



 文章对比了四种视觉定位服务,包括AzureSpatialAnchor、VuforiaAreaTarget、Immersal和ARWAY,详细阐述了每种技术的扫描方式、AR内容创建流程、一致性保持方法以及各自的特点和局限性。Azure依赖自定义扫描,Vuforia使用LiDER,Immersal基于空间照片,而ARWAY则在网络工具上开发AR内容。
文章对比了四种视觉定位服务,包括AzureSpatialAnchor、VuforiaAreaTarget、Immersal和ARWAY,详细阐述了每种技术的扫描方式、AR内容创建流程、一致性保持方法以及各自的特点和局限性。Azure依赖自定义扫描,Vuforia使用LiDER,Immersal基于空间照片,而ARWAY则在网络工具上开发AR内容。
起先
您是否听说过一种称为VPS(视觉定位服务/系统)的技术?
简而言之,它是一种AR技术,通过将相机图像与扫描的空间信息相匹配来对齐虚拟和真实空间。
VPS 要求您使用准备好或自行准备的扫描仪应用程序提前扫描空间信息。
此外,恒定对齐的方法因VPS而异。
这一次,我实际上运行了 4 个 VPS,并在 4 个项目中比较了它们。
1. 如何
扫描 如何创建
AR 内容 2. 如何保持一致?
3. 印象
Azure Spatial Anchor
在过去的文章中,我们已经总结了 Azure 空间定位点的验证结果。
[参考链接]:我触摸了
Azure 空间定位点 [参考链接]:我验证了 Azure 空间定位点的准确性
我们公司开发的CFA也使用Azure空间定位点。
1. 如何扫描
Azure 空间定位点可以在空间中注册称为空间定位点的内容。
注册空间定位点所需的空间上限是距离该点几米,大约 360 度。
至于 ASA,没有扫描应用程序,
您需要实现自己的扫描应用程序来放置空间定位点。
2. 如何创建 AR 内容
在 Unity 编辑器中,提前在预制件中准备“要放置在空间定位点 (0,0,0) 处的对象”。
通过将AR对象放置在其下方,可以相对于锚点放置AR对象。
下图是一个实际示例。
通过实现上述预制件(主锚点),以便将其放置在读取的空间定位点的位置,
其下的立方体将显示在空间定位点的顶部。
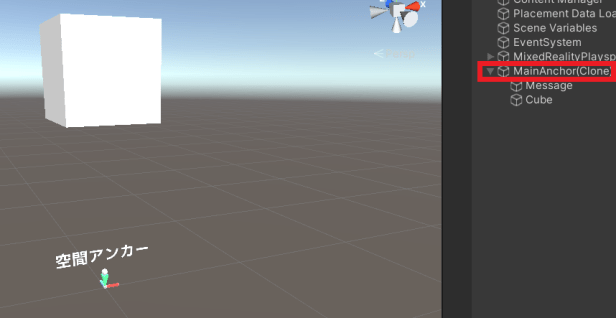
在 Unity 编辑器中完成此操作后,
将其部署到真实设备以探索空间定位点并定位 AR 对象。
(要找到定位点,您需要用相机环顾空间。 如果您
有任何疑问,请在 Unity 编辑器中再次调整它们... 这就是流程。
3. 如何保持一致?
一定程度的自我定位总是会完成的。
因此,当移动大约几米时,空间锚点很少移动。
如果空间锚点移动,放置在其下方的AR对象也会自然移动。
因此,如果AR对象明显偏离预期位置,
则需要重新搜索空间定位点。
这会强制用户环顾注册为空间定位点的空间。
换句话说,考虑到 Azure 空间定位点移出空间定位点周围几米的空间,
因此很难继续准确对齐。
4. 印象
由于单个锚点要注册的空间范围不是很大,因此支持大范围有些困难。
另一方面,由于它是微软提供的服务,因此它与HoloLens 2兼容。
由于自我定位可以在比使用移动设备
时稍宽的范围内保持,因此上述弱点可能会有所缓解。
武福里亚地区目标
Vuforia Area Target 通过在应用程序中放置包含预扫描特征点数据的
3D 数据(以下简称 3D 数据),将 3D 数据与空间进行比较和对齐。
1. 如何扫描
Vuforia Area Target 需要使用专用应用程序扫描空间。
(作为前提,扫描应用程序只能在带有LiDER的设备上运行。
扫描并不困难。
只需走路,同时将设备的摄像头对准您想要慢慢 3D 的空间。
每个区域可以预扫描和创建的 1D 数据量是有限制的。
由于数据是在设备的内存上扩展的,因此目前大约 3 分钟的缓慢行走似乎是极限。
但是,可以组合多个扫描的空间5D数据以扩大范围。
2. 如何创建 AR 内容
扫描的数据可以带到 Unity。
实际输出为扫描结果的3D数据如下所示。

