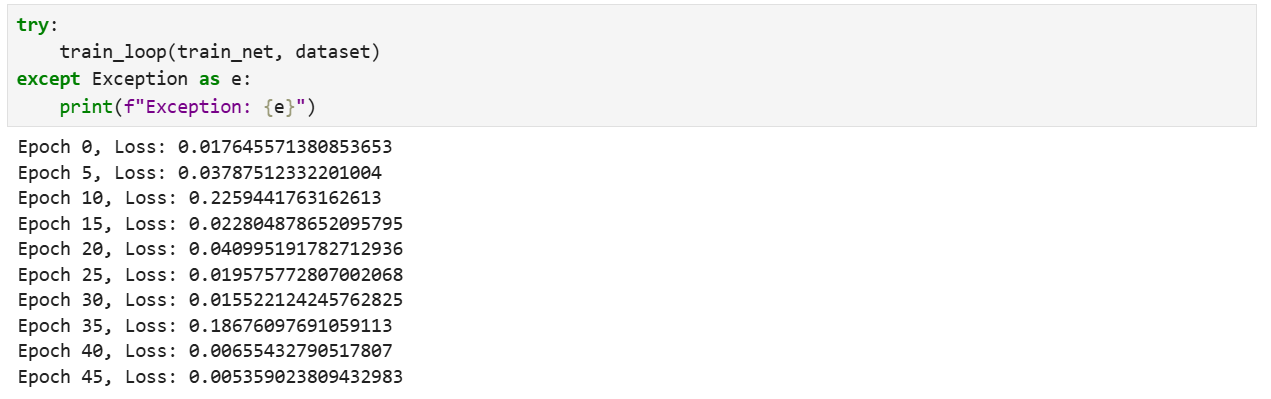
定义训练循环,训练模型50个epoch,并每5个epoch打印一次损失值。
在Notebook的新执行框中输入如下代码并运行:
def train_loop(train_net, dataset):
model.set_train()
for epoch in range(50):
for data, label in dataset:
label = label.view(-1, 1)
loss = train_net(data, label)
if epoch % 5 == 0:
print(f"Epoch {epoch}, Loss: {loss.asnumpy()}")
3.13 创建数据集
使用MindSpore的GeneratorDataset 创建数据集,并设置批量大小为32。
在Notebook的新执行框中输入如下代码并运行:
dataset = GeneratorDataset(list(zip(X_train_ms, y_train_ms)), ['data','label'])
dataset = dataset.batch(32)
3.14 训练模型
调用训练函数,开始训练模型。
在Notebook的新执行框中输入如下代码并运行:
try:
train_loop(train_net, dataset)
except Exception as e:
print(f"Exception: {e}")
训练结果打印如下(每次运行结果不尽相同,内容仅作参考):
3.15 在测试集上评估模型
将模型设置为评估模式,对测试集进行预测,并计算准确率和分类报告。
在Notebook的新执行框中输入如下代码并运行:
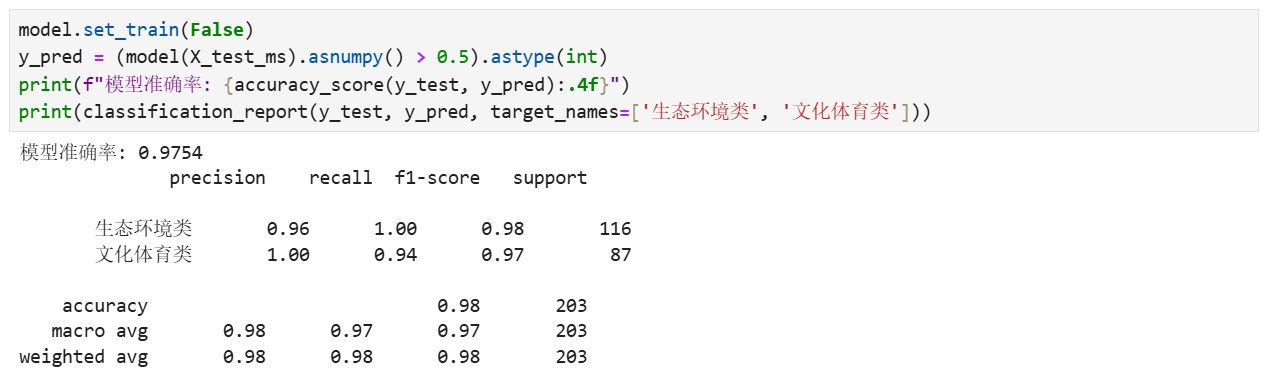
model.set_train(False)
y_pred = (model(X_test_ms).asnumpy() 0.5).astype(int)
print(f"模型准确率: {accuracy_score(y_test, y_pred):.4f}")
print(classification_report(y_test, y_pred, target_names=['生态环境类', '文化体育类']))
评估结果参考如下(每次运行结果不尽相同,内容仅作参考):
3.16 定义预测函数
定义预测函数,对新输入的文本进行分类预测。
在Notebook的新执行框中输入如下代码并运行:
def svm_predict(query):
words = jieba.lcut(query)
vec = total_vector(words)
vec_ms = Tensor(vec.reshape(1, -1), dtype=ms.float32)
result = (model(vec_ms).asnumpy() 0.5).astype(int)
proba = ops.Sigmoid()(model(vec_ms)).asnumpy()[0][0]
if int(result) == 1:
print(f'类别:文化体育类 (概率: {proba:.4f})')
else:
print(f'类别:生态环境类 (概率: {1 - proba:.4f})')
3.17 测试预测
测试两个示例文本的分类结果。
在Notebook的新执行框中输入如下代码并运行:
svm_predict('文化体育融合新发展,全民共享健康生活')
svm_predict('生态修复与保护加速推进,绿色发展绘就美丽未来')
测试结果参考如下(每次运行结果不尽相同,内容仅作参考):

4 总结
根据上述训练预测结果,总结如下:
4.1 模型性能
-
模型在测试集上的准确率达到97.54%,表明模型具有很高的分类准确性。
-
分类报告显示,模型对两个类别的精确度(precision)、召回率(recall)和F1分数都非常高。
4.2 预测能力
模型能够对新的新闻标题进行准确分类,并给出分类的概率值。例如:
- 对于标题“文化体育融合新发展,全民共享健康生活”,模型预测其属于“文化体育类”,
概率为0.8426。
- 对于标题“生态修复与保护加速推进,绿色发展绘就美丽未来”,模型预测其属于“生态环
境类”,概率为0.9994。
4.3 模型保存与部署
-
保存训练好的词向量模型,便于后续的应用和部署。
-
MindSpore提供了丰富的工具和模块,支持模型的进一步优化和部署。
至此,新闻标题主题分类案例结束。点击链接参考完整案例代码。


















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