在 Unity 编辑器中,如果将 AR 对象放置在该对象(网格)下,将其部署到
实际设备并识别空间,则 AR 对象将出现在任何位置。
3. 如何保持一致?
如果AR对象明显偏离预期位置,
只需将扫描空间投影到相机上并重新对齐即可。
开发人员无需显式调用对齐过程。
如果您为您的内容准备了 Vuforia 提供的适当组件,他们将在内部完成。
只要相机上显示预扫描的空间,就可以继续精确对准。
■印象
由于使用了LiDER,因此网格的精度很高。
另一方面,由于使用了LiDER,因此不适合对远视图进行网格划分。
可以说,它是一款功能强大的室内VPS。
沉浸式
在过去的文章中,我们已经总结了Immersal的验证结果。
[参考链接]:从样品中浸入解开 【参考链接】:Immersal
1. 如何扫描
Immersal使用专用的应用程序来绘制空间。
地图是连续数量的空间照片,并转换为点云信息。
根据地图的大小,您可能需要拍摄相当多的照片。
此外,地图的准确性在很大程度上取决于拍摄环境和方法。
与其他VPS相比,它需要学习将空间数据转换为数据。

下图是上图中区域的地图。

在此地图数据的同时,还创建了 GLB 格式的网格。
2. 如何创建 AR 内容
在 Unity 编辑器中加载地图数据时,要素点云可以展开为爆炸。
这可能会让您了解空间的大致形状,但分层更多 glb 样式的网格将
更容易在 Unity 编辑器中放置 AR 对象。
之后,就像之前的VPS一样,如果你将其部署到实际设备上并识别空间,
AR对象就会出现在任何地方。
3. 如何保持一致?
沉浸式自我定位依赖于AR基础。
因此,如果移动几米,真实空间和虚拟空间将不可避免地分开。
作为对策,Immersal实现了一个功能,使它们在指定的时间周期内保持一致。
如果相机投射的空间是地图数据数据的一部分,
AR对象的错位将立即得到纠正。
4. 印象
虽然设置了每张地图的最大拍摄次数,但可以准备和连接多个地图,
因此可以创建广域AR内容。
实际上,在某些情况下,已经绘制了整个1,1,000平方米(000平方米)的城市,因此可以说它是广阔区域内的强大VPS。
阿威
ARWAY是一个VPS,具有在网络上运行的AR内容开发工具。
您可以做的事情仍然有很多限制,但它非常强大,值得一看。
1. 如何扫描
与Immersal一样,使用专用应用程序来绘制空间。
与Immersal的不同之处在于,您不拍照,但只需将终端相机放在空间上即可生成地图。
但是,它似乎只能在支持 ARKit 和 ARCore 深度 API 的终端上保证正常运行。

与Vuforia Area Target和Immersal不同,似乎没有用于可见性的网格。
仅生成要素点云。
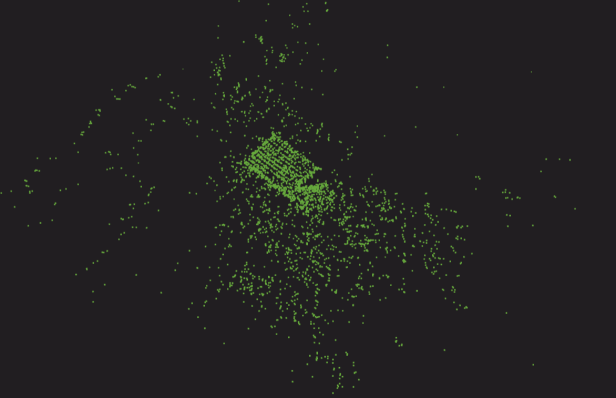
2 . 如何创建 AR 内容
内容创建是通过在名为WebStadio的浏览器上运行的工具完成的。
您可以将自己的图纸带到WebStadio。
当然,您需要准备自己的图纸,但是您可以在想象
实际空间的同时继续开发,同时对齐图纸和点云,如下所示。
我们将AR对象放置在工具上,
默认情况下准备了用于指南导航的模型。
您还可以导入自己的 glb 格式的 3D 模型。
动画、粒子等目前不可用。
之后,将引入ARWAY的SDK的Unity项目部署到实际设备中。
当您启动应用程序时,它将开始下载在WebStadio中编辑的地图。
下载后,如果您识别出空间,AR对象将出现在任何地方。
以下是到目前为止的流程图示。
【来源】:https://docs.arway.app/#components
3. 如何保持一致?
自我定位的机制与Immersal相同。
因此,如果移动几米,真实空间和虚拟空间将不可避免地分开。
与 Immersal 不同,没有保持对齐的功能,
因此如果在空间反射到相机上时显式继续调用对齐过程(例如每 n 秒调用一次),
则可以继续精确对齐。
4. 印象
ARWAY还有一个SDK,其中包含Azure空间定位点的功能,虽然我不知道它是如何工作的,
但它在对齐中实现了很高的识别准确性。
它具有在广泛领域使用的潜力,
因此如果WebStadio的功能得到扩展,它将成为更强大的工具。

















 2021
2021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









